
★ 12/22/2022 (updated 12/29/2025): Annotated History of Modern AI and Deep Learning. Machine learning is the science of credit assignment. My new survey (also under arXiv:2212.11279) credits the pioneers of deep learning and modern AI (supplementing my award-winning 2015 deep learning survey). Finally, I will put things in a broader historical context, spanning from the Big Bang to when the universe will be many times older than it is now.

★ 22 Oct 2025. In 2025, we are celebrating the 100th anniversary of the transistor: on 22 Oct 1925, Julius Edgar Lilienfeld (a Polish professor in Germany) patented the field-effect transistor (FET).
In 1928, he also patented the metal oxide semiconductor FET (MOSFET).
Lilienfeld's designs worked (Ross, 1995; Arns, 1998).
The much later point-contact transistor (Bell Labs, 1948) was a dead end:
today, almost all of the billions of trillions of transistors in our computers and smartphones are FETs of the Lilienfeld type. See also: who invented the transistor?

★ Nov 2025. Who invented artificial neural networks? Modern Artificial Intelligence (AI) is based on learning artificial neural networks. Who invented them? Biological neural nets were discovered in the 1880s. The term "neuron" was coined in 1891. Many think that artificial neural nets were developed after that. But that's not the case: the first "modern" NNs with 2 layers of units were invented over 2 centuries ago (1795-1805) by Legendre and Gauss, when compute was many trillions of times more expensive than in 2025.

★ Nov 2025. Who Invented Deep Learning? Modern AI is based on deep artificial neural networks with input units, output units, and typically many layers of hidden units. Deep learning is about training the latter.
Who invented this? Here is the timeline of deep learning breakthroughs since 1965.

★ Aug 2025 (updated Dec 2025):
Who invented convolutional neural networks?
CNNs are widely used whenever images or videos are involved. Here is the timeline of the origins of CNNs (extending a popular tweet).

★ 2014 (updated 2025): Who invented backpropagation? The "modern" version of backpropagation, the reverse mode of automatic differentiation, was published in 1970 by Finnish master student Seppo Linnainmaa. Henry J. Kelley's precursor was published in 1960.

★ Dec 2025. Who invented generative adversarial networks? The most cited research paper from the lab of a Turing awardee is about generative adversarial networks.
Who invented them? The first neural networks that were both generative and adversarial were published in 1990-1991 in Munich.

★ Nov 2025. Who Invented Transformer Neural Networks? The T in ChatGPT stands for a famous neural net called Transformer.
Who invented this? Here is the timeline of Transformer evolution, starting with J. Schmidhuber's 1991 unnormalised linear Transformer (ULTRA). See also the tweet.

★ Nov 2025. Who invented knowledge distillation with artificial neural networks?
In January 2025, the DeepSeek "Sputnik" shocked the commercial AI scene and wiped out a trillion USD from the stock market.
DeepSeek and many other Large Language Models distill knowledge from one artificial neural network into another. Who invented this? NN distillation was published by J. Schmidhuber in 1991. See also the tweet.

★ Sept 2025. The most cited scientific article of the 21st century is a paper on deep residual learning
with residual connections. Who invented this? Here is the timeline of the evolution of deep residual learning (see also arXiv:2509.24732):
★ 1991: Hochreiter's recurrent residual connections solve the vanishing gradient problem
★ 1997 LSTM: plain recurrent residual connections (weight 1.0)
★ 1999 LSTM: gated recurrent residual connections (gates initially open: 1.0)
★ 2005: unfolding LSTM—from recurrent to feedforward residual NNs
★ May 2015: deep Highway Net—gated feedforward residual connections (initially 1.0)
★ Dec 2015: ResNet—like an open-gated Highway Net (or an unfolded 1997 LSTM)

★ May 2015 (updated 2025 for 10-year anniversary): Highway Networks.
Very deep artificial neural networks (NNs) have become indispensable for
Modern AI. In May 2015, we published the first working very deep gradient-based feedforward NNs (FNNs) with hundreds of layers (previous FNNs had a maximum of a few dozen layers). To overcome the vanishing gradient problem, our Highway NNs (or gated ResNets) use the residual connections first introduced in 1991 to achieve constant error flow in recurrent NNs (RNNs), gated through multiplicative gates similar to the 1999 forget gates of our very deep LSTM RNN. Setting the Highway NN gates to 1.0 effectively gives us the ResNet published 7 months later. Deep learning
is all about NN depth.
LSTM
brought essentially unlimited depth to RNNs; Highway Nets (= generalized ResNets) brought it to FNNs.

★ 2025 celebrations. 2010: Breakthrough of end-to-end deep learning (no layer-by-layer training, no unsupervised pre-training). The rest is history. By 2010, when compute was 1000 times more expensive than in 2025, both our feedforward neural networks (NNs) and our earlier recurrent NNs were able to beat all competing algorithms on important problems of that time.
This deep learning revolution quickly spread from Europe to North America and Asia. Today's training sets are much bigger: in 2010, it was just MNIST, now it's the entire Internet!

★ 1995-2025: The Decline of Germany & Japan vs US & China. Can All-Purpose Robots Fuel a Comeback? In 1995, in terms of nominal gross domestic product (GDP), a combined Germany and Japan were almost 1:1 economically with a combined USA and China, according to IMF. Only 3 decades later, this ratio is now down to 1:5! Self-replicating AI-driven all-purpose robots may be the answer. Around 2000, Japan still was the country with the most robots; Germany was 2nd. Today, China is number 1. However, most existing robots are dumb. They are not adaptive like the coming smart robots that will learn to do all the jobs humans don't like, including making more such robots.
Based on a 2024 F.A.Z. guest article.

★ 2025 update: 1991: First very deep learning with unsupervised pre-training (the P in ChatGPT); first neural network distillation. Unsupervised hierarchical predictive coding finds compact internal representations of sequential data to facilitate downstream learning. The hierarchy can be "collapsed" or "distilled" into a single deep neural network (suggesting a simple model of conscious and subconscious information processing). 1993: solving problems of depth >1000. Distillation is at the heart of the famous 2025 DeepSeek—see the tweet.
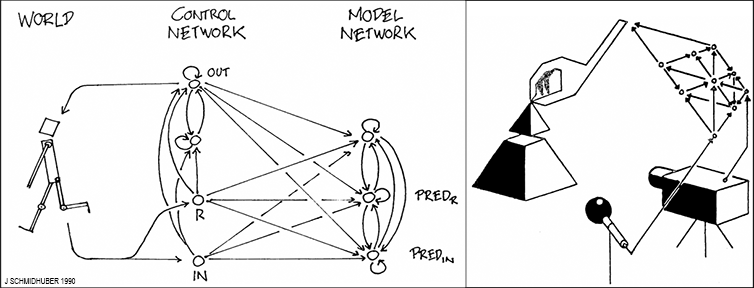
★ 2025 update: 35th anniversary of planning & reinforcement learning with recurrent neural network-based world models and artificial curiosity (1990). This work also pioneered high-dimensional reward signals and
the principle of generative adversarial networks (GANs) (widely used today). Agents with adaptive world models even suggest a simple explanation of consciousness & self-awareness
(dating back to 1990-1991). In 2025, everyone is suddenly talking about Real AI (or Physical AI) for real robots in the real world,
building on foundations laid in 1990.

★ 2025 update of 2021 report: Artificial Curiosity & Creativity Since 1990-91. Our artificial scientists not only answer given questions but also invent new questions. They achieve curiosity through: (1990) the principle of generative adversarial networks (GANs), (1991) neural nets that maximise learning progress, (1995) neural nets that maximise information gain (optimally since 2011), (1997) adversarial design of surprising computational experiments, (2006) maximizing compression progress like scientists/artists/comedians do, (2011) PowerPlay... Since 2012: applications to real robots.

★ Dec 2020 (updated 2025). Metalearning Machines Learn to Learn (1987-).
For the cover of my 1987 thesis on metalearning I drew a robot that bootstraps itself.
1992-: gradient descent-based neural metalearning. 1994-: Meta-Reinforcement Learning with self-modifying policies. 1997: Meta-RL plus artificial curiosity and intrinsic motivation.
2002-: asymptotically optimal metalearning for curriculum learning. 2003-: mathematically optimal Gödel Machine. 2020-2022: new stuff. 2025: "In-Context Learning" of Large Language Models is a special case of metalearning.

★ 2025: 20-year anniversary: 1st paper with "learn deep" in the title (2005). Our deep reinforcement learning & neuroevolution solved problems of depth 1000 and more. Soon after its publication, everybody started talking about "deep learning." Causality or correlation?
2024

★June 2024: 2024 ACM SIGEVO Impact Award for the seminal 2014 paper based on our 2013 work on Compressed Network Search: the first reinforcement learning system that learned control policies directly from high-dimensional sensory input—without any unsupervised pre-training.

★ Dec 2024 (updated Oct 2025): Sadly, the Nobel Prize in Physics 2024 for Hopfield & Hinton is a Nobel Prize for plagiarism. They republished methodologies developed in Ukraine and Japan by Ivakhnenko and Amari in the 1960s & 1970s, as well as other techniques, without citing the original papers. Even in later surveys, they didn't credit the original inventors (thus turning what may have been unintentional plagiarism into a deliberate form). None of the important algorithms for modern Artificial Intelligence were created by Hopfield & Hinton. Details in the recent technical report, with lots of references, links, and facts. See also tweet1, tweet2, and LinkedIn post.
2023

★ Dec 2023 (updated May 2026): How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. The piece is aimed at people who are not aware of the numerous AI priority disputes, but are willing to check the facts (see tweet).

★ 28 June 2023: in the Markus Lanz talk show, starting at 25:35 (ZDF, in German)
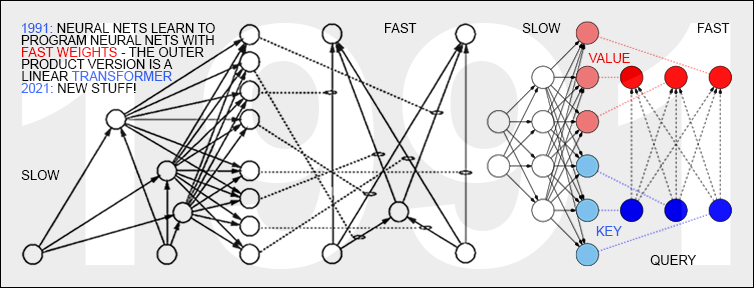
★ 26 Mar 1991: Neural nets learn to program neural nets with fast weights—the first Transformer variants. 2021: New stuff! Update of 2025:
ChatGPT and similar large language models are based on a family of artificial neural networks (NNs) called Transformers. Already in 1991, when compute was a million times more expensive than today, I published the first Transformer variant, which is now called an unnormalised linear Transformer (ULTRA).
That wasn't the name it got given at the time, but today the mathematical equivalence is obvious (see tweet). In a sense, computational restrictions drove it to be even more efficient than later "quadratic" Transformer variants, resulting in costs that scale linearly in input size, rather than quadratically. The 1991 ULTRA was a by-product of more general research on Fast Weight Programmers: NNs that learn to program the fast weights of other NNs, separating storage and control like in traditional computers.
2022

★ On 9 Aug 2022, NNAISENSE
released EvoTorch, an open source state-of-the-art evolutionary algorithm library built on PyTorch, with GPU-acceleration and easy training on huge compute clusters using @raydistributed. Within 5 days, EvoTorch earned over 500 stars on
GitHub. We are already using EvoTorch internally for industrial control and optimization, with some experiments using population sizes in the hundreds of thousands.
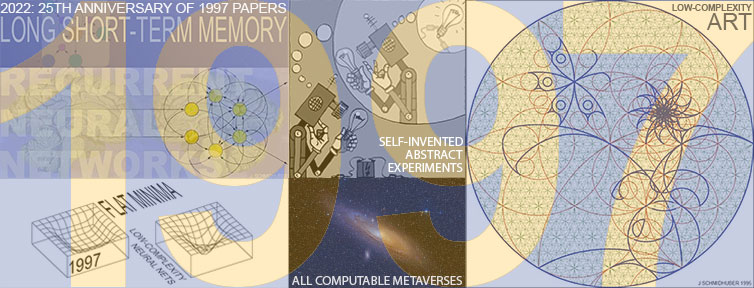
★ In 2022, we are celebrating the following works from a quarter-century ago.
1. Journal paper on Long Short-Term Memory, the
most cited neural network (NN) of the 20th century
(and basis of the most cited NN of the 21st).
2. First paper on physical, philosophical and theological consequences of the simplest and fastest way of computing
all possible metaverses
(= computable universes).
3. Implementing artificial curiosity and creativity through generative adversarial agents that learn to design abstract, interesting computational experiments.
4. Journal paper on
meta-reinforcement learning.
5. Journal paper on hierarchical Q-learning.
6. First paper on reinforcement learning to play soccer: start of a series.
7. Journal papers on flat minima & low-complexity NNs that generalize well.
8. Journal paper on Low-Complexity Art, the Minimal Art of the Information Age.
9. Journal paper on probabilistic incremental program evolution.
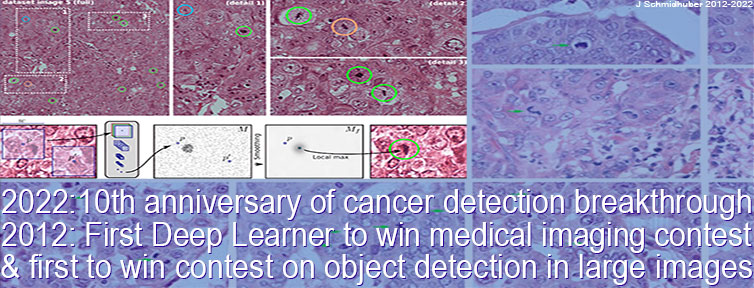
★ Healthcare revolution: 10 years ago, when compute was 100 times more expensive than in 2022, our DanNet was the first artificial neural network to win a medical imaging contest. It won the 2012 ICPR breast cancer detection contest, then later the MICCAI Grand Challenge. Today, many healthcare professionals and hospitals are using this approach.
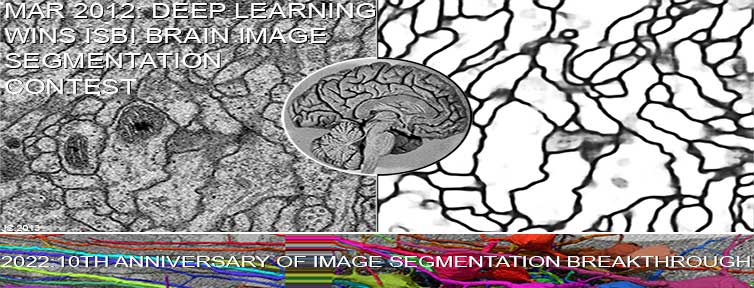
★ 2022: 10th anniversary: in March 2012,
when compute was roughly 100 times more expensive than in 2022,
our feedforward neural network
called the DanNet
was the first to win an image segmentation competition: the ISBI Challenge. Today, many are using variants of this approach for all kinds of image segmentation.

★
LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015. Years ago we published most of what he calls his "main original contributions:" neural nets that learn multiple time scales and levels of abstraction, generate subgoals, use intrinsic motivation to improve world models, and plan (1990); controllers that learn informative predictable representations (1997), etc. This was also discussed on Hacker News, reddit, and various media. (Updated in May 2026.)

★ Sept 2021 (revised 2022): Scientific Integrity and the History of Deep Learning:
The 2021 Turing Lecture, and the 2018 Turing Award. This is a point-for-point critique of ACM's justification of the ACM A. M. Turing Award for deep learning, as well as a critique of the Turing Lecture given by the awardees (published by ACM in July 2021). In brief, three Europeans went to North America, where they republished methods and concepts first published by others whom they did not cite—not even in later surveys. Instead, they credited each other at the expense of the field's pioneers. Apparently, the ACM was not aware of this. The critique supplements my award-winning
deep learning survey, and can also be seen as a short history of the deep learning revolution, at least as far as ACM's erroneous laudation and the Turing Lecture are concerned.
2021

★ Nov 2021: KAUST (17 full papers at NeurIPS 2021) and its environment are now offering enormous resources to advance both fundamental and applied AI research:
we are hiring outstanding professors, postdocs, and PhD students—see also local copy and
interview in FAZ (13 Dec 2021).

★ 1 Oct 2021: Starting as Director of the AI Initiative at KAUST, the university with the highest impact per faculty. Keeping current affiliations. Hiring on all levels. Great research conditions. I photographed the Dolphin above on a snorkeling trip off the coast of KAUST.

★
80th anniversary celebrations: 1941: Konrad Zuse completes the first working general purpose computer, based on his 1936 patent application. (German version published in Weltwoche, 19 Aug 2021, also online.)

★
90th anniversary of Kurt Gödel's 1931 paper
which laid the foundations of theoretical computer science, identifying fundamental limitations of algorithmic theorem proving, computing, AI, logics, and math itself (German version published in FAZ, 16/6/2021). This reached the top position of the Hacker News front page.

★ 375th birthday of Gottfried Wilhelm Leibniz, founder of computer science (just published in FAZ, 17/5/2021, with an interview): 1st machine with a memory (1673); 1st to perform all arithmetic operations. Principles of binary computers (1679). Algebra of Thought (1686) deductively equivalent to the much later Booelan Algebra. Calculemus! (Deutsch)

★
Sep 2021: Turing Oversold.
Alan M. Turing made certain significant contributions to computer science. However, their importance and impact is often greatly exaggerated, at the expense of the field's pioneers. It's not Turing's fault, though.
★ ICLR 2021:
Our five submissions got accepted
(probability < 0.002 according to the acceptance rate). Additional papers at AAAI 2021 and ICML 2021.
★ 13 April 11:15-12:00: Talk as Chief Scientist of NNAISENSE on use cases of industrial AI at Hannover Messe, the world's largest trade fair (opened by Angela Merkel). Same day 14:00-15:00: Talk on "Modern AI 1980s-2021 and Beyond" at GTC 2021 (opened by NVIDIA CEO Jensen Huang).

★ 2021: LEGO Art: Stable rings from rectangular LEGO bricks (2001).
Two decades ago,
I stole a basic LEGO kit from my daughters, and discovered several different ways of making very stable rings and other curved objects from only rectangular LEGO bricks.
Natural tilting angles between LEGO pieces define ring diameters. The resulting low-complexity artworks reflect the formal theory of beauty/creativity/curiosity.

★ Feb 2021: 10-year anniversary. In 2011, DanNet triggered the deep convolutional neural network (CNN) revolution. Named after my outstanding postdoc Dan Ciresan, it was the first deep and fast CNN to win international computer vision contests, and had a temporary monopoly on winning them, driven by a very fast implementation based on graphics processing units (GPUs). 1st superhuman result in 2011. Now everybody is using this approach.

★ 2017 (updated 2021 for 10th birthday of DanNet): History of computer vision contests won by deep CNNs since 2011. DanNet won 4 of them in a row before the similar AlexNet & VGG Net and the Resnet (a Highway Net with open gates) joined the party. Today, deep CNNs are standard in computer vision.

★ 2011 (updated 2021 for 10th birthday of DanNet): First superhuman visual pattern recognition.
At the IJCNN 2011 computer vision competition in Silicon Valley,
our artificial neural network called DanNet performed twice better than humans, three times better than the closest artificial competitor, and six times better than the best non-neural method.
2020
★ Dec 2020: 1/3 century anniversary of
Genetic Programming for code of unlimited size (1987).
GP is about solving problems by applying the principles of biological evolution to computer programs.

★ Dec 2020: 10-year anniversary of our journal paper on deep reinforcement learning with policy gradients for LSTM (2007-2010). Recent famous applications: DeepMind's Starcraft player (2019) and OpenAI's dextrous robot hand & Dota player (2018)—Bill Gates called this a huge milestone in advancing AI.

★ Oct 2020 (updated 2025): 30-year anniversary of end-to-end differentiable sequential neural attention. Plus goal-conditional reinforcement learning. An artificial fovea learned to find objects in visual scenes through sequences of saccades. We had both hard attention (1990) and soft attention (1991-93) for the
1991 unnormalised linear Transformer. Today, both types are very popular. See also my Fast Weight Programmers of 1991 which are formally equivalent to Transformers with linearized self-attention.

★ Sep 2020: 10-year anniversary of supervised deep learning breakthrough (2010). No unsupervised pre-training.
By 2010, when compute was 100 times more expensive than today, both our feedforward NNs and our earlier recurrent NNs were able to beat all competing algorithms on important problems of that time. This deep learning revolution quickly spread from Europe to North America and Asia. The rest is history.
★ Apr/Jun 2020: Critique of ACM's justification of the 2018 Turing Award for deep learning (backed up by 200+ references).
Similar critique of 2019 Honda Prize—science must not allow corporate PR to distort the academic record.

★ Apr 2020: AI v Covid-19.
I made a little cartoon and notes with references and links to the recent ELLIS workshops & JEDI Grand Challenge & other initiatives.
AI based on Neural Networks (NNs) and Deep Learning can help to fight Covid-19 in many ways. The basic principle is simple. Teach NNs to detect patterns in data from viruses and patients and others. Use those NNs to predict future consequences of possible actions. Act to minimize damage.

★ Apr 2020: Coronavirus geopolitics. Pandemics have greatly influenced the rise and fall of empires. What will be the impact of the current pandemic?

★ Feb 2020 (updated 2025): 2010-2020: our decade of deep learning. The recent decade's most important developments and industrial applications based on our AI, with an outlook on the 2020s, also addressing privacy and data markets.
2017-2019

★ Oct 2019 (updated 2026): Deep learning: our Miraculous Year 1990-1991. The deep learning neural networks (NNs) of our team have revolutionised pattern recognition & machine learning & AI. Many of the basic ideas behind this revolution were published within fewer than 12 months in our "Annus Mirabilis" 1990-1991 at TU Munich.

★ Nov 2018: Unsupervised neural networks fight in a minimax game (1990). To build curious artificial agents, I introduced a new type of active self-supervised learning in 1990. It is based on a duel where one
neural net minimizes the objective function maximized by another.
GANs are simple special cases.
Today, this principle is widely used.
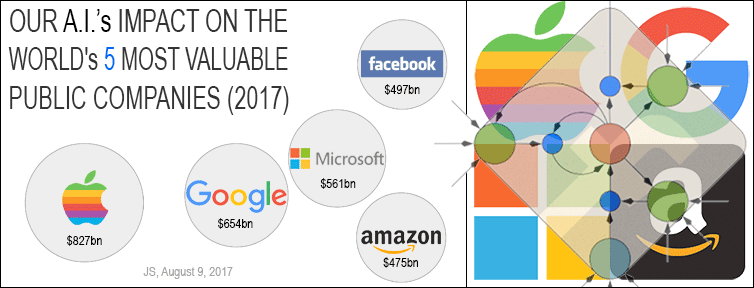
★ Aug 2017:
Our impact on the world's most valuable public companies: Apple, Google, Microsoft, Facebook, Amazon... By 2015-17, neural nets developed in my labs were on over 3 billion devices such as smartphones, and used many billions of times per day, consuming a significant fraction of the world's compute. Examples: greatly improved (CTC-based) speech recognition on all Android phones, greatly improved machine translation through Google Translate and Facebook (over 4 billion LSTM-based translations per day), Apple's Siri and Quicktype on all iPhones, the answers of Amazon's Alexa, etc. Google's 2019
on-device speech recognition
(on the phone, not the server)
is still based on
LSTM.
★ 2017-: Many jobs for PhD students and PostDocs
2015-2016
★ Jul 2016: I got the 2016 IEEE CIS Neural Networks Pioneer Award for "pioneering contributions to deep learning and neural networks."

★ Oct 2015: Brainstorm open source
software for neural networks. Before Google's Tensorflow dethroned our Brainstorm, this open source software made the Swiss AI Lab IDSIA the top trending Python developer on Github, ahead of Facebook, Google, and Dropbox.
★ Feb 2015: DeepMind's Nature paper and earlier related work

★ Jan 2015: Deep learning in neural networks: an overview. This paper of 2015 got the first best paper award ever issued by the journal Neural Networks, founded in 1988. It has also become the most cited paper of Neural Networks.
1987-2014

★ July 2013:
Compressed network search:
First deep learner to learn control policies directly from high-dimensional sensory input using reinforcement learning. (More.)
★ 2013: Sepp Hochreiter's fundamental deep learning problem (1991). (More.)
★ Sep 2012: First deep learner to win a medical imaging contest (cancer detection)
★ Mar 2012: First deep learner to win an image segmentation competition
★ Aug 2011: First superhuman visual pattern recognition.
 ✯ 1989-:
Recurrent neural networks - especially Long Short-Term Memory or LSTM. See also this more recent LSTM summary of 2020.
✯ 1989-:
Recurrent neural networks - especially Long Short-Term Memory or LSTM. See also this more recent LSTM summary of 2020.
✯ 2011: Preface of book on recurrent neural networks
✯ 2009-: First contests won by recurrent nets (2009)
and deep feedforward nets (2010)
✯ 2009-: Winning computer vision contests through deep learning
✯ 2005:
Evolving recurrent neurons - first paper with "learn deep" in the title. More. See also
15th anniversary (2020)
 ✯ 1991-: First working deep learner based on unsupervised pre-training + Deep Learning Timeline 1962-2013. More. See also
30th anniversary (2021)
✯ 1991-: First working deep learner based on unsupervised pre-training + Deep Learning Timeline 1962-2013. More. See also
30th anniversary (2021)
✯ 1991-:
Deep learning & neural computer vision. Our simple training algorithms for deep, wide, often recurrent, artificial neural networks similar to biological brains were the first to win competitions on a routine basis and yielded best known results on many famous benchmarks for computer vision, speech recognition, etc. Today, everybody is using them.
✯ 1991-: Unsupervised learning
✯ 1991-: Neural heat exchanger
✯ 1987-:
Meta-learning or learning to learn. See also:
1/3 century anniversary of
metalearning (2020)
 ✯ 2003-:
Gödel machines as mathematically optimal general self-referential problem solvers
✯ 2003-:
Gödel machines as mathematically optimal general self-referential problem solvers
✯ 2002-:
Asymptotically optimal curriculum learner: the optimal ordered problem solver OOPS
✯ 2000-:
Theory of universal artificial intelligence
✯ 2000-:
Generalized algorithmic information & Kolmogorov complexity
✯ 2000-: Speed Prior: a new simplicity measure for near-optimal computable predictions
✯ 1996-:
Computable universes / theory of everything / generalized algorithmic information
 ✯ 1989-:
Reinforcement learning
✯ 1989-:
Reinforcement learning
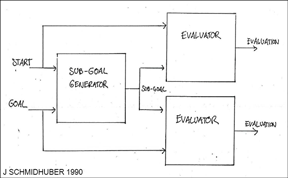
✯ 1990-:
Subgoal learning & hierarchical reinforcement learning. (More.)
✯ 1990-: Learning attentive vision (more) &
goal-conditional reinforcement learning.
See also 30-year anniversary (2020)
✯ 1989: Reinforcement learning economies
with credit conservation
✯ 1987-:
Artificial evolution
✯ 2005-: Evolino
✯ 1987-: Genetic programming. See also 1/3 century anniversary (2020)
 ✯ 2002-:
Learning robots
✯ 2002-:
Learning robots
✯ 2004-2009: TU Munich Cogbotlab at TUM
✯ 2004-2009: CoTeSys cluster of excellence
✯ 2007: Highlights of robot car history
✯ 2004: Statistical robotics
✯ 2004: Resilient machines &
resilient robots
✯ 2000-: Artificial Intelligence
✯ 1990-:
Artificial curiosity & creativity & intrinsic motivation & developmental robotics. (More.)
✯ 1990-: Formal theory of creativity
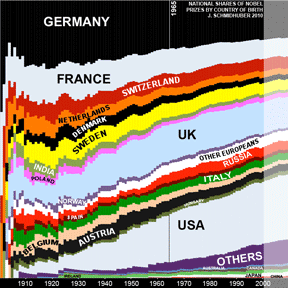 ✯ 2010:
Evolution of national Nobel Prize shares in the 20th century.
See also
main article.
✯ 2010:
Evolution of national Nobel Prize shares in the 20th century.
See also
main article.
✯ 1995-:
Switzerland - best country in the world?
✯ 2010: A new kind of empire?
✯ 2000s: Einstein &
Zuse &
Goedel &
Turing &
Gauss &
Leibniz &
Schickard &
Solomonoff &
Darwin &
Haber & Bosch &
Archimedes
& Schwarzenegger &
Schumacher &
Schiffer
✯ 2012: Olympic medal statistics & Bolt
✯ 2006: Is history converging? Again?
✯ 1990: Computer history speedup
✯ 1994-:
Theory of beauty and
femme fractale
✯ 2001: Lego Art
✯ 2010: Fibonacci web design
✯ 2007: J.S.'s painting of his daughters and related work
 ✯ 1987-:
Online publications
✯ 1987-:
Online publications
✯
1963-: CV
✯ 1987-: What's new?
✯
2000s:
Old talk videos up to 2015
✯ 1981: Closest brush with fame
✯
1990:
Bavarian poetry
✯ 2010-: Master's in artificial intelligence





{kind=link}