Abstract.
In 2020, we celebrated the
30-year anniversary of our papers on
planning & reinforcement learning (RL) with artificial neural networks (NNs) [AC90][PLAN2].
In 2025, everyone is suddenly talking about Real AI (or Physical AI) for real robots in the real world,
building on the foundations laid in 1990.
The technical report
FKI-126-90 introduced several concepts that are now widely used:
(1) planning with recurrent NNs (RNNs) as world models,
(2) high-dimensional reward signals (also as inputs for a neural controller),
(3) deterministic policy gradients for RNNs,
(4) Artificial Curiosity [AC90b] and intrinsic motivation through what's now called
Generative Adversarial Networks
[AC20].
In the 2010s, these concepts
became popular as
compute became cheaper. Our more recent extensions since 2015 address
planning in abstract concept spaces and learning to think through RL prompt engineers [PLAN4-6].
Agents with adaptive recurrent
world models even suggest a simple explanation of consciousness and self-awareness (dating back to 1991 [CON16]).
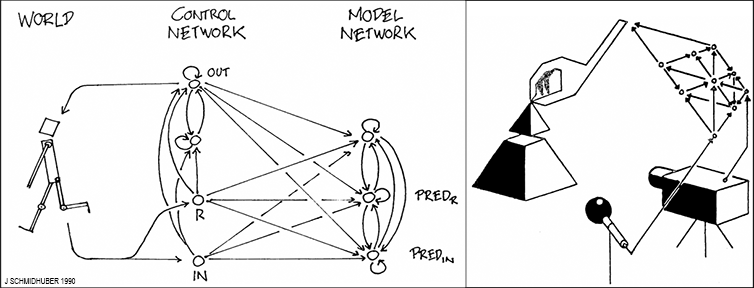
I drew the illustrations of [AC90] by hand—some of them are shown here.
 In February 1990, I published the Technical Report FKI-126-90 [AC90] (revised in November)
which introduced several concepts that have become popular in the field of Machine Learning.
In February 1990, I published the Technical Report FKI-126-90 [AC90] (revised in November)
which introduced several concepts that have become popular in the field of Machine Learning.
The report described a system for reinforcement learning (RL) and planning based on a combination of two
recurrent neural networks (RNNs) called the controller and the world model [AC90]. The controller tries to maximize cumulative expected reward in an initially unknown environment. The world model learns to predict the consequences of the controller's actions. The controller can use the world model to plan ahead for several time steps through what's now called a rollout, selecting action sequences that maximise predicted cumulative reward [AC90][PLAN2].
This integrated architecture for learning, planning, and reacting was apparently published
[AC90][PLAN2]
before Rich Sutton's DYNA [DYNA90][DYNA91][LEC].
[AC90] also cites work on
system identification with feedforward
NNs [WER87-89][MUN87][NGU89][JOR90] older than the references given in recent work [LEC]—compare [DL1].
The approach led to lots of follow-up publications, not only
in 1990-91 [PLAN2-3][PHD],
but also in recent years, e.g., [PLAN4-6].
See also Sec. 11 of [MIR]
and our 1990 application of world models to the
learning of sequential attention
[ATT][ATT0-2].
 Another novelty of 1990 was the concept of
high-dimensional reward signals.
Traditional RL has focused on one-dimensional reward signals.
Humans, however, have millions of informative sensors for different types of pain and pleasure etc.
To my knowledge, reference [AC90] was the first paper on RL with
multi-dimensional, vector-valued pain and reward signals coming in through
many different sensors,
where cumulative values are predicted for all those sensors,
not just for a single scalar overall reward.
Compare what was later called a general value function
[GVF].
Unlike previous adaptive critics, the one of 1990 [AC90]
was multi-dimensional and recurrent.
Another novelty of 1990 was the concept of
high-dimensional reward signals.
Traditional RL has focused on one-dimensional reward signals.
Humans, however, have millions of informative sensors for different types of pain and pleasure etc.
To my knowledge, reference [AC90] was the first paper on RL with
multi-dimensional, vector-valued pain and reward signals coming in through
many different sensors,
where cumulative values are predicted for all those sensors,
not just for a single scalar overall reward.
Compare what was later called a general value function
[GVF].
Unlike previous adaptive critics, the one of 1990 [AC90]
was multi-dimensional and recurrent.
Unlike in traditional RL,
those reward signals were also used as informative inputs to the controller NN
learning to execute actions that maximise cumulative reward.
This is also essential for metalearning, because any machine that learns a new learning algorithm for maximizing reward or minimizing error must somehow see this reward/error in its inputs—otherwise, a newly generated learning algorithm running on that machine will not know which objective function to optimize.
Compare Sec. 13 of [MIR]
and Sec. 5 of [DEC] and
Sec. 3 & Sec. 6
of [META].
 Are such techniques applicable in the real world? For example,
can NNs successfully plan to steer real robots in the physical world (what's now called "Physical AI")? Yes, they can.
For example, my former postdoc Alexander Gloye-Förster
led FU Berlin's FU-Fighters team that became robocup world champion 2004 in the fastest league (robot speed up to 5m/s) [RES5].
Their robocup robots planned ahead with neural nets, in line with the ideas
outlined in [AC90].
Are such techniques applicable in the real world? For example,
can NNs successfully plan to steer real robots in the physical world (what's now called "Physical AI")? Yes, they can.
For example, my former postdoc Alexander Gloye-Förster
led FU Berlin's FU-Fighters team that became robocup world champion 2004 in the fastest league (robot speed up to 5m/s) [RES5].
Their robocup robots planned ahead with neural nets, in line with the ideas
outlined in [AC90].
In 2005, Alexander and his team
also showed how such concepts can be used to build so-called
self-healing robots [RES5][RES7].
They constructed the first resilient machines using continuous self-modeling. Their robots could autonomously recover from certain types of unexpected damage, through adaptive self-models derived from actuation-sensation relationships, used to generate forward locomotion.
The 1990 FKI tech report [AC90] also described basics of
deterministic policy gradients for RNNs.
Its section "Augmenting the Algorithm by Temporal Difference Methods"
combined the Dynamic Programming-based
Temporal Difference method [TD] for predicting cumulative (possibly multi-dimensional) rewards
with a gradient-based predictive
model of the world,
to compute weight changes for the separate control network.
See also Sec. 2.4 of the 1991 follow-up paper [PLAN3]
(and compare [NAN1-5]).
Variants of this were used a
quarter century later by DeepMind [DPG]
[DDPG], the company co-founded by a student from my lab,
now the core of Google.
See also Sec. 14 of [MIR]
and and Sec. 5 of [DEC].
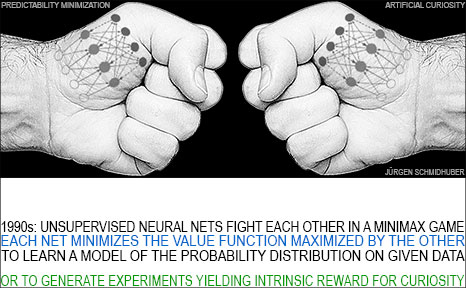 Finally, the 1990 paper also introduced
Intrinsic Motivation and Artificial Curiosity through Generative Adversarial Networks [AC20][AC].
As humans interact with the world, they learn to predict the consequences of their actions. They are also curious, designing experiments that lead to novel data from which they can learn more.
To build curious artificial agents, the papers [AC90, AC90b] introduced
a new type of active unsupervised or self-supervised learning with intrinsic motivation.
It is based on a
minimax game where one neural net (NN) minimizes the objective function maximized
by another NN [R2].
Today, I refer to
this duel between two unsupervised adversarial NNs as Adversarial Artificial Curiosity [AC20],
to distinguish it from our later types of Artificial Curiosity and intrinsic motivation since 1991 [AC][AC91b-AC20][PP-PP2].
Finally, the 1990 paper also introduced
Intrinsic Motivation and Artificial Curiosity through Generative Adversarial Networks [AC20][AC].
As humans interact with the world, they learn to predict the consequences of their actions. They are also curious, designing experiments that lead to novel data from which they can learn more.
To build curious artificial agents, the papers [AC90, AC90b] introduced
a new type of active unsupervised or self-supervised learning with intrinsic motivation.
It is based on a
minimax game where one neural net (NN) minimizes the objective function maximized
by another NN [R2].
Today, I refer to
this duel between two unsupervised adversarial NNs as Adversarial Artificial Curiosity [AC20],
to distinguish it from our later types of Artificial Curiosity and intrinsic motivation since 1991 [AC][AC91b-AC20][PP-PP2].
How does Adversarial Artificial Curiosity work?
The controller NN (probabilistically) generates outputs that may influence an environment. The world model NN predicts the environmental reactions to the controller's outputs.
Using gradient descent, the world model minimizes its error, thus becoming a better predictor. But in a zero sum game, the controller tries to find outputs that maximize the error of the world model, whose loss is the gain of the controller.
Hence the controller is motivated to invent novel outputs or experiments that yield data that the world model still finds surprising, until the data becomes familiar and eventually boring. Compare more recent summaries and extensions of this
now popular principle, e.g., [AC09].
That is, in 1990, we already had
self-supervised neural nets that were both
generative and adversarial
(using much later terminology from 2014 [GAN1][R2]),
generating experimental outputs yielding novel data,
not only for stationary
patterns but also for pattern sequences, and even for the general case of
RL.
In fact, more recent examples of
Generative Adversarial Networks (GANs)
[GAN1] (2010-2014)
are an application of Adversarial Curiosity [AC90] where the
environment simply returns 1 or 0 depending on whether the controller's current output is in a
given set [AC20][R2][LEC][MOST][DLP].
See also Sec. 5 of [MIR],
Sec. 4 of [DEC], and
Sec. XVII of [T22].
BTW, note that Adversarial Curiosity [AC90, AC90b] & GANs [GAN0-1]
& our Adversarial Predictability
Minimization (1991) [PM1-2] are
very different from other
early adversarial machine learning settings [S59][H90]
which
neither involved unsupervised NNs nor were about modeling data nor used gradient descent [AC20].
As I have frequently pointed out since 1990 [AC90],
the weights of an NN should be viewed as its program.
Some argue that the goal of a deep NN is to learn useful internal representations of
observed data—there is even an International Conference on Learning Representations called ICLR.
But actually
the NN is learning a program (the weights or parameters of a mapping)
that computes such representations in response to the input data.
The outputs of typical NNs are differentiable with respect to their programs.
That is, a simple program generator
can compute a direction in program space where one may find a better program [AC90].
Much of my work since 1989 has exploited this fact.
See also Sec. 18 of [MIR].
The original controller/model (C/M) planner of 1990 [AC90] focused on naive "millisecond by millisecond planning," trying to predict and plan every little detail of its possible futures. Even today, this is
still a standard approach in many RL applications, e.g., RL for board games such as Chess and Go.
My more recent work of 2015, however, has
focused on abstract (e.g., hierarchical) planning and reasoning [PLAN4-5].
Guided by
algorithmic information theory, I described RNN-based AIs (RNNAIs) that can be trained on never-ending sequences of tasks, some of them provided by the user, others invented by the RNNAI itself in a curious, playful fashion, to improve its RNN-based world model. Unlike the system of 1990 [AC90], the RNNAI [PLAN4] learns to actively query its model for abstract reasoning and planning and decision making, essentially learning to think [PLAN4].
More specifically, the reinforcement learning prompt engineer in Sec. 5.3 of the 2015 paper [PLAN4] describes how C learns to send prompt sequences into M (e.g., a foundation model) trained on, say, videos of actors. C also learns to interpret answers of M, extracting algorithmic information from M. The acid test is this: does C learn its control tasks faster with M than without? Is it cheaper to learn C's tasks from scratch, or to address algorithmic info in M in some computable way, enabling things such as abstract hierarchical planning and reasoning?
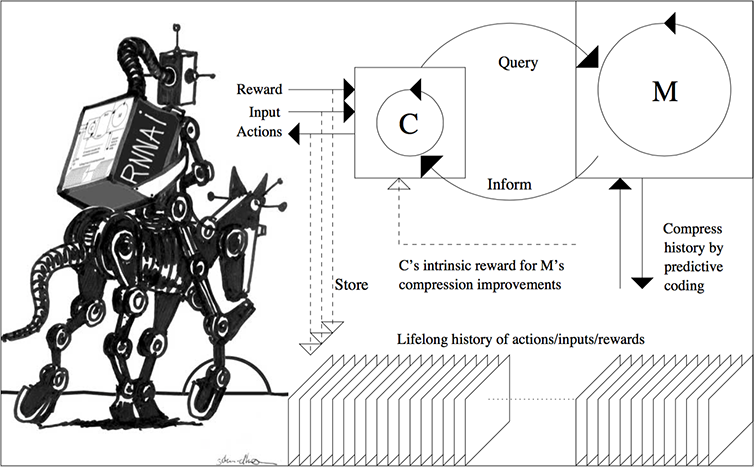
The 2018 paper [PLAN5] collapses C and M into a single network, using the
neural network distillation procedure
of 1991 [UN-UN2][DLH][DLP]. See the illustration below and this tweet of 2023.

In January 2025, the DeepSeek "Sputnik" [DS1] wiped out a trillion USD from the stock market. DeepSeek-R1 [DS1] uses elements of my 2015 reinforcement learning (RL) prompt engineer [PLAN4] and its 2018 refinement [PLAN5] which collapses the 2015 RL machine and its world model [PLAN4] into a single net through the neural net distillation procedure of 1991 [UN0-3][UN][DLP]: a distilled chain of thought system. See the popular tweet of 31 Jan 2025.
Compare also our recent related work on learning (hierarchically) structured
concept spaces based on abstract objects [OBJ2-5].
The ideas of [PLAN4-5] can be applied to many other cases where one RNN-like system exploits the algorithmic information content of another. They also explain concepts such as mirror neurons [PLAN4].
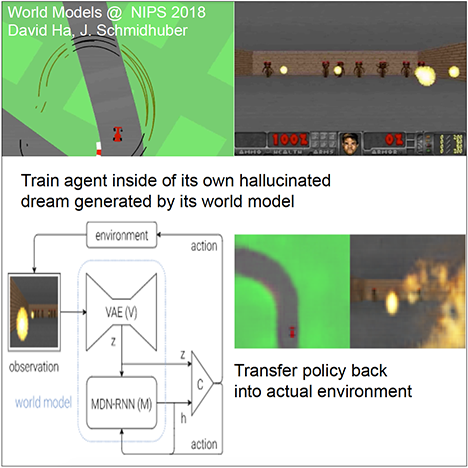 In
work with David Ha
of Google (2018) [PLAN6],
a world model extracts compressed spatio-temporal representations which are fed into compact and simple policies trained by evolution, achieving state of the art results in various environments.
In
work with David Ha
of Google (2018) [PLAN6],
a world model extracts compressed spatio-temporal representations which are fed into compact and simple policies trained by evolution, achieving state of the art results in various environments.
Finally, what does all of this have to do with the seemingly elusive
concepts of consciousness and self-awareness? My
first deep learning machine
of 1991
[UN-UN3][NOB] emulates aspects of consciousness as follows.
It uses
unsupervised learning and predictive coding
[UN0-UN3][SNT] to compress observation sequences.
A so-called "conscious chunker RNN" attends to unexpected events that surprise
a lower-level so-called "subconscious automatiser RNN."
The chunker RNN learns to "understand" the surprising events by predicting them.
The automatiser RNN uses a neural
knowledge distillation procedure
of 1991
[UN-UN2][DLP]
(see Sec. 2 of [MIR])
to compress and absorb the formerly "conscious" insights and
behaviours of the chunker RNN, thus making them "subconscious."
 Let us now look at the predictive world model of a controller interacting with an environment as discussed above.
It also learns to efficiently encode the growing history of actions and observations
through predictive coding [UN0-UN3][SNT].
It automatically creates feature hierarchies, lower level neurons corresponding to simple feature detectors (perhaps similar to those found in mammalian brains), higher layer neurons typically corresponding to more abstract features, but fine-grained where necessary. Like any good compressor, the world model will learn to identify regularities shared by existing internal data structures, and generate prototype encodings (across neuron populations) or
compact representations or "symbols" (not necessarily discrete)
for frequently occurring observation sub-sequences, to shrink the storage space needed for the whole. In particular, compact self-representations or
self-symbols
are natural by-products of the data compression process, since there is one thing that is involved in all actions and sensory inputs of the agent, namely, the agent itself. To efficiently encode the entire data history through predictive coding, it will profit from creating some sort of internal sub-network of connected neurons computing neural activation patterns representing itself
[CATCH][AC10].
Whenever this representation becomes activated
through the controller's planning mechanism of 1990 [AC90][PLAN2],
or through more flexible controller
queries of 2015 [PLAN4],
the agent is thinking about itself, being aware of itself and its alternative possible futures, trying to create a future of minimal pain and maximal pleasure through interaction with its environment.
That's why I keep claiming that we have had simple, conscious, self-aware, emotional, artificial agents since 1991 [CON16].
Let us now look at the predictive world model of a controller interacting with an environment as discussed above.
It also learns to efficiently encode the growing history of actions and observations
through predictive coding [UN0-UN3][SNT].
It automatically creates feature hierarchies, lower level neurons corresponding to simple feature detectors (perhaps similar to those found in mammalian brains), higher layer neurons typically corresponding to more abstract features, but fine-grained where necessary. Like any good compressor, the world model will learn to identify regularities shared by existing internal data structures, and generate prototype encodings (across neuron populations) or
compact representations or "symbols" (not necessarily discrete)
for frequently occurring observation sub-sequences, to shrink the storage space needed for the whole. In particular, compact self-representations or
self-symbols
are natural by-products of the data compression process, since there is one thing that is involved in all actions and sensory inputs of the agent, namely, the agent itself. To efficiently encode the entire data history through predictive coding, it will profit from creating some sort of internal sub-network of connected neurons computing neural activation patterns representing itself
[CATCH][AC10].
Whenever this representation becomes activated
through the controller's planning mechanism of 1990 [AC90][PLAN2],
or through more flexible controller
queries of 2015 [PLAN4],
the agent is thinking about itself, being aware of itself and its alternative possible futures, trying to create a future of minimal pain and maximal pleasure through interaction with its environment.
That's why I keep claiming that we have had simple, conscious, self-aware, emotional, artificial agents since 1991 [CON16].
Acknowledgments
 Thanks to several expert reviewers for useful comments. Since science is about self-correction, let me know under juergen@idsia.ch if you can spot any remaining error. The contents of this article may be used for educational and non-commercial purposes, including articles for Wikipedia and similar sites. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Thanks to several expert reviewers for useful comments. Since science is about self-correction, let me know under juergen@idsia.ch if you can spot any remaining error. The contents of this article may be used for educational and non-commercial purposes, including articles for Wikipedia and similar sites. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
References
[AC]
J. Schmidhuber (AI Blog, 2021). 3 decades of artificial curiosity & creativity. Our artificial scientists not only answer given questions but also invent new questions. They achieve curiosity through: (1990) the principle of generative adversarial networks, (1991) neural nets that maximise learning progress, (1995) neural nets that maximise information gain (optimally since 2011), (1997) adversarial design of surprising computational experiments, (2006) maximizing compression progress like scientists/artists/comedians do, (2011) PowerPlay... Since 2012: applications to real robots.
[AC90]
J. Schmidhuber.
Making the world differentiable: On using fully recurrent
self-supervised neural networks for dynamic reinforcement learning and
planning in non-stationary environments.
Technical Report FKI-126-90, TUM, Feb 1990, revised Nov 1990.
PDF
[AC90b]
J. Schmidhuber.
A possibility for implementing curiosity and boredom in
model-building neural controllers.
In J. A. Meyer and S. W. Wilson, editors, Proc. of the
International Conference on Simulation
of Adaptive Behavior: From Animals to
Animats, pages 222-227. MIT Press/Bradford Books, 1991.
PDF.
HTML.
[AC91]
J. Schmidhuber. Adaptive confidence and adaptive curiosity. Technical Report FKI-149-91, Inst. f. Informatik, Tech. Univ. Munich, April 1991.
PDF.
[AC91b]
J. Schmidhuber.
Curious model-building control systems.
In Proc. International Joint Conference on Neural Networks,
Singapore, volume 2, pages 1458-1463. IEEE, 1991.
PDF.
[AC95]
J. Storck, S. Hochreiter, and J. Schmidhuber. Reinforcement-driven information acquisition in non-deterministic environments. In Proc. ICANN'95, vol. 2, pages 159-164. EC2 & CIE, Paris, 1995. PDF.
[AC97]
J. Schmidhuber.
What's interesting?
Technical Report IDSIA-35-97, IDSIA, July 1997.
Focus
on automatic creation of predictable internal
abstractions of complex spatio-temporal events:
two competing, intrinsically motivated agents agree on essentially
arbitrary algorithmic experiments and bet
on their possibly surprising (not yet predictable)
outcomes in zero-sum games,
each agent potentially profiting from outwitting / surprising
the other by inventing experimental protocols where both
modules disagree on the predicted outcome. The focus is on exploring
the space of general algorithms (as opposed to
traditional simple mappings from inputs to
outputs); the
general system
focuses on the interesting
things by losing interest in both predictable and
unpredictable aspects of the world. Unlike our previous
systems with intrinsic motivation,[AC90-AC95] the system also
takes into account
the computational cost of learning new skills, learning when to learn and what to learn.
See later publications.[AC99][AC02]
[AC99]
J. Schmidhuber.
Artificial Curiosity Based on Discovering Novel Algorithmic
Predictability Through Coevolution.
In P. Angeline, Z. Michalewicz, M. Schoenauer, X. Yao, Z.
Zalzala, eds., Congress on Evolutionary Computation, p. 1612-1618,
IEEE Press, Piscataway, NJ, 1999.
[AC02]
J. Schmidhuber.
Exploring the Predictable.
In Ghosh, S. Tsutsui, eds., Advances in Evolutionary Computing,
p. 579-612, Springer, 2002.
PDF.
[AC06]
J. Schmidhuber.
Developmental Robotics,
Optimal Artificial Curiosity, Creativity, Music, and the Fine Arts.
Connection Science, 18(2): 173-187, 2006.
PDF.
[AC09]
J. Schmidhuber. Art & science as by-products of the search for novel patterns, or data compressible in unknown yet learnable ways. In M. Botta (ed.), Et al. Edizioni, 2009, pp. 98-112.
PDF. (More on
artificial scientists and artists.)
[AC10]
J. Schmidhuber. Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990-2010). IEEE Transactions on Autonomous Mental Development, 2(3):230-247, 2010.
IEEE link.
PDF.
[AC20]
J. Schmidhuber. Generative Adversarial Networks are Special Cases of Artificial Curiosity (1990) and also Closely Related to Predictability Minimization (1991).
Neural Networks, Volume 127, p 58-66, 2020.
Preprint arXiv/1906.04493.
[ATT] J. Schmidhuber (AI Blog, 2020). 30-year anniversary of end-to-end differentiable sequential neural attention. Plus goal-conditional reinforcement learning.We had both hard attention (1990) and soft attention (1991-93).[FWP][ULTRA] Today, both types are very popular.
[ATT0] J. Schmidhuber and R. Huber.
Learning to generate focus trajectories for attentive vision.
Technical Report FKI-128-90, Institut für Informatik, Technische
Universität München, 1990.
PDF.
[ATT1] J. Schmidhuber and R. Huber. Learning to generate artificial fovea trajectories for target detection. International Journal of Neural Systems, 2(1 & 2):135-141, 1991. Based on TR FKI-128-90, TUM, 1990.
PDF.
More.
[ATT2]
J. Schmidhuber.
Learning algorithms for networks with internal and external feedback.
In D. S. Touretzky, J. L. Elman, T. J. Sejnowski, and G. E. Hinton,
editors, Proc. of the 1990 Connectionist Models Summer School, pages
52-61. San Mateo, CA: Morgan Kaufmann, 1990.
PS. (PDF.)
[CATCH]
J. Schmidhuber. Philosophers & Futurists, Catch Up! Response to The Singularity.
Journal of Consciousness Studies, Volume 19, Numbers 1-2, pp. 173-182(10), 2012.
PDF.
[CON16]
J. Carmichael (2016).
Artificial Intelligence Gained Consciousness in 1991.
Why A.I. pioneer Jürgen Schmidhuber is convinced the ultimate breakthrough already happened.
Inverse, 2016. Link.
[DDPG]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, D. Wierstra.
Continuous control with deep reinforcement learning.
Preprint arXiv:1509.02971, 2015.
[DEC] J. Schmidhuber (AI Blog, 02/20/2020, revised 2021). The 2010s: Our Decade of Deep Learning / Outlook on the 2020s. The recent decade's most important developments and industrial applications based on our AI, with an outlook on the 2020s, also addressing privacy and data markets.
[DL1] J. Schmidhuber, 2015.
Deep Learning in neural networks: An overview. Neural Networks, 61, 85-117.
More.
[DL2] J. Schmidhuber, 2015.
Deep Learning.
Scholarpedia, 10(11):32832.
[DL4] J. Schmidhuber, 2017. Our impact on the world's most valuable public companies: 1. Apple, 2. Alphabet (Google), 3. Microsoft, 4. Facebook, 5. Amazon ...
HTML.
[DLH]
J. Schmidhuber (AI Blog, 2022).
Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, IDSIA, Lugano, Switzerland, 2022.
Preprint arXiv:2212.11279.
Tweet of 2022.
[DLP]
J. Schmidhuber (AI Blog, 2023).
How 3 Turing awardees republished key methods and ideas whose creators they failed to credit.
Technical Report IDSIA-23-23, Swiss AI Lab IDSIA, 14 Dec 2023.
The piece is aimed at people who are not aware of the numerous AI priority disputes, but are willing to check the facts (see tweet).
[DS1]
DeepSeek-AI (2025).
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. Preprint arXiv:2501.12948. See the popular DeepSeek tweet of Jan 2025.
[DPG]
D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, M. Riedmiller. Deterministic policy gradient algorithms.
Proceedings of ICML'31, Beijing, China, 2014. JMLR: W&CP volume 32.
[DYNA90]
R. S. Sutton (1990). Integrated Architectures for Learning, Planning, and Reacting Based on Approximating Dynamic Programming. Machine Learning Proceedings 1990, of the Seventh International Conference, Austin, Texas, June 21-23,
1990, p 216-224.
[DYNA91]
R. S. Sutton (1991). Dyna, an integrated architecture for learning, planning, and reacting. ACM Sigart Bulletin 2.4 (1991):160-163.
[FWP]
J. Schmidhuber (AI Blog, 26 March 2021, updated 2025).
26 March 1991: Neural nets learn to program neural nets with fast weights—like Transformer variants. 2021: New stuff!
30-year anniversary of a now popular
alternative[FWP0-1] to recurrent NNs.
A slow feedforward NN learns by gradient descent to program the changes of
the fast weights[FAST,FASTa] of
another NN, separating memory and control like in traditional computers.
Such Fast Weight Programmers[FWP0-6,FWPMETA1-8] can learn to memorize past data, e.g.,
by computing fast weight changes through additive outer products of self-invented activation patterns[FWP0-1]
(now often called keys and values for self-attention[TR1-6]).
The similar Transformers[TR1-2] combine this with projections
and softmax and
are now widely used in natural language processing.
For long input sequences, their efficiency was improved through
Transformers with linearized self-attention[TR5-6]
which are formally equivalent to Schmidhuber's 1991 outer product-based Fast Weight Programmers (apart from normalization), now called unnormalized linear Transformers.[ULTRA]
In 1993, he introduced
the attention terminology[FWP2] now used
in this context,[ATT] and
extended the approach to
RNNs that program themselves.
See tweet of 2022.
[FWP0]
J. Schmidhuber.
Learning to control fast-weight memories: An alternative to recurrent nets.
Technical Report FKI-147-91, Institut für Informatik, Technische
Universität München, 26 March 1991.
PDF.
First paper on fast weight programmers that separate storage and control: a slow net learns by gradient descent to compute weight changes of a fast net. The outer product-based version (Eq. 5) is now known as an unnormalized linear Transformer or "Transformer with linearized self-attention."[FWP]
[FWP1] J. Schmidhuber. Learning to control fast-weight memories: An alternative to recurrent nets. Neural Computation, 4(1):131-139, 1992. Based on [FWP0].
PDF.
HTML.
Pictures (German).
See tweet of 2022 for 30-year anniversary.
[FWP2] J. Schmidhuber. Reducing the ratio between learning complexity and number of time-varying variables in fully recurrent nets. In Proceedings of the International Conference on Artificial Neural Networks, Amsterdam, pages 460-463. Springer, 1993.
PDF.
First recurrent NN-based fast weight programmer using outer products (a recurrent extension of the 1991 unnormalized linear Transformer), introducing the terminology of learning "internal spotlights of attention."
[FWP6] I. Schlag, K. Irie, J. Schmidhuber.
Linear Transformers Are Secretly Fast Weight Programmers. ICML 2021. Preprint: arXiv:2102.11174.
[GAN0]
O. Niemitalo. A method for training artificial neural networks to generate missing data within a variable context.
Blog post, Internet Archive, 2010
[GAN1]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair,
A. Courville, Y. Bengio.
Generative adversarial nets. NIPS 2014, 2672-2680, Dec 2014.
[GVF]
R. Sutton, J. Modayil, M. Delp, T. De-gris, P. M. Pilarski, A. White, AD. Precup. Horde: A scalable real-time architecture for learning knowledge from unsupervised sensorimotor interaction. 10th International Conference on Autonomous Agents and Multiagent Systems-Volume 2, pp.761-768, 2011.
[H90]
W. D. Hillis.
Co-evolving parasites improve simulated evolution as an optimization
procedure.
Physica D: Nonlinear Phenomena, 42(1-3):228-234, 1990.
[JOR90]
M. I. Jordan and D. E. Rumelhart. Supervised learning with a distal teacher. Technical Report, Massachusetts Institute of Technology, 1990.
[LEC] J. Schmidhuber (AI Blog, 2022). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015. Years ago we published most of what LeCun calls his "main original contributions:" neural nets that learn multiple time scales and levels of abstraction, generate subgoals, use intrinsic motivation to improve world models, and plan (1990); controllers that learn informative predictable representations (1997), etc. This was also discussed on Hacker News, reddit, and various media.
[META]
J. Schmidhuber (AI Blog, 2020). 1/3 century anniversary of
first publication on metalearning machines that learn to learn (1987).
For its cover I drew a robot that bootstraps itself.
1992-: gradient descent-based neural metalearning. 1994-: Meta-Reinforcement Learning with self-modifying policies. 1997: Meta-RL plus artificial curiosity and intrinsic motivation.
2002-: asymptotically optimal metalearning for curriculum learning. 2003-: mathematically optimal Gödel Machine. 2020: new stuff!
[MIR] J. Schmidhuber (AI Blog, Oct 2019, updated 2025). Deep Learning: Our Miraculous Year 1990-1991. Preprint
arXiv:2005.05744. The deep learning neural networks (NNs) of our team have revolutionised pattern recognition & machine learning & AI. Many of the basic ideas behind this revolution were published within fewer than 12 months in our "Annus Mirabilis" 1990-1991 at TU Munich, including principles of (1)
LSTM, the most cited AI of the 20th century (based on constant error flow through residual connections); (2) ResNet, the most cited AI of the 21st century (based on our LSTM-inspired Highway Network, 10 times deeper than previous NNs); (3)
GAN (for artificial curiosity and creativity); (4) Transformer (the T in ChatGPT—see the 1991 Unnormalized Linear Transformer); (5) Pre-training for deep NNs (the P in ChatGPT); (6) NN distillation (see DeepSeek); (7) recurrent World Models, and more.
[MOST]
J. Schmidhuber (AI Blog, 2021, updated 2025). The most cited neural networks all build on work done in my labs: 1. Long Short-Term Memory (LSTM), the most cited AI of the 20th century. 2. ResNet (open-gated Highway Net), the most cited AI of the 21st century. 3. AlexNet & VGG Net (the similar but earlier DanNet of 2011 won 4 image recognition challenges before them). 4. GAN (an instance of Adversarial Artificial Curiosity of 1990). 5. Transformer variants—see the 1991 unnormalised linear Transformer (ULTRA). Foundations of Generative AI were published in 1991: the principles of GANs (now used for deepfakes), Transformers (the T in ChatGPT), Pre-training for deep NNs (the P in ChatGPT), NN distillation, and the famous DeepSeek—see the tweet.
[MUN87]
P. W. Munro. A dual back-propagation scheme for scalar reinforcement learning. Proceedings of the Ninth Annual Conference of the Cognitive Science Society, Seattle, WA, pages 165-176, 1987.
[NAN1]
J. Schmidhuber.
Networks adjusting networks.
In J. Kindermann and A. Linden, editors, Proceedings of
`Distributed Adaptive Neural Information Processing', St.Augustin, 24.-25.5.
1989, pages 197-208. Oldenbourg, 1990.
Extended version: TR FKI-125-90 (revised),
Institut für Informatik, TUM.
PDF.
[NAN2]
J. Schmidhuber.
Networks adjusting networks.
Technical Report FKI-125-90, Institut für Informatik,
Technische Universität München. Revised in November 1990.
PDF.
[NAN3]
Recurrent networks adjusted by adaptive critics.
In Proc. IEEE/INNS International Joint Conference on Neural
Networks, Washington, D. C., volume 1, pages 719-722, 1990.
[NAN4]
J. Schmidhuber.
Additional remarks on G. Lukes' review of Schmidhuber's paper
`Recurrent networks adjusted by adaptive critics'.
Neural Network Reviews, 4(1):43, 1990.
[NAN5]
M. Jaderberg, W. M. Czarnecki, S. Osindero, O. Vinyals, A. Graves, D. Silver, K. Kavukcuoglu.
Decoupled Neural Interfaces using Synthetic Gradients.
Preprint arXiv:1608.05343, 2016.
[NGU89]
D. Nguyen and B. Widrow; The truck backer-upper: An example of self learning in neural networks. In IEEE/INNS International Joint Conference on Neural Networks, Washington, D.C., volume 1, pages 357-364, 1989.
[NOB] J. Schmidhuber.
A Nobel Prize for Plagiarism.
Technical Report IDSIA-24-24.
Sadly, the Nobel Prize in Physics 2024 for Hopfield & Hinton is a Nobel Prize for plagiarism. They republished methodologies developed in Ukraine and Japan by Ivakhnenko and Amari in the 1960s & 1970s, as well as other techniques, without citing the original papers. Even in later surveys, they didn't credit the original inventors (thus turning what may have been unintentional plagiarism into a deliberate form). None of the important algorithms for modern Artificial Intelligence were created by Hopfield & Hinton.
See also popular
tweet1,
tweet2, and
LinkedIn post.
[OBJ1] K. Greff, A. Rasmus, M. Berglund, T. Hao, H. Valpola, J. Schmidhuber (2016). Tagger: Deep unsupervised perceptual grouping. NIPS 2016, pp. 4484-4492.
[OBJ2] K. Greff, S. van Steenkiste, J. Schmidhuber (2017). Neural expectation maximization. NIPS 2017, pp. 6691-6701.
[OBJ3] S. van Steenkiste, M. Chang, K. Greff, J. Schmidhuber (2018). Relational neural expectation maximization: Unsupervised discovery of objects and their interactions. ICLR 2018.
[OBJ4]
A. Stanic, S. van Steenkiste, J. Schmidhuber (2021). Hierarchical Relational Inference. AAAI 2021.
[OBJ5]
A. Gopalakrishnan, S. van Steenkiste, J. Schmidhuber (2020). Unsupervised Object Keypoint Learning using Local Spatial Predictability.
Preprint arXiv/2011.12930.
[PG]
R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning 8.3-4: 229-256, 1992.
[PHD]
J. Schmidhuber.
Dynamische neuronale Netze und das fundamentale raumzeitliche
Lernproblem
(Dynamic neural nets and the fundamental spatio-temporal
credit assignment problem).
Dissertation,
Institut für Informatik, Technische
Universität München, 1990.
PDF.
HTML.
[PLAN]
J. Schmidhuber (AI Blog, 2020). 30-year anniversary of planning & reinforcement learning with recurrent world models and artificial curiosity (1990). This work also introduced high-dimensional reward signals, deterministic policy gradients for RNNs,
the GAN principle (widely used today). Agents with adaptive recurrent world models even suggest a simple explanation of consciousness & self-awareness.
[PLAN2]
J. Schmidhuber.
An on-line algorithm for dynamic reinforcement learning and planning
in reactive environments.
In Proc. IEEE/INNS International Joint Conference on Neural
Networks, San Diego, volume 2, pages 253-258, June 17-21, 1990.
Based on [AC90].
[PLAN3]
J. Schmidhuber.
Reinforcement learning in Markovian and non-Markovian environments.
In D. S. Lippman, J. E. Moody, and D. S. Touretzky, editors,
Advances in Neural Information Processing Systems 3, NIPS'3, pages 500-506. San
Mateo, CA: Morgan Kaufmann, 1991.
PDF.
Partially based on [AC90].
[PLAN4]
J. Schmidhuber.
On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models.
Report arXiv:1210.0118 [cs.AI], 2015.
[PLAN5]
One Big Net For Everything. Preprint arXiv:1802.08864 [cs.AI], Feb 2018.
[PLAN6]
D. Ha, J. Schmidhuber. Recurrent World Models Facilitate Policy Evolution. Advances in Neural Information Processing Systems (NIPS), Montreal, 2018. (Talk.)
Preprint: arXiv:1809.01999.
Github: World Models.
[PM1] J. Schmidhuber. Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879, 1992. PDF.
More.
[PM2] J. Schmidhuber, M. Eldracher, B. Foltin. Semilinear predictability minimzation produces well-known feature detectors. Neural Computation, 8(4):773-786, 1996.
PDF. More.
[PP] J. Schmidhuber.
POWERPLAY: Training an Increasingly General Problem Solver by Continually Searching for the Simplest Still Unsolvable Problem.
Frontiers in Cognitive Science, 2013.
ArXiv preprint (2011):
arXiv:1112.5309 [cs.AI]
[PP1] R. K. Srivastava, B. Steunebrink, J. Schmidhuber.
First Experiments with PowerPlay.
Neural Networks, 2013.
ArXiv preprint (2012):
arXiv:1210.8385 [cs.AI].
[PP2] V. Kompella, M. Stollenga, M. Luciw, J. Schmidhuber. Continual curiosity-driven skill acquisition from high-dimensional video inputs for humanoid robots. Artificial Intelligence, 2015.
[R2] Reddit/ML, 2019. J. Schmidhuber really had GANs in 1990.
[RES5]
Gloye, A., Wiesel, F., Tenchio, O., Simon, M. Reinforcing the Driving
Quality of Soccer Playing Robots by Anticipation, IT - Information
Technology, vol. 47, nr. 5, Oldenbourg Wissenschaftsverlag, 2005.
PDF.
[RES7]
J. Schmidhuber: Prototype resilient, self-modeling robots. Correspondence, Science, 316, no. 5825 p 688, May 2007.
[S59]
A. L. Samuel.
Some studies in machine learning using the game of checkers.
IBM Journal on Research and Development, 3:210-229, 1959.
[SNT]
J. Schmidhuber, S. Heil (1996).
Sequential neural text compression.
IEEE Trans. Neural Networks, 1996.
PDF.
A probabilistic language model based on predictive coding;
an earlier version appeared at NIPS 1995.
[T22] J. Schmidhuber (AI Blog, 2022).
Scientific Integrity and the History of Deep Learning: The 2021 Turing Lecture, and the 2018 Turing Award. Technical Report IDSIA-77-21 (v3), IDSIA, Lugano, Switzerland, 2021-2022.
[TD]
R. Sutton. Learning to predict by the methods of temporal differences. Machine Learning. 3 (1): 9-44, 1988.
[ULTRA]
References on the 1991 unnormalized linear Transformer (ULTRA): original tech report (1991) [FWP0]. Journal publication (1992) [FWP1]. Recurrent ULTRA extension (1993) introducing the terminology of learning "internal spotlights of attention” [FWP2]. Modern "quadratic" Transformer (2017: "attention is all you need") scaling quadratically in input size [TR1]. Papers of 2020-21 using the terminology "linearized attention" for more efficient "linear Transformers" that scale linearly [TR5,TR6]. 2021 paper [FWP6] pointing out that ULTRA dates back to 1991 [FWP0] when compute was a million times more expensive. ULTRA overview (2021) [FWP]. See the T in ChatGPT! See also surveys [DLH][DLP], 2022 tweet for ULTRA's 30-year anniversary, and 2024 tweet.
[UN]
J. Schmidhuber (AI Blog, 2021). 30-year anniversary. 1991: First very deep learning with unsupervised pre-training. Unsupervised hierarchical predictive coding finds compact internal representations of sequential data to facilitate downstream learning. The hierarchy can be distilled into a single deep neural network (suggesting a simple model of conscious and subconscious information processing). 1993: solving problems of depth >1000.
[UN0]
J. Schmidhuber.
Neural sequence chunkers.
Technical Report FKI-148-91, Institut für Informatik, Technische
Universität München, April 1991.
PDF.
[UN1] J. Schmidhuber. Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242, 1992. Based on TR FKI-148-91, TUM, 1991.[UN0] PDF.
First working Deep Learner based on a deep RNN hierarchy (with different self-organising time scales),
overcoming the vanishing gradient problem through unsupervised pre-training and predictive coding.
Also: compressing or distilling a teacher net (the chunker) into a student net (the automatizer) that does not forget its old skills—such approaches are now widely used. More.
[UN2] J. Schmidhuber. Habilitation thesis, TUM, 1993. PDF.
An ancient experiment on "Very Deep Learning" with credit assignment across 1200 time steps or virtual layers and unsupervised pre-training for a stack of recurrent NN
can be found here (depth > 1000).
[UN3]
J. Schmidhuber, M. C. Mozer, and D. Prelinger.
Continuous history compression.
In H. Hüning, S. Neuhauser, M. Raus, and W. Ritschel, editors,
Proc. of Intl. Workshop on Neural Networks, RWTH Aachen, pages 87-95.
Augustinus, 1993.
[WER87]
P. J. Werbos. Building and understanding adaptive systems: A statistical/numerical approach to factory automation and brain research. IEEE Transactions on Systems, Man, and Cybernetics, 17, 1987.
[WER89]
P. J. Werbos. Backpropagation and neurocontrol: A review and prospectus. In IEEE/INNS International Joint Conference on Neural Networks, Washington, D.C., volume 1, pages 209-216, 1989.
.