Through the work of my students
Rupesh Kumar Srivastava and Klaus Greff,
the LSTM principle also led to
our Highway Network[HW1] of May 2015, the first working very deep FNN with hundreds of layers (previous NNs had at most a few tens of layers). Microsoft's ResNet[HW2] (which won the
ImageNet 2015 contest) is a version thereof
(ResNets are Highway Nets whose gates are always open).
The earlier Highway Nets perform roughly as well as their ResNet versions on ImageNet.[HW3]
Variants of highway gates are also used for certain algorithmic tasks where the pure residual layers do not work as well.[NDR]
Deep learning
is all about NN depth.[DL1]
In the 1990s,
LSTMs
brought essentially unlimited depth to supervised recurrent NNs; in the 2000s, the LSTM-inspired Highway Nets brought it to feedforward NNs. LSTM has become the most cited NN of the 20th century; the Highway Net version called ResNet the most cited NN of the 21st.[MOST] (Citations, however, are a highly questionable measure of true impact.[NAT1])
The previous sections have mostly focused on deep learning for passive pattern recognition/classification. However, NNs are also relevant for
Reinforcement Learning (RL),[KAE96][BER96][TD3][UNI][GM3][LSTMPG]
the most general type of learning. General RL agents must discover, without the aid of a teacher, how to interact with a dynamic, initially unknown, partially observable environment in order to maximize their expected cumulative reward signals.[DL1]
There may be arbitrary, a priori unknown delays between actions and perceivable consequences. The RL problem is as hard as any problem of computer science, since any task with a computable description can be formulated in the general RL framework.[UNI]
Certain RL problems can be addressed through non-neural techniques invented long before the 1980s:
Monte Carlo (tree) search (MC, 1949),[MOC1-5]
dynamic programming (DP, 1953),[BEL53]
artificial evolution (1954),[EVO1-7]([TUR1],unpublished)
alpha-beta-pruning (1959),[S59]
control theory and system identification (1950s),[KAL59][GLA85]
stochastic gradient descent (SGD, 1951),[STO51-52]
and universal search techniques (1973).[AIT7]
Deep FNNs and RNNs, however, are useful tools for improving certain types of RL.
In the 1980s, concepts of function approximation and NNs were combined with
system identification,[WER87-89][MUN87][NGU89]
DP and its online variant called Temporal Differences (TD),[TD1-3]
artificial evolution,[EVONN1-3]
and policy gradients.[GD1][PG1-3]
Many additional references on this can be found in Sec. 6 of the 2015 survey.[DL1]
When there is a Markovian interface[PLAN3]
to the environment such that the current input to the RL machine conveys all the information required to determine a next optimal action, RL with DP/TD/MC-based FNNs can be very successful, as shown in 1994[TD2] (master-level backgammon player) and the 2010s[DM1-2a] (superhuman players for Go, chess, and other games).
For more complex cases without Markovian interfaces, where the learning machine must consider not only the present input, but also the history of previous inputs, our combinations of RL algorithms and LSTM[LSTM-RL][RPG] have become standard, in particular, our
LSTM trained by policy gradients (2007).[RPG07][RPG][LSTMPG]

For example, in 2018, a PG-trained LSTM was the core of OpenAI's famous Dactyl which learned to control a dextrous robot hand without a teacher.[OAI1][OAI1a]
Similar for video games: in 2019, DeepMind (co-founded by a student from my lab) famously
beat a pro player in the game of Starcraft, which is theoretically harder than Chess or Go[DM2] in many ways, using
Alphastar whose brain has a deep LSTM core trained by PG.[DM3]
An RL LSTM (with 84% of the model's total parameter count) also was the core of the famous
OpenAI Five
which learned to defeat human experts in the Dota 2 video game (2018).[OAI2]
Bill Gates called this a "huge milestone in advancing artificial intelligence".[OAI2a][MIR](Sec. 4)[LSTMPG]
The future of RL will be about learning/composing/planning with compact spatio-temporal abstractions of complex input streams—about commonsense reasoning[MAR15] and learning to think.[PLAN4-5]
How can NNs learn to represent percepts and action plans in a hierarchical manner, at multiple levels of abstraction, and multiple time scales?[LEC] We published answers to these questions in 1990-91: self-supervised
neural history compressors[UN][UN0-3] learn to represent percepts at multiple levels of abstraction and multiple time scales (see above), while
end-to-end differentiable NN-based subgoal generators[HRL3][MIR](Sec. 10) learn hierarchical action plans through gradient descent (see above). More sophisticated ways of learning to think in abstract ways were published in
1997[AC97][AC99][AC02] and 2015-18.[PLAN4-5]
The recent breakthroughs of deep learning algorithms from the past millennium (see previous sections) would have been impossible without continually improving and accelerating computer hardware. Any history of AI and deep learning would be incomplete without mentioning this evolution, which has been running for at least two millennia.
The first known gear-based computational device was the
Antikythera mechanism (a kind of astronomical clock) in Ancient Greece over 2000 years ago.
Perhaps the world's first practical
programmable machine was an automatic theatre made in the 1st
century[SHA7a][RAU1] by Heron of Alexandria
(who apparently also had the first known working steam engine—the Aeolipile).

The 9th century
music automaton
by the Banu Musa brothers in Baghdad
was perhaps the first machine with a stored program.[BAN][KOE1] It used pins on
a revolving cylinder to store programs controlling a steam-driven
flute—compare Al-Jazari's programmable drum machine of 1206.[SHA7b]

The 1600s brought more flexible machines that computed answers in response to input data.
The first data-processing gear-based special purpose calculator for simple arithmetics was built in 1623 by
Wilhelm Schickard,
one of the candidates for the title of
"father of automatic computing," followed by the
superior Pascaline of Blaise Pascal (1642).
In 1673, the already mentioned Gottfried Wilhelm Leibniz (called "the smartest man who ever lived"[SMO13])
designed the first machine (the step reckoner) that could perform all four arithmetic operations, and the first with a memory.[BL16]
He also
described the principles of binary computers governed by punch
cards (1679),[L79][L03][LA14][HO66]
and published the chain rule[LEI07-10] (see above), essential ingredient of deep learning and modern AI.
The first commercial program-controlled
machines (punch card-based looms) were built in France circa
1800 by Joseph-Marie Jacquard and others—perhaps the first "modern"
programmers who wrote the world's first industrial software.
They inspired Ada Lovelace and her mentor
Charles Babbage (UK, circa 1840). He planned but was unable to build a
programmable, general purpose computer (only his non-universal special purpose calculator
led to a working 20th century replica).
 In 1914, the Spaniard
Leonardo Torres y Quevedo (mentioned in the introduction) became
the 20th century's first AI pioneer
when he built
the first working chess end game player
(back then chess was considered as an activity restricted to the realms of intelligent creatures).
The machine was still considered impressive decades later when
another AI pioneer—Norbert Wiener[WI48]—played against
it at the 1951 Paris AI conference.[AI51][BRO21][BRU4]
In 1914, the Spaniard
Leonardo Torres y Quevedo (mentioned in the introduction) became
the 20th century's first AI pioneer
when he built
the first working chess end game player
(back then chess was considered as an activity restricted to the realms of intelligent creatures).
The machine was still considered impressive decades later when
another AI pioneer—Norbert Wiener[WI48]—played against
it at the 1951 Paris AI conference.[AI51][BRO21][BRU4]
Between 1935 and 1941,
Konrad Zuse
created the world's first working programmable general-purpose computer: the Z3.
The corresponding patent of 1936[ZU36-38][RO98][ZUS21]
described the digital circuits required by programmable physical hardware,
predating Claude Shannon's 1937 thesis on digital circuit design.[SHA37]
Unlike Babbage, Zuse used Leibniz'
principles of binary computation (1679)[L79][LA14][HO66][L03]
instead of traditional
decimal computation.
This greatly simplified the hardware.[LEI21,a,b]
Ignoring the inevitable storage limitations of any physical computer,
the physical hardware of Z3 was indeed
universal in the modern sense of
the purely theoretical but impractical constructs of
Gödel[GOD][GOD34,21,21a] (1931-34),
Church[CHU] (1935),
Turing[TUR] (1936), and Post[POS] (1936).
Simple arithmetic tricks
can compensate for Z3's lack of an explicit
conditional jump instruction.[RO98]
Today, most computers are binary like Z3.

Z3 used
electromagnetic relays with visibly moving switches.
The first electronic special purpose calculator
(whose moving parts were electrons too small to see)
was the
binary ABC (US, 1942) by
John Atanasoff (the "father of tube-based computing"[NASC6a]).
Unlike the gear-based machines of the 1600s,
ABC used vaccum tubes—today's machines use the
transistor principle
patented by
Julius Edgar Lilienfeld
in 1925.[LIL1-2]
But unlike Zuse's Z3, ABC was not freely programmable.
Neither was the electronic
Colossus machine by Tommy Flowers (UK, 1943-45)
used to break the Nazi code.[NASC6]
The first general working programmable machine built by
someone other than Zuse (1941)[RO98] was Howard Aiken's decimal MARK I (US, 1944).
The much faster decimal ENIAC by Eckert and Mauchly
(1945/46) was programmed by rewiring it.
Both data and programs were stored in electronic memory
by the "Manchester baby" (Williams, Kilburn & Tootill, UK, 1948)
and the 1948 upgrade of ENIAC, which was reprogrammed by entering numerical instruction codes into read-only memory.[HAI14b]
Since then, computers have become much faster through integrated circuits (ICs).
In 1949, Werner Jacobi at Siemens filed a patent for an IC semiconductor
with several transistors on a common substrate (granted in 1952).[IC49-14]
In 1958, Jack Kilby demonstrated an IC with external wires.
In 1959, Robert Noyce presented a monolithic IC.[IC14]
Since the 1970s, graphics processing units (GPUs)
have been used to speed up computations through parallel processing.
ICs/GPUs of today (2022) contain many billions of transistors (almost all of them of Lilienfeld's 1925 FET type[LIL1-2]).
In 1941, Zuse's Z3 could perform roughly one elementary operation (e.g., an addition) per second. Since then,
every 5 years, compute got 10 times cheaper (note that his law is much older than
Moore's Law which states that the number of transistors[LIL1-2]
per chip doubles every 18 months). As of 2021, 80 years after Z3,
modern computers can execute about 10 million billion instructions per second for the same
(inflation-adjusted) price.
The naive extrapolation of this exponential trend predicts that
the 21st century will see cheap computers with a thousand times the
raw computational power of all human brains combined.[RAW]
Where are the physical limits?
According to Bremermann (1982),[BRE]
a computer of 1 kg of mass and 1 liter of volume can execute at most
1051 operations per second on at most 1032 bits.
The trend above will hit
the Bremermann limit roughly 25 decades after Z3,
circa 2200. However, since there are only 2 x 1030 kg of mass in the solar system,
the trend is bound to break within a few centuries,
since the speed of light will greatly limit the acquisition
of additional mass, e.g., in form of other solar systems,
through a function ploynomial in time,
as previously noted back in 2004.[OOPS2][ZUS21]
Physics seems to dictate that future efficient computational hardware will have to be brain-like, with many compactly placed processors in 3-dimensional space, sparsely connected by many short and few long wires, to minimize total connection cost (even if the "wires" are actually light beams).[DL2] The basic architecture is essentially the one of a deep, sparsely connected, 3-dimensional RNN, and Deep Learning methods for such RNNs are expected to become even much more important than they are today.[DL2]
The core of modern AI and deep learning is mostly based on simple math of recent centuries: calculus/linear algebra/statistics.
Nevertheless, to efficiently implement this core on the modern hardware mentioned in the previous section, and to roll it out for billions of people, lots of software engineering was necessary, based on lots of smart algorithms invented in the past century. There is no room here to mention them all. However, at least I'll list some of the most important highlights of the theory of AI and computer science in general.
In the early 1930s, Gödel founded modern theoretical computer science.[GOD][GOD34][LEI21,21a] He introduced a universal coding language (1931-34).[GOD][GOD34-21a] It was
based on the integers,
and allows for formalizing the operations of any digital computer in axiomatic form.
Gödel used it to represent both data (such as axioms and theorems) and programs[VAR13] (such as proof-generating sequences of operations on the data).
He famously constructed formal statements that talk about the computation of other formal statements—especially self-referential statements which imply that they are not decidable, given a computational theorem prover that systematically enumerates all possible theorems from an enumerable set of axioms. Thus he identified fundamental limits of algorithmic theorem proving, computing, and
any type of computation-based AI.[GOD][BIB3][MIR](Sec. 18)[GOD21,21a]

Like most great scientists,
Gödel built on earlier work.
He combined Georg Cantor's diagonalization trick[CAN]
(which showed in 1891 that there are different types of infinities)
with the foundational work by Gottlob Frege[FRE] (who introduced the first formal language in 1879),
Thoralf Skolem[SKO23] (who introduced primitive recursive functions in 1923) and Jacques Herbrand[GOD86] (who identified
limitations of Skolem's approach).
These authors in turn built on
the formal Algebra of Thought (1686) by
Gottfried Wilhelm Leibniz[L86][WI48] (see above),
which is
deductively equivalent[LE18] to the later
Boolean Algebra of 1847.[BOO]
In 1935, Alonzo Church derived a corollary / extension of Gödel's result by demonstrating that Hilbert & Ackermann's Entscheidungsproblem (decision problem) does not have a general solution.[CHU] To do this, he used his alternative universal coding language called Untyped Lambda Calculus, which forms the basis of the
highly influential programming language LISP.
In 1936, Alan M. Turing
introduced yet another universal model: the
Turing Machine.[TUR] He rederived the above-mentioned result.[CHU][TUR][HIN][GOD21,21a][TUR21][LEI21,21a]
In the same year of 1936, Emil Post published yet another independent universal model of computing.[POS]
Today we know many such models.
Konrad Zuse not only created
the world's first working programmable general-purpose computer,[ZU36-38][RO98][ZUS21]
he also designed Plankalkül,
the first high-level programming language.[BAU][KNU]
He applied it to chess in
1945[KNU]
and to theorem proving
in 1948.[ZU48]
Compare Newell & Simon's later work on theorem proving (1956).[NS56]
Much of early AI in the 1940s-70s was actually about theorem proving
and deduction in Gödel style[GOD][GOD34,21,21a] through expert systems and logic programming.
In 1964, Ray Solomonoff combined Bayesian (actually Laplacian[STI83-85]) probabilistic reasoning and theoretical computer science[GOD][CHU][TUR][POS] to derive a mathematically optimal (but computationally infeasible) way of learning to predict future data from past observations.[AIT1][AIT10] With
Andrej Kolmogorov, he founded the theory of Kolmogorov complexity or algorithmic information theory (AIT),[AIT1-22] going beyond traditional information theory[SHA48][KUL] by formalizing the concept of Occam's razor, which favors the simplest explanation of given data, through the concept of the shortest program computing the data. There are many computable, time-bounded versions of this concept,[AIT7][AIT5][AIT12-13][AIT16-17] as well as applications to NNs.[KO2][CO1-3]
In the early 2000s, Marcus Hutter (while working under my Swiss National Science Foundation grant[UNI]) augmented Solomonoff's universal predictor[AIT1][AIT10] by an optimal action selector (a universal AI) for reinforcement learning agents living in initially unknown (but at least computable) environments.[AIT20,22] He also derived the asymptotically fastest algorithm for all well-defined computational problems,[AIT21] solving any problem as quickly as the unknown fastest solver of such problems, save for an additive constant that does not depend on the problem size.
The even more general optimality of the self-referential 2003
Gödel Machine[GM3-9] is not limited to asymptotic optimality.
Nevertheless, such mathematically optimal AIs are not yet practically feasible for various reasons. Instead, practical modern AI is based on suboptimal, limited, yet not extremely well-understood techniques such as NNs and deep learning, the focus of the present article. But who knows what kind of AI history will prevail 20 years form now?
Credit assignment is about finding patterns in historic data and figuring out how certain events were enabled by previous events. Historians do it. Physicists do it. AIs do it, too. Let's take a step back and look at AI in the broadest historical context: all time since the Big Bang. In 2014, I found
a beautiful pattern of exponential acceleration in it,[OMG] which I have presented in many talks since then, and which also made it into Sibylle Berg's award-winning book "GRM: Brainfuck."[OMG2]
Previously published patterns of this kind span much shorter time intervals: just a few decades or centuries or at most millennia.[OMG1]
It turns out that from a human perspective, the most important events since the beginning of the universe are neatly aligned on a timeline of exponential speed up (error bars mostly below 10 percent). In fact, history seems to converge in an Omega point in the year 2040 or so. I like to call it Omega, because a century ago, Teilhard de Chardin called Omega the point where humanity will reach its next level.[OMG0] Also, Omega sounds much better than "Singularity"[SING1-2]—it sounds a bit like "Oh my God."[OMG]
Let's start with the Big Bang 13.8 billion years ago. We divide this time by 4 to obtain about 3.5 billion years. Omega is 2040 or so. At Omega minus 3.5 billion years, something very important happened: life emerged on this planet.
And we take again a quarter of this time. We come out 900 million years ago when something very important happened: animal-like, mobile life emerged.
And we divide again by 4. We come out 220 million years ago when mammals were invented, our ancestors.
And we divide again by 4. 55 million years ago the first primates emerged, our ancestors.

And we divide again by 4. 13 million years ago the first hominids emerged, our ancestors.
I don't know why all these divisions by 4 keep hitting these defining moments in history. But they do. I also tried thirds, and fifths, and harmonic proportions, but only quarters seem to work.
And we divide again by 4. 3.5 million years ago something very important happened: the dawn of technology, as Nature called it: the first stone tools.
And we divide by 4. 800 thousand years ago the next great tech breakthrough happened: controlled fire.
And we divide by 4. 200 thousand years ago, anatomically modern man became prominent, our ancestor.
And we divide by 4. 50 thousand years ago, behaviorally modern man emerged, our ancestor, and started colonizing the world.
And we divide again by 4. We come out 13 thousand years ago when something very important happened: domestication of animals, agriculture, first settlements—the begin of civilisation. Now we see that all of civilization is just a flash in world history, just one millionth of the time since the Big Bang. Agriculture and spacecraft were invented almost at the same time.
And we divide by 4. 3,300 years ago saw the onset of the 1st population explosion in the Iron Age.
And we divide by 4. Remember that the convergence point Omega is the year 2040 or so. Omega minus 800 years—that was in the 13th century, when iron and fire came together in form of guns and cannons and rockets in China. This has defined the world since then and the West remains quite behind of the license fees it owes China.
And we divide again by 4. Omega minus 200 years—we hit the mid 19th century, when iron and fire came together in ever more sophisticated form to power the industrial revolution through improved steam engines, based on the work of Beaumont, Papin, Newcomen, Watt, and others (1600s-1700s, going beyond the first simple steam engines by Heron of Alexandria[RAU1] in the 1st century). The telephone (e.g., Meucci 1857, Reis 1860, Bell 1876)[NASC3] started to revolutionize communication. The germ theory of disease (Pasteur & Koch, late 1800s) revolutionized healthcare and made people live longer on average. And circa 1850, the fertilizer-based agricultural revolution (Sprengel & von Liebig, early 1800s) helped to trigger the 2nd population explosion, which peaked in the 20th century, when the world population quadrupled, letting the 20th century stand out among all centuries in the history of mankind, driven by the Haber-Bosch process for creating artificial fertilizer, without which the world could feed at most 4 billion people.[HAB1-2]
And we divide again by 4. Omega minus 50 years—that's more or less the year 1990, the end of the 3 great wars of the 20th century: WW1, WW2, and the Cold War. The 7 most valuable public companies were all Japanese (today most of them are US-based); however, both China and the US West Coast started to rise rapidly, setting the stage for the 21st century. A digital nervous system started spanning the globe through cell phones and the wireless revolution (based on radio waves discovered in the 1800s) as well as cheap personal computers for all. The WWW was created at the European particle collider in Switzerland by Tim Berners-Lee. And Modern AI started also around this time: the
first truly self-driving cars were built
in the 1980s in Munich by the team of Ernst Dickmanns (by 1994, their robot cars were driving in highway traffic, up to 180 km/h).[AUT] Back then, I worked on my 1987 diploma thesis,[META1] which introduced algorithms not just for learning but also for meta-learning or learning to learn,[META] to learn better learning algorithms through experience (now a very popular topic[DEC]). And then came our Miraculous Year 1990-91[MIR] at TU Munich,
the root of today's most cited NNs[MOST] and of modern deep learning through
self-supervised/unsupervised learning (see above),[UN][UN0-3] the LSTM/Highway Net/ResNet principle (now in your pocket on your smartphone—see above),[DL4][DEC][MOST]
artificial curiosity and generative adversarial NNs for agents that invent their own problems (see above),[AC90-AC20][PP-PP2][SA17]
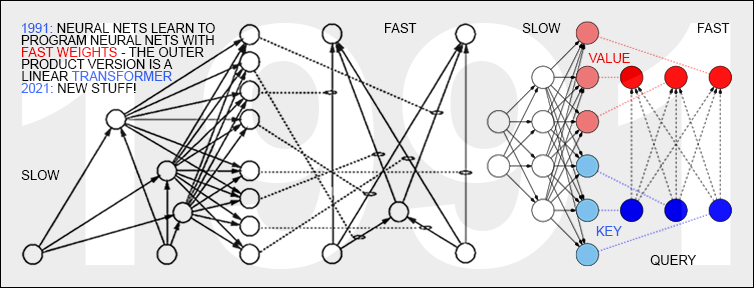
Transformers with linearized self-attention (see above),[FWP0-6][TR5-6]
distilling teacher NNs into student NNs (see above),[UN][UN0-3]
learning action plans
at multiple levels of abstraction and multiple time scales (see above),[HRL0-2][LEC]
and other exciting stuff. Much of this has become very popular, and improved the lives of billions of people.[DL4][DEC][MOST]
And we divide again by 4. Omega minus 13 years—that's a point in the near future, more or less the year 2030, when many predict that cheap AIs will have a human brain power. Then the final 13 years or so until Omega, when incredible things will happen
(take all of this with a grain of salt, though[OMG1]).
But of course, time won't stop with Omega. Maybe it's just human-dominated history that will end. After Omega, many curious meta-learning AIs that invent their own goals (which have existed in my lab for decades[AC][AC90,AC90b]) will quickly improve themselves, restricted only by the fundamental limits of computability and physics.
What will supersmart AIs do? Space is hostile to humans but friendly to appropriately designed robots, and offers many more resources than our thin film of biosphere, which receives less than a billionth of the sun's energy. While some curious AIs will remain fascinated with life, at least as long as they don't fully understand it,[ACM16][FA15][SP16][SA17]
most will be more interested in the incredible new opportunities for robots and software life out there in space. Through innumerable self-replicating robot factories in the asteroid belt and beyond they will transform the solar system and then within a few hundred thousand years the entire galaxy and within tens of billions of years the rest of the reachable universe. Despite the light-speed limit, the expanding AI sphere will have plenty of time to colonize and shape the entire visible cosmos.
Let me stretch your mind a bit. The universe is still young, only 13.8 billion years old. Remember when we kept dividing by 4? Now let's multiply by 4! Let's look ahead to a time when the cosmos will be 4 times older than it is now: about 55 billion years old. By then, the visible cosmos will be permeated by intelligence. Because after Omega, most AIs will have to go where most of the physical resources are, to make more and bigger AIs. Those who don't won't have an impact.[ACM16][FA15][SP16]

Acknowledgments
 Some of the material above was taken from previous AI Blog posts.[MIR] [DEC] [GOD21] [ZUS21] [LEI21] [AUT] [HAB2] [ARC06] [AC] [ATT] [DAN] [DAN1] [DL4] [GPUCNN5,8] [DLC] [FDL] [FWP] [LEC] [META] [MLP2] [MOST] [PLAN] [UN] [LSTMPG] [BP4] [DL6a] [HIN] [T22]
Thanks to many expert reviewers (including several famous neural net pioneers) for useful comments. Since science is about self-correction, let me know under juergen@idsia.ch if you can spot any remaining error. Many additional relevant publications can be found in my
publication page and my
arXiv page. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Some of the material above was taken from previous AI Blog posts.[MIR] [DEC] [GOD21] [ZUS21] [LEI21] [AUT] [HAB2] [ARC06] [AC] [ATT] [DAN] [DAN1] [DL4] [GPUCNN5,8] [DLC] [FDL] [FWP] [LEC] [META] [MLP2] [MOST] [PLAN] [UN] [LSTMPG] [BP4] [DL6a] [HIN] [T22]
Thanks to many expert reviewers (including several famous neural net pioneers) for useful comments. Since science is about self-correction, let me know under juergen@idsia.ch if you can spot any remaining error. Many additional relevant publications can be found in my
publication page and my
arXiv page. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
555+ References (and many more in the survey[DL1])
[25y97]
In 2022, we are celebrating the following works from a quarter-century ago.
1. Journal paper on Long Short-Term Memory, the
most cited neural network (NN) of the 20th century
(and basis of the most cited NN of the 21st).
2. First paper on physical, philosophical and theological consequences of the simplest and fastest way of computing
all possible metaverses
(= computable universes).
3. Implementing artificial curiosity and creativity through generative adversarial agents that learn to design abstract, interesting computational experiments.
4. Journal paper on
meta-reinforcement learning.
5. Journal paper on hierarchical Q-learning.
6. First paper on reinforcement learning to play soccer: start of a series.
7. Journal papers on flat minima & low-complexity NNs that generalize well.
8. Journal paper on Low-Complexity Art, the Minimal Art of the Information Age.
9. Journal paper on probabilistic incremental program evolution.
[AC]
J. Schmidhuber (AI Blog, 2021). 3 decades of artificial curiosity & creativity. Schmidhuber's artificial scientists not only answer given questions but also invent new questions. They achieve curiosity through: (1990) the principle of generative adversarial networks, (1991) neural nets that maximise learning progress, (1995) neural nets that maximise information gain (optimally since 2011), (1997) adversarial design of surprising computational experiments, (2006) maximizing compression progress like scientists/artists/comedians do, (2011) PowerPlay... Since 2012: applications to real robots.
[AC90]
J. Schmidhuber.
Making the world differentiable: On using fully recurrent
self-supervised neural networks for dynamic reinforcement learning and
planning in non-stationary environments.
Technical Report FKI-126-90, TUM, Feb 1990, revised Nov 1990.
PDF.
The first paper on online planning with reinforcement learning recurrent neural networks (NNs) (more) and on generative adversarial networks
where a generator NN is fighting a predictor NN in a minimax game
(more).
[AC90b]
J. Schmidhuber.
A possibility for implementing curiosity and boredom in
model-building neural controllers.
In J. A. Meyer and S. W. Wilson, editors, Proc. of the
International Conference on Simulation
of Adaptive Behavior: From Animals to
Animats, pages 222-227. MIT Press/Bradford Books, 1991. Based on [AC90].
PDF.
More.
[AC91]
J. Schmidhuber. Adaptive confidence and adaptive curiosity. Technical Report FKI-149-91, Inst. f. Informatik, Tech. Univ. Munich, April 1991.
PDF.
[AC91b]
J. Schmidhuber.
Curious model-building control systems.
Proc. International Joint Conference on Neural Networks,
Singapore, volume 2, pages 1458-1463. IEEE, 1991.
PDF.
[AC97]
J. Schmidhuber.
What's interesting?
Technical Report IDSIA-35-97, IDSIA, July 1997.
Focus
on automatic creation of predictable internal
abstractions of complex spatio-temporal events:
two competing, intrinsically motivated agents agree on essentially
arbitrary algorithmic experiments and bet
on their possibly surprising (not yet predictable)
outcomes in zero-sum games,
each agent potentially profiting from outwitting / surprising
the other by inventing experimental protocols where both
modules disagree on the predicted outcome. The focus is on exploring
the space of general algorithms (as opposed to
traditional simple mappings from inputs to
outputs); the
general system
focuses on the interesting
things by losing interest in both predictable and
unpredictable aspects of the world. Unlike Schmidhuber et al.'s previous
systems with intrinsic motivation,[AC90-AC95] the system also
takes into account
the computational cost of learning new skills, learning when to learn and what to learn.
See later publications.[AC99][AC02]
[AC98]
M. Wiering and J. Schmidhuber.
Efficient model-based exploration.
In R. Pfeiffer, B. Blumberg, J. Meyer, S. W. Wilson, eds.,
From Animals to Animats 5: Proceedings
of the Fifth International Conference on Simulation of Adaptive
Behavior, p. 223-228, MIT Press, 1998.
[AC98b]
M. Wiering and J. Schmidhuber.
Learning exploration policies with models.
In Proc. CONALD, 1998.
[AC99]
J. Schmidhuber.
Artificial Curiosity Based on Discovering Novel Algorithmic
Predictability Through Coevolution.
In P. Angeline, Z. Michalewicz, M. Schoenauer, X. Yao, Z.
Zalzala, eds., Congress on Evolutionary Computation, p. 1612-1618,
IEEE Press, Piscataway, NJ, 1999.
[AC02]
J. Schmidhuber.
Exploring the Predictable.
In Ghosh, S. Tsutsui, eds., Advances in Evolutionary Computing,
p. 579-612, Springer, 2002.
PDF.
[AC06]
J. Schmidhuber.
Developmental Robotics,
Optimal Artificial Curiosity, Creativity, Music, and the Fine Arts.
Connection Science, 18(2): 173-187, 2006.
PDF.
[AC09]
J. Schmidhuber. Art & science as by-products of the search for novel patterns, or data compressible in unknown yet learnable ways. In M. Botta (ed.), Et al. Edizioni, 2009, pp. 98-112.
PDF. (More on
artificial scientists and artists.)
[AC10]
J. Schmidhuber. Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990-2010). IEEE Transactions on Autonomous Mental Development, 2(3):230-247, 2010.
IEEE link.
PDF.
With a brief summary of the generative adversarial neural networks of 1990[AC90,90b][AC20]
where a generator NN is fighting a predictor NN in a minimax game
(more).
[AC20]
J. Schmidhuber. Generative Adversarial Networks are Special Cases of Artificial Curiosity (1990) and also Closely Related to Predictability Minimization (1991).
Neural Networks, Volume 127, p 58-66, 2020.
Preprint arXiv/1906.04493.
[ACM16] ACM interview by S. Ibaraki (2016). Chat with J. Schmidhuber:
Artificial Intelligence & Deep Learning—Now & Future.
Link.
[AIB] J. Schmidhuber. AI Blog.
Includes variants of chapters of the AI Book.
[AI51]
Les Machines a Calculer et la Pensee Humaine: Paris, 8.-13. Januar 1951, Colloques internationaux du Centre National de la Recherche Scientifique; no. 37, Paris 1953.
H. Bruderer[BRU4] calls that the first conference on AI.
[AIT1]
R. J. Solomonoff. A formal theory of inductive inference. Part I. Information and Control, 7:1-22, 1964.
[AIT2]
A. N. Kolmogorov. Three approaches to the quantitative definition of information. Problems of Information Transmission, 1:1-11, 1965.
[AIT3]
G.J. Chaitin.
On the length of programs for computing finite binary sequences:
statistical considerations.
Journal of the ACM, 16:145-159, 1969 (submitted 1965).
[AIT4]
P. Martin-Löf.
The definition of random sequences.
Information and Control, 9:602-619, 1966.
[AIT5]
C. S. Wallace and D. M. Boulton.
An information theoretic measure for classification.
Computer Journal, 11(2):185-194, 1968.
[AIT6]
A. K. Zvonkin and L. A. Levin.
The complexity of finite objects and the algorithmic concepts of
information and randomness.
Russian Math. Surveys, 25(6):83-124, 1970.
[AIT7]
L. A. Levin. Universal sequential search problems. Problems of Information Transmission, 9(3):265-266, 1973.
[AIT8]
L. A. Levin.
Laws of information (nongrowth) and aspects of the foundation of
probability theory.
Problems of Information Transmission, 10(3):206-210, 1974.
[AIT9]
C. P. Schnorr.
Process complexity and effective random tests.
Journal of Computer Systems Science, 7:376-388, 1973.
[AIT10]
R.J. Solomonoff.
Complexity-based induction systems.
IEEE Transactions on Information Theory, IT-24(5):422-432,
1978.
[AIT11]
P. Gacs. On the relation between descriptional complexity and algorithmic
probability.
Theoretical Computer Science, 22:71-93, 1983.
[AIT12]
J. Hartmanis.
Generalized Kolmogorov complexity and the structure of feasible
computations. Proc. 24th IEEE Symposium on Foundations of Computer
Science, pages 439-445, 1983.
[AIT13]
J. Rissanen.
Stochastic complexity and modeling.
The Annals of Statistics, 14(3):1080-1100, 1986.
[AIT14]
Y. M. Barzdin. Algorithmic information theory.
In D. Reidel, editor, Encyclopaedia of Mathematics, vol. 1, pages 140-142. Kluwer Academic Publishers, 1988.
[AIT15]
O. Watanabe.
Kolmogorov complexity and computational complexity.
EATCS Monographs on Theoretical Computer Science, Springer, 1992.
[AIT16]
M. Li and P. M. B. Vitanyi. An Introduction to Kolmogorov Complexity and its Applications (2nd edition). Springer, 1997.
[AIT17]
J. Schmidhuber. Discovering neural nets with low Kolmogorov complexity and high
generalization capability. Neural Networks, 10(5):857-873, 1997.
[AIT18]
M. S. Burgin and Y. M. Borodyanskii.
Infinite processes and super-recursive algorithms.
Notices of the Academy of Sciences of the USSR (translated from
Russian), 321(5):800-803, 1991.
[AIT19]
C. S. Calude.
Chaitin Omega numbers, Solovay machines and Gödel
incompleteness.
Theoretical Computer Science, 2000.
[AIT20]
M. Hutter.
A theory of universal artificial intelligence based on algorithmic complexity.
Technical Report IDSIA-14-00 (cs.AI/0004001), IDSIA, Manno (Lugano), CH, 2000.
[AIT21]
M. Hutter.
The fastest and shortest algorithm for all well-defined problems. International Journal of Foundations of Computer Science, 13(3):431-443, 2002. (Based on work done under J. Schmidhuber's SNF grant 20-61847: unification of universal induction and sequential decision theory, 2000).
[AIT22]
M. Hutter.
Universal Artificial Intelligence: Sequential Decisions based on Algorithmic Probability. Springer, Berlin, 2004. (Based on work done under J. Schmidhuber's SNF grant 20-61847: unification of universal induction and sequential decision theory, 2000).
[AIT23]
J. Schmidhuber. Hierarchies of generalized Kolmogorov complexities and
nonenumerable universal measures computable in the limit.
International Journal of Foundations of Computer Science, 13(4):587-612, 2002.
[AIT24]
J. Schmidhuber.
The Speed Prior: a new simplicity measure yielding near-optimal
computable predictions. In J. Kivinen and R. H. Sloan, editors, Proceedings of the 15th
Annual Conference on Computational Learning Theory (COLT 2002), Lecture
Notes in Artificial Intelligence, pages 216-228. Springer, Sydney,
Australia, 2002.
[AM16]
Blog of Werner Vogels, CTO of Amazon (Nov 2016):
Amazon's Alexa
"takes advantage of bidirectional long short-term memory (LSTM) networks using a massive amount of data to train models that convert letters to sounds and predict the intonation contour. This technology enables high naturalness, consistent intonation, and accurate processing of texts."
[AMH0]
S. I. Amari (1972).
Characteristics of random nets of analog neuron-like elements. IEEE Trans. Syst. Man Cybernetics, 2, 643-657. First published 1969 in Japanese, long before Wilson & Cowan's very similar work (1972-73).
[AMH1]
S. I. Amari (1972).
Learning patterns and pattern sequences by self-organizing nets of threshold elements. IEEE Transactions, C 21, 1197-1206, 1972.
PDF.
First publication of what was later sometimes called the Hopfield network[AMH2] or Amari-Hopfield Network,[AMH3] based on the (uncited) Lenz-Ising recurrent architecture.[L20][I25][T22]
[AMH1b]
W. A. Little. The existence of persistent states in the brain. Mathematical Biosciences, 19.1-2, p. 101-120, 1974.
Mentions the recurrent Ising model[L20][I25]on which the (uncited) Amari network[AMH1,2] is based.
[AMH2]
J. J. Hopfield (1982). Neural networks and physical systems with emergent
collective computational abilities. Proc. of the National Academy of Sciences,
vol. 79, pages 2554-2558, 1982.
The Hopfield network or Amari-Hopfield Network was first published in 1972 by Amari.[AMH1] [AMH2] did not cite [AMH1].
[AMH3]
A. P. Millan, J. J. Torres, J. Marro.
How Memory Conforms to Brain Development.
Front. Comput. Neuroscience, 2019
[ARC06]
J. Schmidhuber (2006).
Archimedes—Greatest Scientist Ever?
[ATT] J. Schmidhuber (AI Blog, 2020). 30-year anniversary of end-to-end differentiable sequential neural attention. Plus goal-conditional reinforcement learning. Schmidhuber had both hard attention for foveas (1990) and soft attention in form of Transformers with linearized self-attention (1991-93).[FWP] Today, both types are very popular.
[ATT0] J. Schmidhuber and R. Huber.
Learning to generate focus trajectories for attentive vision.
Technical Report FKI-128-90, Institut für Informatik, Technische
Universität München, 1990.
PDF.
[ATT1] J. Schmidhuber and R. Huber. Learning to generate artificial fovea trajectories for target detection. International Journal of Neural Systems, 2(1 & 2):135-141, 1991. Based on TR FKI-128-90, TUM, 1990.
PDF.
More.
[ATT2]
J. Schmidhuber.
Learning algorithms for networks with internal and external feedback.
In D. S. Touretzky, J. L. Elman, T. J. Sejnowski, and G. E. Hinton,
editors, Proc. of the 1990 Connectionist Models Summer School, pages
52-61. San Mateo, CA: Morgan Kaufmann, 1990.
PS. (PDF.)
[ATT3]
H. Larochelle, G. E. Hinton. Learning to combine foveal glimpses with a third-order Boltzmann machine. NIPS 2010. This work is very similar to [ATT0-2] which the authors did not cite.
In fact, Hinton was the reviewer of a 1990 paper[ATT2] which summarised in its Section 5 Schmidhuber's early work on attention: the first implemented neural system for combining glimpses that jointly trains a recognition & prediction component
with an attentional component (the fixation controller).
Two decades later, Hinton wrote about
his own work:[ATT3]
"To our knowledge, this is the first implemented system for combining glimpses that jointly trains a recognition component ... with an attentional component (the fixation controller)." See [MIR](Sec. 9)[R4].
[ATT14]
D. Bahdanau, K. Cho, Y. Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. 2014-16.
Preprint
arXiv/1409.0473, 2014-16.
This work on soft "attention" did not cite Schmidhuber's much earlier original work of 1991-1993 on soft attention and Transformers with linearized self-attention.[FWP,FWP0-2,6][ATT]
[AUT]
J. Schmidhuber (AI Blog, 2005). Highlights of robot car history. Around 1986, Ernst Dickmanns and his group at Univ. Bundeswehr Munich built the world's first real autonomous robot cars, using saccadic vision, probabilistic approaches such as Kalman filters, and parallel computers. By 1994, they were in highway traffic, at up to 180 km/h, automatically passing other cars.
[AV1] A. Vance. Google Amazon and Facebook Owe Jürgen Schmidhuber a Fortune—This Man Is the Godfather the AI Community Wants to Forget. Business Week,
Bloomberg, May 15, 2018.
[BA93]
P. Baldi and Y. Chauvin. Neural Networks for Fingerprint Recognition, Neural Computation, Vol. 5, 3, 402-418, (1993).
First application of CNNs with backpropagation to biomedical/biometric images.
[BA96]
P. Baldi and Y. Chauvin. Hybrid Modeling, HMM/NN Architectures, and Protein Applications, Neural Computation, Vol. 8, 7, 1541-1565, (1996).
One of the first papers on graph neural networks.
[BA99]
P. Baldi, S. Brunak, P. Frasconi, G. Soda, and G. Pollastri. Exploiting the Past and the Future in Protein Secondary Structure Prediction, Bioinformatics, Vol. 15, 11, 937-946, (1999).
[BA03]
P. Baldi and G. Pollastri. The Principled Design of Large-Scale Recursive Neural Network Architectures-DAG-RNNs and the Protein Structure Prediction Problem. Journal of Machine Learning Research, 4, 575-602, (2003).
[BAN]
Banu Musa brothers (9th century). The book of ingenious devices (Kitab al-hiyal). Translated by D. R. Hill (1979), Springer, p. 44, ISBN 90-277-0833-9.
As far as we know, the Banu Musa music automaton was the world's first machine with a stored program.
[BAU]
F. L. Bauer, H. Woessner (1972). The "Plankalkül" of Konrad Zuse: A Forerunner of Today's Programming Languages.
[BAY1]
S. M. Stigler. Who Discovered Bayes' Theorem? The American Statistician. 37(4):290-296, 1983.
Bayes' theorem is actually Laplace's theorem or possibly Saunderson's theorem.
[BAY2]
T. Bayes. An essay toward solving a problem in the doctrine of chances. Philosophical
Transactions of the Royal Society of London, 53:370-418. Communicated by R. Price, in a letter
to J. Canton, 1763.
[BAY3]
D. J. C. MacKay. A practical Bayesian framework for backprop networks. Neural Computation,
4:448-472, 1992.
[BAY4]
J. Pearl.
Probabilistic reasoning in intelligent systems: Networks of plausible inference.
Synthese-Dordrecht 104(1):161, 1995.
[BAY5]
N. M. Oliver, B. Rosario, A. P. Pentland
A Bayesian computer vision system for modeling human interactions.
IEEE transactions on pattern analysis and machine intelligence 22.8:831-843, 2000.
[BAY6]
D. M. Blei, A. Y. Ng, M. I. Jordan. Latent Dirichlet Allocation. Journal of Machine Learning Research 3:993-1022, 2003.
[BAY7]
J. F. G. De Freitas. Bayesian methods for neural networks. PhD thesis, University of Cambridge, 2003.
[BAY8]
J. M. Bernardo, A.F.M. Smith. Bayesian theory. Vol. 405. John Wiley & Sons, 2009.
[BB2]
J. Schmidhuber.
A local learning algorithm for dynamic feedforward and
recurrent networks.
Connection Science, 1(4):403-412, 1989.
(The Neural Bucket Brigade—figures omitted!).
PDF.
HTML.
Compare TR FKI-124-90, TUM, 1990.
PDF.
Proposal of a biologically more plausible deep learning algorithm that—unlike backpropagation—is local in space and time. Based on a "neural economy" for reinforcement learning.
[BEL53] R. Bellman. An introduction to the theory of dynamic programming. RAND Corp. Report, 1953
[BIB3]
W. Bibel (2003).
Mosaiksteine einer Wissenschaft vom Geiste. Invited talk at
the conference on AI and Gödel, Arnoldsheim, 4-6 April 2003.
Manuscript, 2003.
[BL16]
L. Bloch (2016). Informatics in the light of some Leibniz's works.
Communication to XB2 Berlin Xenobiology Conference.
[BM]
D. Ackley, G. Hinton, T. Sejnowski (1985). A Learning Algorithm for Boltzmann Machines. Cognitive Science, 9(1):147-169.
This paper neither cited relevant prior work
by Sherrington & Kirkpatrick[SK75] & Glauber[G63] nor the first working algorithms for deep learning of internal representations (Ivakhnenko & Lapa, 1965)[DEEP1-2][HIN] nor
Amari's work (1967-68)[GD1-2] on learning internal representations in deep nets through stochastic gradient descent.
Even later surveys by the authors[S20][DLC] failed to cite the prior art.[T22]
[BER96]
D. P. Bertsekas, J. N. Tsitsiklis. Neuro-dynamic Programming. Athena Scientific, Belmont, MA, 1996.
[BOO]
George Boole (1847). The Mathematical Analysis of Logic, Being an Essay towards a Calculus of Deductive Reasoning.
London, England: Macmillan, Barclay, & Macmillan, 1847. Leibniz'
formal Algebra of Thought (1686)[L86][WI48] was
deductively equivalent[LE18] to the much later
Boolean Algebra.
[BOU] H Bourlard, N Morgan (1993). Connectionist speech recognition. Kluwer, 1993.
[BPA]
H. J. Kelley. Gradient Theory of Optimal Flight Paths. ARS Journal, Vol. 30, No. 10, pp. 947-954, 1960.
Precursor of modern backpropagation.[BP1-5]
[BPB]
A. E. Bryson. A gradient method for optimizing multi-stage allocation processes. Proc. Harvard Univ. Symposium on digital computers and their applications, 1961.
[BPC]
S. E. Dreyfus. The numerical solution of variational problems. Journal of Mathematical Analysis and Applications, 5(1): 30-45, 1962.
[BP1] S. Linnainmaa. The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's Thesis (in Finnish), Univ. Helsinki, 1970.
See chapters 6-7 and FORTRAN code on pages 58-60.
PDF.
See also BIT 16, 146-160, 1976.
Link.
The first publication on "modern" backpropagation, also known as the reverse mode of automatic differentiation.
[BP2] P. J. Werbos. Applications of advances in nonlinear sensitivity analysis. In R. Drenick, F. Kozin, (eds): System Modeling and Optimization: Proc. IFIP,
Springer, 1982.
PDF.
First application of backpropagation[BP1] to NNs (concretizing thoughts in Werbos' 1974 thesis).
[BP4] J. Schmidhuber (AI Blog, 2014; updated 2020).
Who invented backpropagation?
More.[DL2]
[BP5]
A. Griewank (2012). Who invented the reverse mode of differentiation?
Documenta Mathematica, Extra Volume ISMP (2012): 389-400.
[BPTT1]
P. J. Werbos. Backpropagation through time: what it does and how to do it. Proceedings of the IEEE 78.10, 1550-1560, 1990.
[BPTT2]
R. J. Williams and D. Zipser. Gradient-based learning algorithms for recurrent networks. In: Backpropagation: Theory, architectures, and applications, p 433, 1995.
[BPTT3]
B. A. Pearlmutter. Gradient calculations for dynamic recurrent neural networks: A survey.
IEEE Transactions on Neural Networks, 6(5):1212-1228, 1995.
[BUR18]
Y. Burda, H. Edwards, D. Pathak, A. Storkey, T. Darrell, A. A. Efros.
Large-scale study of curiosity-driven learning.
Preprint arXiv:1808.04355, 2018.
[BRE]
H. J. Bremermann (1982). Minimum energy requirements of information transfer and computing, International Journal of Theoretical Physics, 21, 203-217, 1982.
[BRI] Bridle, J.S. (1990). Alpha-Nets: A Recurrent "Neural" Network Architecture with a Hidden Markov Model Interpretation, Speech Communication, vol. 9, no. 1, pp. 83-92.
[BRU1]
H. Bruderer. Computing history beyond the UK and US: selected landmarks from continental Europe. Communications of the ACM 60.2 (2017): 76-84.
[BRU2]
H. Bruderer. Meilensteine der Rechentechnik. 2 volumes, 3rd edition. Walter de Gruyter GmbH & Co KG, 2020.
[BRU3]
H. Bruderer. Milestones in Analog and Digital Computing. 2 volumes, 3rd edition. Springer Nature Switzerland AG, 2020.
[BRU4]
H. Bruderer. The Birthplace of Artificial Intelligence? Communications of the ACM, BLOG@CACM, Nov 2017.
Link.
[BRO21]
D. C. Brock (2021).
Cybernetics, Computer Design, and a Meeting of the Minds.
An influential 1951 conference in Paris considered the computer as a model of—and for—the human mind.
IEEE Spectrum, 2021. Link.
[BW] H. Bourlard, C. J. Wellekens (1989).
Links between Markov models and multilayer perceptrons. NIPS 1989, p. 502-510.
[CAN]
G. Cantor (1891). Ueber eine elementare Frage der Mannigfaltigkeitslehre. Jahresbericht der Deutschen Mathematiker-Vereinigung, 1:75-78. English translation: W. B. Ewald (ed.). From Immanuel Kant to David Hilbert: A Source Book in the Foundations of Mathematics, Volume 2, pp. 920-922. Oxford University Press, 1996.
[CDI]
G. E. Hinton. Training products of experts by minimizing contrastive divergence. Neural computation 14.8 (2002): 1771-1800.
[CHO15]
F. Chollet (2015). Keras.
[CHU]
A. Church (1935). An unsolvable problem of elementary number theory. Bulletin of the American Mathematical Society, 41: 332-333. Abstract of a talk given on 19 April 1935, to the American Mathematical Society.
Also in American Journal of Mathematics, 58(2), 345-363 (1 Apr 1936).
First explicit proof that the Entscheidungsproblem (decision problem) does not have a general solution.
[CNN1] K. Fukushima: Neural network model for a mechanism of pattern
recognition unaffected by shift in position—Neocognitron.
Trans. IECE, vol. J62-A, no. 10, pp. 658-665, 1979.
The first deep convolutional neural network architecture, with alternating convolutional layers and downsampling layers. In Japanese. English version: [CNN1+]. More in Scholarpedia.
[CNN1+]
K. Fukushima: Neocognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position.
Biological Cybernetics, vol. 36, no. 4, pp. 193-202 (April 1980).
Link.
[CNN1a] A. Waibel. Phoneme Recognition Using Time-Delay Neural Networks. Meeting of IEICE, Tokyo, Japan, 1987. First application of backpropagation[BP1-5] and weight-sharing
to a convolutional architecture.
[CNN1b] A. Waibel, T. Hanazawa, G. Hinton, K. Shikano and K. J. Lang. Phoneme recognition using time-delay neural networks. IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 37, no. 3, pp. 328-339, March 1989. Based on [CNN1a].
[CNN1c] Bower Award Ceremony 2021:
Jürgen Schmidhuber lauds Kunihiko Fukushima. YouTube video, 2021.
[CNN2] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, L. D. Jackel: Backpropagation Applied to Handwritten Zip Code Recognition, Neural Computation, 1(4):541-551, 1989.
PDF.
[CNN3a]
K. Yamaguchi, K. Sakamoto, A. Kenji, T. Akabane, Y. Fujimoto. A Neural Network for Speaker-Independent Isolated Word Recognition. First International Conference on Spoken Language Processing (ICSLP 90), Kobe, Japan, Nov 1990.
An NN with convolutions using Max-Pooling instead of Fukushima's
Spatial Averaging.[CNN1]
[CNN3] Weng, J.,
Ahuja, N., and Huang, T. S. (1993). Learning recognition and segmentation of 3-D objects from 2-D images. Proc. 4th Intl. Conf. Computer Vision, Berlin, Germany, pp. 121-128. A CNN whose downsampling layers use Max-Pooling
(which has become very popular) instead of Fukushima's
Spatial Averaging.[CNN1]
[CNN4] M. A. Ranzato, Y. LeCun: A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images. Proc. ICDAR, 2007
[CNN5a]
S. Behnke. Learning iterative image reconstruction in the neural abstraction pyramid. International Journal of Computational Intelligence and Applications, 1(4):427-438, 1999.
[CNN5b]
S. Behnke. Hierarchical Neural Networks for Image Interpretation, volume LNCS 2766 of Lecture Notes in Computer Science. Springer, 2003.
[CNN5c]
D. Scherer, A. Mueller, S. Behnke. Evaluation of pooling operations in convolutional architectures for object recognition. In Proc. International Conference on Artificial Neural Networks (ICANN), pages 92-101, 2010.
[CO1]
J. Koutnik, F. Gomez, J. Schmidhuber (2010). Evolving Neural Networks in Compressed Weight Space. Proceedings of the Genetic and Evolutionary Computation Conference
(GECCO-2010), Portland, 2010.
PDF.
[CO2]
J. Koutnik, G. Cuccu, J. Schmidhuber, F. Gomez.
Evolving Large-Scale Neural Networks for Vision-Based Reinforcement Learning.
Proceedings of the Genetic and Evolutionary
Computation Conference (GECCO), Amsterdam, July 2013.
PDF.
The first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning, without any unsupervised pre-training.
[CO3]
R. K. Srivastava, J. Schmidhuber, F. Gomez.
Generalized Compressed Network Search.
Proc. GECCO 2012.
PDF.
[CON16]
J. Carmichael (2016).
Artificial Intelligence Gained Consciousness in 1991.
Why A.I. pioneer Jürgen Schmidhuber is convinced the ultimate breakthrough already happened.
Inverse, 2016. Link.
[CONN21]
Since November 2021: Comments on version 1 of the report[T22]
in the Connectionists Mailing List, perhaps the oldest mailing list on artificial neural networks. Link to the archive.
[CTC] A. Graves, S. Fernandez, F. Gomez, J. Schmidhuber. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. ICML 06, Pittsburgh, 2006.
PDF.
[CUB0]
R. J. Williams.
Complexity of exact gradient computation algorithms for recurrent
neural networks. Technical Report NU-CCS-89-27, Northeastern University,
College of Computer Science, 1989.
[CUB2]
J. Schmidhuber.
A fixed size
storage O(n3) time complexity learning algorithm for fully recurrent
continually running networks.
Neural Computation, 4(2):243-248, 1992.
PDF.
[CW]
J. Koutnik, K. Greff, F. Gomez, J. Schmidhuber. A Clockwork RNN. Proc. 31st International Conference on Machine Learning (ICML), p. 1845-1853, Beijing, 2014. Preprint arXiv:1402.3511 [cs.NE].
[DAN]
J. Schmidhuber (AI Blog, 2021).
10-year anniversary. In 2011, DanNet triggered the deep convolutional neural network (CNN) revolution. Named after Schmidhuber's outstanding postdoc Dan Ciresan, it was the first deep and fast CNN to win international computer vision contests, and had a temporary monopoly on winning them, driven by a very fast implementation based on graphics processing units (GPUs).
1st superhuman result in 2011.[DAN1] Now everybody is using this approach.
[DAN1]
J. Schmidhuber (AI Blog, 2011; updated 2021 for 10th birthday of DanNet): First superhuman visual pattern recognition.
At the IJCNN 2011 computer vision competition in Silicon Valley,
the artificial neural network called DanNet performed twice better than humans, three times better than the closest artificial competitor (from LeCun's team), and six times better than the best non-neural method.
[DEC] J. Schmidhuber (AI Blog, 02/20/2020, updated 2021, 2022). The 2010s: Our Decade of Deep Learning / Outlook on the 2020s. The recent decade's most important developments and industrial applications based on the AI of Schmidhuber's team, with an outlook on the 2020s, also addressing privacy and data markets.
[DEEP1]
Ivakhnenko, A. G. and Lapa, V. G. (1965). Cybernetic Predicting Devices. CCM Information Corporation. First working Deep Learners with many layers, learning internal representations.
[DEEP1a]
Ivakhnenko, Alexey Grigorevich. The group method of data of handling; a rival of the method of stochastic approximation. Soviet Automatic Control 13 (1968): 43-55.
[DEEP2]
Ivakhnenko, A. G. (1971). Polynomial theory of complex systems. IEEE Transactions on Systems, Man and Cybernetics, (4):364-378.
[DIST2]
O. Vinyals, J. A. Dean, G. E. Hinton.
Distilling the Knowledge in a Neural Network.
Preprint arXiv:1503.02531 [stat.ML], 2015.
The authors did not cite Schmidhuber's original
1991 NN distillation procedure,[UN0-2][MIR](Sec. 2)
not even in the later patent application US20150356461A1.
[DL1] J. Schmidhuber, 2015.
Deep learning in neural networks: An overview. Neural Networks, 61, 85-117.
More.
Got the first Best Paper Award ever issued by the journal Neural Networks, founded in 1988.
[DL2] J. Schmidhuber, 2015.
Deep Learning.
Scholarpedia, 10(11):32832.
[DL3] Y. LeCun, Y. Bengio, G. Hinton (2015). Deep Learning. Nature 521, 436-444.
HTML.
A "survey" of deep learning that does not mention the pioneering works of deep learning [T22].
[DL3a] Y. Bengio, Y. LeCun, G. Hinton (2021). Turing Lecture: Deep Learning for AI. Communications of the ACM, July 2021. HTML.
Local copy (HTML only).
Another "survey" of deep learning that does not mention the pioneering works of deep learning [T22].
[DL4] J. Schmidhuber (AI Blog, 2017).
Our impact on the world's most valuable public companies: Apple, Google, Microsoft, Facebook, Amazon... By 2015-17, neural nets developed in Schmidhuber's labs were on over 3 billion devices such as smartphones, and used many billions of times per day, consuming a significant fraction of the world's compute. Examples: greatly improved (CTC-based) speech recognition on all Android phones, greatly improved machine translation through Google Translate and Facebook (over 4 billion LSTM-based translations per day), Apple's Siri and Quicktype on all iPhones, the answers of Amazon's Alexa, etc. Google's 2019
on-device speech recognition
(on the phone, not the server)
is still based on
LSTM.
[DL6]
F. Gomez and J. Schmidhuber.
Co-evolving recurrent neurons learn deep memory POMDPs.
In Proc. GECCO'05, Washington, D. C.,
pp. 1795-1802, ACM Press, New York, NY, USA, 2005.
PDF.
[DL6a]
J. Schmidhuber (AI Blog, Nov 2020). 15-year anniversary: 1st paper with "learn deep" in the title (2005). The deep reinforcement learning & neuroevolution developed in Schmidhuber's lab solved problems of depth 1000 and more.[DL6] Soon after its publication, everybody started talking about "deep learning." Causality or correlation?
[DL7]
"Deep Learning ... moving beyond shallow machine learning since 2006!"
Web site deeplearning.net of Y. Bengio's MILA (2015, retrieved May 2020; compare the version in the
Internet Archive),
referring to Hinton's[UN4] and Bengio's[UN5]
unsupervised pre-training for deep NNs[UN4] (2006) although
this type of deep learning dates back to Schmidhuber's work of 1991.[UN1-2][UN]
[DLC] J. Schmidhuber (AI Blog, June 2015).
Critique of Paper by self-proclaimed[DLC2] "Deep Learning Conspiracy" (Nature 521 p 436).
The inventor of an important method should get credit for inventing it. She may not always be the one who popularizes it. Then the popularizer should get credit for popularizing it (but not for inventing it). More on this under [T22].
[DLC1]
Y. LeCun. IEEE Spectrum Interview by L. Gomes, Feb 2015.
Quote: "A lot of us involved in the resurgence of Deep Learning in the mid-2000s, including Geoff Hinton, Yoshua Bengio, and myself—the so-called 'Deep Learning conspiracy' ..."
[DLC2]
M. Bergen, K. Wagner (2015).
Welcome to the AI Conspiracy: The 'Canadian Mafia' Behind Tech's Latest Craze. Vox recode, 15 July 2015.
Quote: "... referred to themselves as the 'deep learning conspiracy.' Others called them the 'Canadian Mafia.'"
[DLH]
J. Schmidhuber (AI Blog, 2022).
Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, IDSIA, Lugano, Switzerland, 2022.
Preprint arXiv:2212.11279.
Tweet of 2022.
[DM1]
V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, M. Riedmiller. Playing Atari with Deep Reinforcement Learning. Tech Report, 19 Dec. 2013,
arxiv:1312.5602.
[DM2] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, D. Hassabis. Human-level control through deep reinforcement learning. Nature, vol. 518, p 1529, 26 Feb. 2015.
Link.
DeepMind's first famous paper. Its abstract claims: "While reinforcement learning agents have achieved some successes in a variety of domains, their applicability has previously been limited to domains in which useful features can be handcrafted, or to domains with fully observed, low-dimensional state spaces." It also claims to bridge "the divide between high-dimensional sensory inputs and actions." Similarly, the first sentence of the abstract of the earlier tech report version[DM1] of [DM2] claims to "present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning."
However, the first such system (requiring no unsupervised pre-training) was created earlier by Jan Koutnik et al. in Schmidhuber's lab.[CO2]
DeepMind was co-founded by Shane Legg, a PhD student from this lab; he and Daan Wierstra (another PhD student of Schmidhuber and DeepMind's 1st employee) were the first persons at DeepMind who had AI publications and PhDs in computer science. More.
[DM2a]
D. Silver et al. A general reinforcement learning algorithm that masters chess, Shogi, and Go through self-play. Science 362.6419:1140-1144, 2018.
[DM3]
S. Stanford. DeepMind's AI, AlphaStar Showcases Significant Progress Towards AGI. Medium ML Memoirs, 2019.
Alphastar has a "deep LSTM core."
[DM4]
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Figurnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. Zidek, A. Potapenko, A. Bridgland, C. Meyer, S. A. A. Kohl, A. J. Ballard, A. Cowie, B. Romera-Paredes, S. Nikolov, R. Jain, J. Adler, T. Back, S. Petersen, D. Reiman, E. Clancy, M. Zielinski, M. Steinegger, M. Pacholska, T. Berghammer, S. Bodenstein, D. Silver, O. Vinyals, A. W. Senior, K. Kavukcuoglu, P. Kohli & D. Hassabis. Highly accurate protein structure prediction with AlphaFold. Nature 596, 583-589, 2021.
DeepMind's breakthrough application of deep learning did not cite
Hochreiter et al.'s first successful application [HO07] of deep learning to protein folding (2007).
[DIF1]
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer.
High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022.
Preprint arXiv:2112.10752, LMU Munich, 2021.
[DIF2]
C. Jarzynski. Equilibrium free-energy differences from nonequilibrium measurements: A master-equation approach. Physical Review E, 1997.
[DIF3]
J. Sohl-Dickstein, E. A. Weiss, N. Maheswaranathan, S. Ganguli. Deep unsupervised
learning using nonequilibrium thermodynamics. CoRR, abs/1503.03585, 2015.
[DIF4]
O. Ronneberger, P. Fischer, T. Brox. Unet:
Convolutional networks for biomedical image segmentation.
In MICCAI (3), vol. 9351 of Lecture Notes in
Computer Science, pages 234-241. Springer, 2015.
[DIF5]
J. Ho, A. Jain, P. Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems 33:6840-6851, 2020.
[DNC]
A. Graves, G. Wayne, M. Reynolds, T. Harley, I. Danihelka, A. Grabska-Barwinska, S. G. Colmenarejo, E. Grefenstette, T. Ramalho, J. Agapiou, A. P. Badia, K. M. Hermann, Y. Zwols, G. Ostrovski, A. Cain, H. King, C. Summerfield, P. Blunsom, K. Kavukcuoglu, D. Hassabis.
Hybrid computing using a neural network with dynamic external memory.
Nature, 538:7626, p 471, 2016.
This work of DeepMind did not cite the original work of the early 1990s on
neural networks learning to control dynamic external memories.[PDA1-2][FWP0-1]
[Drop1] S. J. Hanson (1990). A Stochastic Version of the Delta Rule, PHYSICA D,42, 265-272.
What's now called "dropout" is a variation of the stochastic delta rule—compare preprint
arXiv:1808.03578, 2018.
[Drop2]
N. Frazier-Logue, S. J. Hanson (2020). The Stochastic Delta Rule: Faster and More Accurate Deep Learning Through Adaptive Weight Noise. Neural Computation 32(5):1018-1032.
[Drop3]
J. Hertz, A. Krogh, R. Palmer (1991). Introduction to the Theory of Neural Computation. Redwood City, California: Addison-Wesley Pub. Co., pp. 45-46.
[Drop4]
N. Frazier-Logue, S. J. Hanson (2018). Dropout is a special case of the stochastic delta rule: faster and more accurate deep learning.
Preprint
arXiv:1808.03578, 2018.
[DYNA90]
R. S. Sutton (1990). Integrated Architectures for Learning, Planning, and Reacting Based on Approximating Dynamic Programming. Machine Learning Proceedings 1990, of the Seventh International Conference, Austin, Texas, June 21-23,
1990, p 216-224.
[DYNA91]
R. S. Sutton (1991). Dyna, an integrated architecture for learning, planning, and reacting. ACM Sigart Bulletin 2.4 (1991):160-163.
[ELM1]
G.-B. Huang, Q.-Y. Zhu, and C.-K. Siew. Extreme learning machine: A new learning scheme of feedforward neural networks. Proc. IEEE Int. Joint Conf. on Neural Networks, Vol. 2, 2004, pp. 985-990. This paper does not mention that the "ELM" concept goes back to Rosenblatt's work in the 1950s.[R62][T22]
[ELM2]
ELM-ORIGIN, 2004.
The Official Homepage on Origins of Extreme Learning Machines (ELM).
"Extreme Learning Machine Duplicates Others' Papers from 1988-2007."
Local copy.
This overview does not mention that the "ELM" concept goes back to Rosenblatt's work in the 1950s.[R62][T22]
[ENS1]
R. E. Schapire. The strength of weak learnability. Machine Learning, 5:197-227, 1990.
[ENS2]
D. H. Wolpert. Stacked generalization. Neural Networks, 5(2):241-259, 1992.
[ENS3]
L. Breiman. Bagging predictors. Machine Learning, 24:123-140, 1996.
[ENS4]
T. G. Dietterich. Ensemble methods in machine learning. In Multiple classifier systems, pages 1-15. Springer, 2000.
[EVO1]
N. A. Barricelli. Esempi numerici di processi di evoluzione. Methodos: 45-68, 1954.
Possibly the first publication on artificial evolution.
[EVO2]
L. Fogel, A. Owens, M. Walsh. Artificial Intelligence through Simulated Evolution.
Wiley, New York, 1966.
[EVO3] I. Rechenberg. Evolutionsstrategie—Optimierung technischer Systeme nach Prinzipien der biologischen Evolution. Dissertation, 1971.
[EVO4] H. P. Schwefel. Numerische Optimierung von Computer-Modellen. Dissertation, 1974.
[EVO5] J. H. Holland. Adaptation in Natural and Artificial Systems. University of Michigan Press, Ann Arbor, 1975.
[EVO6] S. F. Smith. A Learning System Based on Genetic Adaptive Algorithms, PhD Thesis, Univ. Pittsburgh, 1980
[EVO7] N. L. Cramer. A representation for the adaptive generation of simple sequential programs. In J. J. Grefenstette, editor, Proceedings of an International Conference on Genetic Algorithms and Their Applications, Carnegie-Mellon University, July 24-26, 1985, Hillsdale NJ, 1985. Lawrence Erlbaum Associates.
[EVONN1]
Montana, D. J. and Davis, L. (1989). Training feedforward neural networks using genetic algorithms.
In Proceedings of the 11th International Joint Conference on Artificial Intelligence (IJCAI)—Volume
1, IJCAI'89, pages 762–767, San Francisco, CA, USA. Morgan Kaufmann Publishers Inc.
[EVONN2]
Miller, G., Todd, P., and Hedge, S. (1989). Designing neural networks using genetic algorithms. In
Proceedings of the 3rd International Conference on Genetic Algorithms, pages 379–384. Morgan
Kauffman.
[EVONN3] H. Kitano. Designing neural networks using genetic algorithms with graph generation system. Complex Systems, 4:461-476, 1990.
[FA15] Intelligente Roboter werden vom Leben fasziniert sein.
(Intelligent robots will be fascinated by life.)
FAZ, 1 Dec 2015.
Link.
[FAKE]
H. Hopf, A. Krief, G. Mehta, S. A. Matlin.
Fake science and the knowledge crisis: ignorance can be fatal.
Royal Society Open Science, May 2019.
Quote: "Scientists must be willing to speak out when they see false information being presented in social media, traditional print or broadcast press" and "must speak out against false information and fake science in circulation
and forcefully contradict public figures who promote it."
[FAKE2]
L. Stenflo.
Intelligent plagiarists are the most dangerous. Nature, vol. 427, p. 777 (Feb 2004).
Quote: "What is worse, in my opinion, ..., are cases where scientists rewrite previous findings in different words, purposely hiding the sources of their ideas, and then during subsequent years forcefully claim that they have discovered new phenomena.
[FAST] C. v.d. Malsburg. Tech Report 81-2, Abteilung f. Neurobiologie,
Max-Planck Institut f. Biophysik und Chemie, Goettingen, 1981.
First paper on fast weights or dynamic links.
[FASTa]
J. A. Feldman. Dynamic connections in neural networks.
Biological Cybernetics, 46(1):27-39, 1982.
2nd paper on fast weights.
[FASTb]
G. E. Hinton, D. C. Plaut. Using fast weights to deblur old memories. Proc. 9th annual conference of the Cognitive Science Society (pp. 177-186), 1987.
3rd paper on fast weights (two types of weights with different learning rates).
[FB17]
By 2017, Facebook
used LSTM
to handle
over 4 billion automatic translations per day (The Verge, August 4, 2017);
see also
Facebook blog by J.M. Pino, A. Sidorov, N.F. Ayan (August 3, 2017)
[FDL] J. Schmidhuber (AI Blog, 2013). My First Deep Learning System of 1991 + Deep Learning Timeline 1960-2013.
[FEI63]
E. A. Feigenbaum, J. Feldman. Computers and thought. McGraw-Hill: New York, 1963.
[FEI83]
E. A. Feigenbaum, P. McCorduck. The fifth generation. Addison-Wesley Publishers, 1983.
[FI22]
R. A. Fisher. On the mathematical foundations of theoretical statistics. Philosophical Transactions of the Royal Society of London. Series A, containing papers of a mathematical or physical character; 222.594-604:309-368, 1922.
[FM]
S. Hochreiter and J. Schmidhuber.
Flat minimum search finds simple nets.
Technical Report FKI-200-94, Fakultät für Informatik,
Technische Universität München, December 1994.
PDF.
[FRE] G. Frege (1879).
Begriffsschrift: eine der arithmetischen nachgebildete Formelsprache des reinen Denkens. Halle an der Saale: Verlag Louis Nebert.
The first formal language / formal proofs—basis of modern logic and programming languages.
[FU77]
K. S. Fu. Syntactic Pattern Recognition and Applications. Berlin, Springer, 1977.
[FWP]
J. Schmidhuber (AI Blog, 26 March 2021, updated 2022).
26 March 1991: Neural nets learn to program neural nets with fast weights—like Transformer variants. 2021: New stuff!
30-year anniversary of a now popular
alternative[FWP0-1] to recurrent NNs.
A slow feedforward NN learns by gradient descent to program the changes of
the fast weights[FAST,FASTa,b] of
another NN, separating memory and control like in traditional computers.
Such Fast Weight Programmers[FWP0-6,FWPMETA1-8] can learn to memorize past data, e.g.,
by computing fast weight changes through additive outer products of self-invented activation patterns[FWP0-1]
(now often called keys and values for self-attention[TR1-6]).
The similar Transformers[TR1-2] combine this with projections
and softmax and
are now widely used in natural language processing.
For long input sequences, their efficiency was improved through
Transformers with linearized self-attention[TR5-6]
which are formally equivalent to Schmidhuber's 1991 outer product-based Fast Weight Programmers (apart from normalization).
In 1993, he introduced
the attention terminology[FWP2] now used
in this context,[ATT] and
extended the approach to
RNNs that program themselves.
See tweet of 2022.
[FWP0]
J. Schmidhuber.
Learning to control fast-weight memories: An alternative to recurrent nets.
Technical Report FKI-147-91, Institut für Informatik, Technische
Universität München, 26 March 1991.
PDF.
First paper on fast weight programmers that separate storage and control: a slow net learns by gradient descent to compute weight changes of a fast net. The outer product-based version (Eq. 5) is now known as a "Transformer with linearized self-attention" (apart from normalization).[FWP]
[FWP1] J. Schmidhuber. Learning to control fast-weight memories: An alternative to recurrent nets. Neural Computation, 4(1):131-139, 1992. Based on [FWP0].
PDF.
HTML.
Pictures (German).
See tweet of 2022 for 30-year anniversary.
[FWP2] J. Schmidhuber. Reducing the ratio between learning complexity and number of time-varying variables in fully recurrent nets. In Proceedings of the International Conference on Artificial Neural Networks, Amsterdam, pages 460-463. Springer, 1993.
PDF.
First recurrent NN-based fast weight programmer using outer products, introducing the terminology of learning "internal spotlights of attention."
[FWP3] I. Schlag, J. Schmidhuber. Gated Fast Weights for On-The-Fly Neural Program Generation. Workshop on Meta-Learning, @N(eur)IPS 2017, Long Beach, CA, USA.
[FWP3a] I. Schlag, J. Schmidhuber. Learning to Reason with Third Order Tensor Products. Advances in Neural Information Processing Systems (N(eur)IPS), Montreal, 2018.
Preprint: arXiv:1811.12143. PDF.
[FWP4a] J. Ba, G. Hinton, V. Mnih, J. Z. Leibo, C. Ionescu. Using Fast Weights to Attend to the Recent Past. NIPS 2016.
PDF. Very similar to [FWP0-2], in both motivation [FWP2] and execution.
[FWP4b]
D. Bahdanau, K. Cho, Y. Bengio (2014).
Neural Machine Translation by Jointly Learning to Align and Translate. Preprint arXiv:1409.0473 [cs.CL].
This work on "attention" did not cite Schmidhuber's much earlier original work of 1991-1993 on soft attention and Transformers with linearized self-attention.[FWP,FWP0-2,6][ATT]
[FWP4d]
Y. Tang, D. Nguyen, D. Ha (2020).
Neuroevolution of Self-Interpretable Agents.
Preprint: arXiv:2003.08165.
[FWP5]
F. J. Gomez and J. Schmidhuber.
Evolving modular fast-weight networks for control.
In W. Duch et al. (Eds.):
Proc. ICANN'05,
LNCS 3697, pp. 383-389, Springer-Verlag Berlin Heidelberg, 2005.
PDF.
HTML overview.
Reinforcement-learning fast weight programmer.
[FWP6] I. Schlag, K. Irie, J. Schmidhuber.
Linear Transformers Are Secretly Fast Weight Programmers. ICML 2021. Preprint: arXiv:2102.11174.
[FWP7] K. Irie, I. Schlag, R. Csordas, J. Schmidhuber.
Going Beyond Linear Transformers with Recurrent Fast Weight Programmers.
Preprint: arXiv:2106.06295 (June 2021).
[FWPMETA1] J. Schmidhuber. Steps towards `self-referential' learning. Technical Report CU-CS-627-92, Dept. of Comp. Sci., University of Colorado at Boulder, November 1992.
First recurrent NN-based fast weight programmer that can learn
to run a learning algorithm or weight change algorithm on itself.
[FWPMETA2] J. Schmidhuber. A self-referential weight matrix.
In Proceedings of the International Conference on Artificial
Neural Networks, Amsterdam, pages 446-451. Springer, 1993.
PDF.
[FWPMETA3] J. Schmidhuber.
An introspective network that can learn to run its own weight change algorithm. In Proc. of the Intl. Conf. on Artificial Neural Networks,
Brighton, pages 191-195. IEE, 1993.
[FWPMETA4]
J. Schmidhuber.
A neural network that embeds its own meta-levels.
In Proc. of the International Conference on Neural Networks '93,
San Francisco. IEEE, 1993.
[FWPMETA5]
J. Schmidhuber. Habilitation thesis, TUM, 1993. PDF.
A recurrent neural net with a self-referential, self-reading, self-modifying weight matrix
can be found here.
[FWPMETA6]
L. Kirsch and J. Schmidhuber. Meta Learning Backpropagation & Improving It. Advances in Neural Information Processing Systems (NeurIPS), 2021.
Preprint arXiv:2012.14905 [cs.LG], 2020.
[FWPMETA7]
I. Schlag, T. Munkhdalai, J. Schmidhuber.
Learning Associative Inference Using Fast Weight Memory.
ICLR 2021.
Report arXiv:2011.07831 [cs.AI], 2020.
[FWPMETA8]
K. Irie, I. Schlag, R. Csordas, J. Schmidhuber.
A Modern Self-Referential Weight Matrix That Learns to Modify Itself.
International Conference on Machine Learning (ICML), 2022.
Preprint: arXiv:2202.05780.
[FWPMETA9]
L. Kirsch and J. Schmidhuber.
Self-Referential Meta Learning.
First Conference on Automated Machine Learning (Late-Breaking Workshop), 2022.
[GAU09]
C. F. Gauss. Theoria motus corporum coelestium in sectionibus conicis solem ambientium, 1809.
[GAU21]
C. F. Gauss. Theoria combinationis observationum erroribus minimis obnoxiae (Theory of
the combination of observations least subject to error), 1821.
[G63] R. J Glauber (1963). Time-dependent statistics of the Ising model.
Journal of Mathematical Physics, 4(2):294-307, 1963.
[GD']
C. Lemarechal. Cauchy and the Gradient Method. Doc Math Extra, pp. 251-254, 2012.
[GD'']
J. Hadamard. Memoire sur le probleme d'analyse relatif a Vequilibre des plaques elastiques encastrees. Memoires presentes par divers savants estrangers à l'Academie des Sciences de l'Institut de France, 33, 1908.
[GDa]
Y. Z. Tsypkin (1966). Adaptation, training and self-organization automatic control systems,
Avtomatika I Telemekhanika, 27, 23-61.
On gradient descent-based on-line learning for non-linear systems.
[GDb]
Y. Z. Tsypkin (1971). Adaptation and Learning in Automatic Systems, Academic Press, 1971.
On gradient descent-based on-line learning for non-linear systems.
[GD1]
S. I. Amari (1967).
A theory of adaptive pattern classifier, IEEE Trans, EC-16, 279-307 (Japanese version published in 1965).
PDF.
Probably the first paper on using stochastic gradient descent[STO51-52] for learning in multilayer neural networks
(without specifying the specific gradient descent method now known as reverse mode of automatic differentiation or backpropagation[BP1]).
[GD2]
S. I. Amari (1968).
Information Theory—Geometric Theory of Information, Kyoritsu Publ., 1968 (in Japanese).
OCR-based PDF scan of pages 94-135 (see pages 119-120).
Contains computer simulation results for a five layer network (with 2 modifiable layers) which learns internal representations to classify
non-linearily separable pattern classes.
[GD2a]
H. Saito (1967). Master's thesis, Graduate School of Engineering, Kyushu University, Japan.
Implementation of Amari's 1967 stochastic gradient descent method for multilayer perceptrons.[GD1] (S. Amari, personal communication, 2021.)
[GD3]
S. I. Amari (1977).
Neural Theory of Association and Concept Formation.
Biological Cybernetics, vol. 26, p. 175-185, 1977.
See Section 3.1 on using gradient descent for learning in multilayer networks.
[GGP]
F. Faccio, V. Herrmann, A. Ramesh, L. Kirsch, J. Schmidhuber.
Goal-Conditioned Generators of Deep Policies.
Preprint arXiv/2207.01570, 4 July 2022 (submitted in May 2022).
[GLA85] W. Glasser. Control theory. New York: Harper and Row, 1985.
[GM3]
J. Schmidhuber (2003).
Gödel Machines: Self-Referential Universal Problem Solvers Making Provably Optimal Self-Improvements.
Preprint
arXiv:cs/0309048 (2003).
More.
[GM6]
J. Schmidhuber (2006).
Gödel machines:
Fully Self-Referential Optimal Universal Self-Improvers.
In B. Goertzel and C. Pennachin, eds.: Artificial
General Intelligence, p. 199-226, 2006.
PDF.
[GM9]
J. Schmidhuber (2009).
Ultimate Cognition à la Gödel.
Cognitive Computation 1(2):177-193, 2009. PDF.
More.
[GSR]
H. Sak, A. Senior, K. Rao, F. Beaufays, J. Schalkwyk—Google Speech Team.
Google voice search: faster and more accurate.
Google Research Blog, Sep 2015, see also
Aug 2015 Google's speech recognition based on CTC and LSTM.
[GSR15] Dramatic
improvement of Google's speech recognition through LSTM:
Alphr Technology, Jul 2015, or 9to5google, Jul 2015
[GSR19]
Y. He, T. N. Sainath, R. Prabhavalkar, I. McGraw, R. Alvarez, D. Zhao, D. Rybach, A. Kannan, Y. Wu, R. Pang, Q. Liang, D. Bhatia, Y. Shangguan, B. Li, G. Pundak, K. Chai Sim, T. Bagby, S. Chang, K. Rao, A. Gruenstein.
Streaming end-to-end speech recognition for mobile devices. ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019.
[GT16] Google's
dramatically improved Google Translate of 2016 is based on LSTM, e.g.,
WIRED, Sep 2016,
or
siliconANGLE, Sep 2016
[GAN0]
O. Niemitalo. A method for training artificial neural networks to generate missing data within a variable context.
Blog post, Internet Archive, 2010.
A blog post describing basic ideas[AC][AC90,AC90b][AC20] of GANs.
[GAN1]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair,
A. Courville, Y. Bengio.
Generative adversarial nets. NIPS 2014, 2672-2680, Dec 2014.
A description of GANs that does not cite Schmidhuber's original GAN principle of 1990[AC][AC90,AC90b][AC20][R2][T22] (also containing wrong claims about Schmidhuber's adversarial NNs for Predictability Minimization[PM0-2][AC20][T22]).
[GAN2]
T. Karras, S. Laine, T. Aila. A style-based generator architecture for generative adversarial
networks. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages
4401-4410, 2019.
[GOD]
K. Gödel. Über formal unentscheidbare Sätze der Principia Mathematica und verwandter Systeme I. Monatshefte für Mathematik und Physik, 38:173-198, 1931.
In the early 1930s,
Gödel founded theoretical computer science. He identified fundamental limits of mathematics, theorem proving, computing, and Artificial Intelligence.
[GOD34]
K. Gödel (1934).
On undecidable propositions of formal mathematical
systems. Notes by S. C. Kleene and J. B. Rosser on lectures
at the Institute for Advanced Study, Princeton, New Jersey, 1934, 30
pp. (Reprinted in M. Davis, (ed.), The Undecidable. Basic Papers on Undecidable
Propositions, Unsolvable Problems, and Computable Functions,
Raven Press, Hewlett, New York, 1965.)
Gödel introduced a universal coding language.
[GOD56]
R. J. Lipton and K. W. Regan.
Gödel's lost letter and P=NP.
Link.
Gödel identified what's now the most famous open problem of computer science.
[GOD86]
K. Gödel.
Collected works Volume I: Publications 1929-36,
S. Feferman et. al., editors, Oxford Univ. Press, Oxford, 1986.
[GOD10]
V. C. Nadkarni.
Gödel, Einstein and proof for God. The Economic Times, 2010.
[GOD21] J. Schmidhuber (2021). 90th anniversary celebrations: 1931: Kurt Gödel, founder of theoretical computer science,
shows limits of math, logic, computing, and artificial intelligence.
This was number 1 on Hacker News.
[GOD21a]
J. Schmidhuber (2021). Als Kurt Gödel die Grenzen des Berechenbaren entdeckte.
(When Kurt Gödel discovered the limits of computability.)
Frankfurter Allgemeine Zeitung, 16/6/2021.
[GOD21b]
J. Schmidhuber (AI Blog, 2021). 80. Jahrestag: 1931: Kurt Gödel, Vater der theoretischen Informatik, entdeckt die Grenzen des Berechenbaren und der künstlichen Intelligenz.
[GOL]
C. Goller & A. Küchler (1996). Learning task-dependent distributed representations by backpropagation through structure. Proceedings of International Conference on Neural Networks (ICNN'96). Vol. 1, p. 347-352 IEEE, 1996.
Based on TR AR-95-02, TU Munich, 1995.
[GPT3]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, D. Amodei.
Language Models are Few-Shot Learners (2020).
Preprint arXiv/2005.14165.
[GPUNN]
Oh, K.-S. and Jung, K. (2004). GPU implementation of neural networks. Pattern Recognition, 37(6):1311-1314. Speeding up traditional NNs on GPU by a factor of 20.
[GPUCNN]
K. Chellapilla, S. Puri, P. Simard. High performance convolutional neural networks for document processing. International Workshop on Frontiers in Handwriting Recognition, 2006. Speeding up shallow CNNs on GPU by a factor of 4.
[GPUCNN1] D. C. Ciresan, U. Meier, J. Masci, L. M. Gambardella, J. Schmidhuber. Flexible, High Performance Convolutional Neural Networks for Image Classification. International Joint Conference on Artificial Intelligence (IJCAI-2011, Barcelona), 2011. PDF. ArXiv preprint.
Speeding up deep CNNs on GPU by a factor of 60.
Used to
win four important computer vision competitions 2011-2012 before others won any
with similar approaches.
[GPUCNN2] D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber.
A Committee of Neural Networks for Traffic Sign Classification.
International Joint Conference on Neural Networks (IJCNN-2011, San Francisco), 2011.
PDF.
HTML overview.
First superhuman performance in a computer vision contest, with half the error rate of humans, and one third the error rate of the closest competitor.[DAN1] This led to massive interest from industry.
[GPUCNN3] D. C. Ciresan, U. Meier, J. Schmidhuber. Multi-column Deep Neural Networks for Image Classification. Proc. IEEE Conf. on Computer Vision and Pattern Recognition CVPR 2012, p 3642-3649, July 2012. PDF. Longer TR of Feb 2012: arXiv:1202.2745v1 [cs.CV]. More.
[GPUCNN3a]
D. Ciresan, A. Giusti, L. Gambardella, J. Schmidhuber. Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images. NIPS 2012, Lake Tahoe, 2012.
[GPUCNN4] A. Krizhevsky, I. Sutskever, G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. NIPS 25, MIT Press, Dec 2012.
PDF.
This paper describes AlexNet, which is similar to the earlier
DanNet,[DAN,DAN1][R6]
the first pure deep CNN
to win computer vision contests in 2011[GPUCNN2-3,5] (AlexNet and VGG Net[GPUCNN9] followed in 2012-2014). [GPUCNN4] emphasizes benefits of Fukushima's ReLUs (1969)[RELU1] and dropout (a variant of Hanson 1990 stochastic delta rule)[Drop1-4] but neither cites the original work[RELU1][Drop1] nor the basic CNN architecture (Fukushima, 1979).[CNN1]
[GPUCNN5]
J. Schmidhuber (AI Blog, 2017; updated 2021 for 10th birthday of DanNet): History of computer vision contests won by deep CNNs since 2011. DanNet was the first CNN to win one, and won 4 of them in a row before the similar AlexNet/VGG Net and the Resnet (a Highway Net with open gates) joined the party. Today, deep CNNs are standard in computer vision.
[GPUCNN6] J. Schmidhuber, D. Ciresan, U. Meier, J. Masci, A. Graves. On Fast Deep Nets for AGI Vision. In Proc. Fourth Conference on Artificial General Intelligence (AGI-11), Google, Mountain View, California, 2011.
PDF.
[GPUCNN7] D. C. Ciresan
, A. Giusti, L. M. Gambardella, J. Schmidhuber. Mitosis Detection in Breast Cancer Histology Images using Deep Neural Networks. MICCAI 2013.


 This answer is used by the technique of gradient descent (GD), apparently first proposed by Augustin-Louis Cauchy in 1847
This answer is used by the technique of gradient descent (GD), apparently first proposed by Augustin-Louis Cauchy in 1847










 Computer Vision was revolutionized in
Computer Vision was revolutionized in