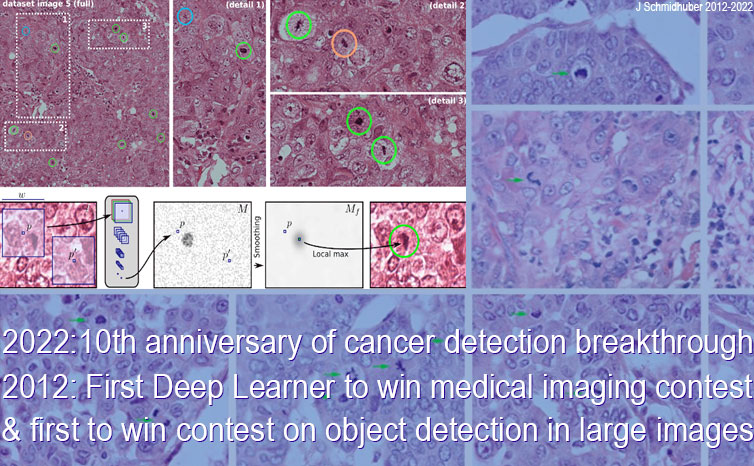
10 Sep 2012: first artificial neural network to win a medical imaging contest; first to win a contest on object detection in large images. Revolutionizing healthcare: our deep convolutional neural network won the ICPR contest on breast cancer detection and the MICCAI Grand Challenge
In 2022, we celebrated the 10th anniversary of a breakthrough in medical imaging and computer vision. On 10 Sept 2012, when compute was roughly 1000 times more expensive than now (2025), our Deep Learning Neural Network (NN),[DL1-6a][DLH][DLP]
called the
DanNet,[DAN,DAN1][GPUCNN1-3,5-8]
won the ICPR 2012 Contest on Mitosis Detection in Breast Cancer Histological Images.[MITOS1]
This was made possible through the efforts of my co-workers Dr. Dan Claudiu Ciresan and Dr. Alessandro Giusti—see paper published at MICCAI.[GPUCNN7] To our knowledge, DanNet was the first Deep Learner to win a medical imaging contest, and the first
to win a contest on object detection in large images (2048 x 2048 x 3 pixels).
This has revolutionized the field—today, everybody is using this approach.
One year after the victory of 2012, on September 22 at the MICCAI 2013 conference in Japan organised by the Society for Medical Image Computing and Computer Assisted Intervention, our deep NN also won the international MICCAI 2013 Grand Challenge on Mitosis Detection.[MITOS3] Title defended!
Over 80 research groups (universities and companies) registered, of which 14 submitted results. The gap between first and second place was large.
Mitosis detection is important for cancer prognosis, but difficult even for trained experts. How did DanNet learn to do it?
CNNs originated over 4 decades ago between 1979 and 1988 in Japan.[CNN1][CNN1a][CNN1a+]
Pure supervised gradient descent (the 1970 efficient reverse mode backpropagation[BP1-5]) was applied[CNN1a] to our special CNN architecture[GPUCNN1-3,5-8][DAN] consisting of deep and wide GPU-based[GPUNN][MLP1-3] Multi-Column Max-Pooling Convolutional Neural Networks (CNNs)[CNN1-4] with alternating weight-sharing convolutional layers[CNN1] and max-pooling layers[CNN3] topped by fully connected layers.[DEEP1-2][DL1-2] This architecture is biologically rather plausible, inspired by early neuroscience-related work.[CNN1] We also used additional tricks[GPUCNN7]
but no unsupervised pre-training![UN,UN1-2][MLP1-3]
The cancer detection contest was actually
the fourth computer vision competition in a row won by our pioneering DanNet (the first pure CNN to win contests) since 2011.
For a while, DanNet enjoyed a monopoly: from 2011 to 2012 it won every contest it entered. This included
a Chinese handwriting contest (ICDAR, May 2011),
a traffic sign recognition contest (IJCNN, Aug 2011),
an image segmentation contest (ISBI, March 2012),
and finally the contest on object detection in large images (ICPR, Sept 2012). This was all before the similar
AlexNet and VGG Net[GPUCNN4,9] won contests, too.[MOST]
Already in 2011, DanNet was the first system to achieve human-competitive or even
superhuman pattern recognition performance[GPUCNN1-3,5-8][DAN,DAN1]
in a computer vision contest. Since 2011, this has attracted enormous interest from industry. Many startups as well as leading IT companies and research labs are now using them, too.[DEC] Besides mitosis detection, our deep NN also have many other obvious biomedical applications, such as automatic detection of melanoma, detection of plaque in CT heart scans, segmentation of all kinds of biomedical images—you name it.
The world spends over 10% of GDP on healthcare (over 6 trillion USD per year), much of it on medical diagnosis through expensive experts. Partial automation of this could not only save billions of dollars, but also make expert diagnostics accessible to many who currently cannot afford it.
When we started Deep Learning research over 3 decades ago,[UN,UN1-2] limited computing power forced us to focus on toy applications. How things have changed! It is gratifying to observe that today our deep NN may actually help to improve healthcare and save human lives.
Acknowledgments
 The contents of this article may be used for educational and non-commercial purposes, including articles for Wikipedia and similar sites. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
The contents of this article may be used for educational and non-commercial purposes, including articles for Wikipedia and similar sites. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
References
[BPA]
H. J. Kelley. Gradient Theory of Optimal Flight Paths. ARS Journal, Vol. 30, No. 10, pp. 947-954, 1960.
Precursor of modern backpropagation.[BP1-4]
[BPB]
A. E. Bryson. A gradient method for optimizing multi-stage allocation processes. Proc. Harvard Univ. Symposium on digital computers and their applications, 1961.
[BPC]
S. E. Dreyfus. The numerical solution of variational problems. Journal of Mathematical Analysis and Applications, 5(1): 30-45, 1962.
[BP1] S. Linnainmaa. The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's Thesis (in Finnish), Univ. Helsinki, 1970.
See chapters 6-7 and FORTRAN code on pages 58-60.
PDF.
See also BIT 16, 146-160, 1976.
Link.
The first publication on "modern" backpropagation, also known as the reverse mode of automatic differentiation.
[BP2] P. J. Werbos. Applications of advances in nonlinear sensitivity analysis. In R. Drenick, F. Kozin, (eds): System Modeling and Optimization: Proc. IFIP,
Springer, 1982.
PDF.
First application of backpropagation[BP1] to NNs (concretizing thoughts in his 1974 thesis).
[BP4] J. Schmidhuber (AI Blog, 2014; updated 2020).
Who invented backpropagation?
More.[DL2]
[BP5]
A. Griewank (2012). Who invented the reverse mode of differentiation?
Documenta Mathematica, Extra Volume ISMP (2012): 389-400.
[CNN1] K. Fukushima: Neural network model for a mechanism of pattern
recognition unaffected by shift in position—Neocognitron.
Trans. IECE, vol. J62-A, no. 10, pp. 658-665, 1979.
The first deep convolutional neural network architecture, with alternating convolutional layers and downsampling layers. In Japanese. English version: [CNN1+]. More in Scholarpedia.
[CNN1+]
K. Fukushima: Neocognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position.
Biological Cybernetics, vol. 36, no. 4, pp. 193-202 (April 1980).
Link.
[CNN1a] A. Waibel. Phoneme Recognition Using Time-Delay Neural Networks. Meeting of IEICE, Tokyo, Japan, 1987. First application of backpropagation[BP1][BP2] and weight-sharing
to a 1-dimensional convolutional architecture.
[CNN1a+]
W. Zhang, J. Tanida, K. Itoh, Y. Ichioka. Shift-invariant pattern recognition neural network and its optical architecture. Proc. Annual Conference of the Japan Society of Applied Physics, 1988.
First "modern" backpropagation-trained 2-dimensional CNN.
[CNN1b] A. Waibel, T. Hanazawa, G. Hinton, K. Shikano and K. J. Lang. Phoneme recognition using time-delay neural networks. IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 37, no. 3, pp. 328-339, March 1989. Based on [CNN1a].
[CNN1c] Bower Award Ceremony 2021:
Jürgen Schmidhuber lauds Kunihiko Fukushima. YouTube video, 2021.
[CNN2] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, L. D. Jackel: Backpropagation Applied to Handwritten Zip Code Recognition, Neural Computation, 1(4):541-551, 1989.
PDF.
[CNN3a]
K. Yamaguchi, K. Sakamoto, A. Kenji, T. Akabane, Y. Fujimoto. A Neural Network for Speaker-Independent Isolated Word Recognition. First International Conference on Spoken Language Processing (ICSLP 90), Kobe, Japan, Nov 1990.
A 1-dimensional NN with convolutions using Max-Pooling instead of Fukushima's
Spatial Averaging.[CNN1]
[CNN3] Weng, J.,
Ahuja, N., and Huang, T. S. (1993). Learning recognition and segmentation of 3-D objects from 2-D images. Proc. 4th Intl. Conf. Computer Vision, Berlin, Germany, pp. 121-128. A 2-dimensional CNN whose downsampling layers use Max-Pooling
(which has become very popular) instead of Fukushima's
Spatial Averaging.[CNN1]
[CNN4] M. A. Ranzato, Y. LeCun: A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images. Proc. ICDAR, 2007
[CNN5a]
S. Behnke. Learning iterative image reconstruction in the neural abstraction pyramid. International Journal of Computational Intelligence and Applications, 1(4):427-438, 1999.
[CNN5b]
S. Behnke. Hierarchical Neural Networks for Image Interpretation, volume LNCS 2766 of Lecture Notes in Computer Science. Springer, 2003.
[CNN5c]
D. Scherer, A. Mueller, S. Behnke. Evaluation of pooling operations in convolutional architectures for object recognition. In Proc. International Conference on Artificial Neural Networks (ICANN), pages 92-101, 2010.
[DAN]
J. Schmidhuber (AI Blog, 2021).
10-year anniversary. In 2011, DanNet triggered the deep convolutional neural network (CNN) revolution. Named after my outstanding postdoc Dan Ciresan, it was the first deep and fast CNN to win international computer vision contests, and had a temporary monopoly on winning them, driven by a very fast implementation based on graphics processing units (GPUs).
1st superhuman result in 2011.[DAN1]
Now everybody is using this approach.
[DAN1]
J. Schmidhuber (AI Blog, 2011; updated 2021 for 10th birthday of DanNet): First superhuman visual pattern recognition.
At the IJCNN 2011 computer vision competition in Silicon Valley,
our artificial neural network called DanNet performed twice better than humans, three times better than the closest artificial competitor, and six times better than the best non-neural method.
[DEC] J. Schmidhuber (AI Blog, 02/20/2020, revised 2021). The 2010s: Our Decade of Deep Learning / Outlook on the 2020s. The recent decade's most important developments and industrial applications based on our AI, with an outlook on the 2020s, also addressing privacy and data markets.
[DEEP1]
Ivakhnenko, A. G. and Lapa, V. G. (1965). Cybernetic Predicting Devices. CCM Information Corporation. First working Deep Learners with many layers, learning internal representations.
[DEEP1a]
Ivakhnenko, Alexey Grigorevich. The group method of data of handling; a rival of the method of stochastic approximation. Soviet Automatic Control 13 (1968): 43-55.
[DEEP2]
Ivakhnenko, A. G. (1971). Polynomial theory of complex systems. IEEE Transactions on Systems, Man and Cybernetics, (4):364-378.
[DL1] J. Schmidhuber, 2015.
Deep learning in neural networks: An overview. Neural Networks, 61, 85-117.
More.
Got the first Best Paper Award ever issued by the journal Neural Networks, founded in 1988.
[DL2] J. Schmidhuber, 2015.
Deep Learning.
Scholarpedia, 10(11):32832.
[DL4] J. Schmidhuber (AI Blog, 2017).
Our impact on the world's most valuable public companies: Apple, Google, Microsoft, Facebook, Amazon... By 2015-17, neural nets developed in my labs were on over 3 billion devices such as smartphones, and used many billions of times per day, consuming a significant fraction of the world's compute. Examples: greatly improved (CTC-based) speech recognition on all Android phones, greatly improved machine translation through Google Translate and Facebook (over 4 billion LSTM-based translations per day), Apple's Siri and Quicktype on all iPhones, the answers of Amazon's Alexa, etc. Google's 2019
on-device speech recognition
(on the phone, not the server)
is still based on
LSTM.
[DL6]
F. Gomez and J. Schmidhuber.
Co-evolving recurrent neurons learn deep memory POMDPs.
In Proc. GECCO'05, Washington, D. C.,
pp. 1795-1802, ACM Press, New York, NY, USA, 2005.
PDF.
[DL6a]
J. Schmidhuber (AI Blog, Nov 2020). 15-year anniversary: 1st paper with "learn deep" in the title (2005). Our deep reinforcement learning & neuroevolution solved problems of depth 1000 and more.[DL6] Soon after its publication, everybody started talking about "deep learning." Causality or correlation?
[DLH]
J. Schmidhuber (AI Blog, 2022).
Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, IDSIA, Lugano, Switzerland, 2022.
Preprint arXiv:2212.11279.
Tweet of 2022.
[DLP]
J. Schmidhuber (AI Blog, 2023).
How 3 Turing awardees republished key methods and ideas whose creators they failed to credit.
Technical Report IDSIA-23-23, Swiss AI Lab IDSIA, 14 Dec 2023.
The piece is aimed at people who are not aware of the numerous AI priority disputes, but are willing to check the facts (see tweet).
[GPUNN]
Oh, K.-S. and Jung, K. (2004). GPU implementation of neural networks. Pattern Recognition, 37(6):1311-1314. Speeding up traditional NNs on GPU by a factor of 20.
[GPUCNN]
K. Chellapilla, S. Puri, P. Simard. High performance convolutional neural networks for document processing. International Workshop on Frontiers in Handwriting Recognition, 2006. Speeding up shallow CNNs on GPU by a factor of 4.
[GPUCNN1] D. C. Ciresan, U. Meier, J. Masci, L. M. Gambardella, J. Schmidhuber. Flexible, High Performance Convolutional Neural Networks for Image Classification. International Joint Conference on Artificial Intelligence (IJCAI-2011, Barcelona), 2011. PDF. ArXiv preprint.
Speeding up deep CNNs on GPU by a factor of 60.
Used to
win four important computer vision competitions 2011-2012 before others won any
with similar approaches.
[GPUCNN2] D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber.
A Committee of Neural Networks for Traffic Sign Classification.
International Joint Conference on Neural Networks (IJCNN-2011, San Francisco), 2011.
PDF.
HTML overview.
First superhuman performance in a computer vision contest, with half the error rate of humans, and one third the error rate of the closest competitor.[DAN1] This led to massive interest from industry.
[GPUCNN2a] D. Ciresan, A. Giusti, L. Gambardella, J. Schmidhuber.
Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images.
In Advances in Neural Information Processing Systems (NIPS 2012), Lake Tahoe,
2012. PDF.
First feedforward deep learner to win an image segmentation competition.
[GPUCNN3] D. C. Ciresan, U. Meier, J. Schmidhuber. Multi-column Deep Neural Networks for Image Classification. Proc. IEEE Conf. on Computer Vision and Pattern Recognition CVPR 2012, p 3642-3649, July 2012. PDF. Longer TR of Feb 2012: arXiv:1202.2745v1 [cs.CV]. More.
[GPUCNN4] A. Krizhevsky, I. Sutskever, G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. NIPS 25, MIT Press, Dec 2012.
PDF.
[GPUCNN5]
J. Schmidhuber (AI Blog, 2017; updated 2021 for 10th birthday of DanNet): History of computer vision contests won by deep CNNs since 2011. DanNet won 4 of them in a row before the similar AlexNet/VGG Net and the Resnet (a Highway Net with open gates) joined the party. Today, deep CNNs are standard in computer vision.
[GPUCNN6] J. Schmidhuber, D. Ciresan, U. Meier, J. Masci, A. Graves. On Fast Deep Nets for AGI Vision. In Proc. Fourth Conference on Artificial General Intelligence (AGI-11), Google, Mountain View, California, 2011.
PDF.
[GPUCNN7] D. C. Ciresan, A. Giusti, L. M. Gambardella, J. Schmidhuber. Mitosis Detection in Breast Cancer Histology Images using Deep Neural Networks. MICCAI 2013.
PDF.
[GPUCNN8] J. Schmidhuber. First deep learner to win a contest on object detection in large images—
first deep learner to win a medical imaging contest (2012). HTML.
How IDSIA used GPU-based CNNs to win the
ICPR 2012 Contest on Mitosis Detection
and the
MICCAI 2013 Grand Challenge.
[GPUCNN9]
K. Simonyan, A. Zisserman. Very deep convolutional networks for large-scale image recognition. Preprint arXiv:1409.1556 (2014).
[MIR] J. Schmidhuber (AI Blog, Oct 2019, updated 2025). Deep Learning: Our Miraculous Year 1990-1991. Preprint
arXiv:2005.05744. The deep learning neural networks (NNs) of our team have revolutionised pattern recognition & machine learning & AI. Many of the basic ideas behind this revolution were published within fewer than 12 months in our "Annus Mirabilis" 1990-1991 at TU Munich, including principles of (1)
LSTM, the most cited AI of the 20th century (based on constant error flow through residual connections); (2) ResNet, the most cited AI of the 21st century (based on our LSTM-inspired Highway Network, 10 times deeper than previous NNs); (3)
GAN (for artificial curiosity and creativity); (4) Transformer (the T in ChatGPT—see the 1991 Unnormalized Linear Transformer); (5) Pre-training for deep NNs (the P in ChatGPT); (6) NN distillation (see DeepSeek); (7) recurrent World Models, and more.
[MITOS1] ICPR 2012 Contest on Mitosis Detection in Breast Cancer Histological Images (MITOS dataset). More.
[MITOS2] L. Roux, D. Racoceanu, N. Lomenie, M. Kulikova, H. Irshad, J. Klossa, F. Capron, C. Genestie, G. Le Naour, M. N. Gurcan. Mitosis detection in breast cancer histological images - An ICPR 2012 contest. J Pathol. Inform. 4:8, 2013.
[MITOS3] MICCAI 2013 Grand Challenge on Mitosis Detection, organised by M. Veta, M.A. Viergever, J.P.W. Pluim, N. Stathonikos, P. J. van Diest of University Medical Center Utrecht. More.
[MLP1] D. C. Ciresan, U. Meier, L. M. Gambardella, J. Schmidhuber. Deep Big Simple Neural Nets For Handwritten Digit Recognition. Neural Computation 22(12): 3207-3220, 2010. ArXiv Preprint.
Showed that plain backprop for deep standard NNs is sufficient to break benchmark records, without any unsupervised pre-training.
[MLP2] J. Schmidhuber
(AI Blog, Sep 2020). 10-year anniversary of supervised deep learning breakthrough (2010). No unsupervised pre-training. By 2010, when compute was 100 times more expensive than today, both the feedforward NNs[MLP1] and the earlier recurrent NNs of Schmidhuber's team were able to beat all competing algorithms on important problems of that time.
[MLP3] J. Schmidhuber
(AI Blog, 2025). 2010: Breakthrough of end-to-end deep learning (no layer-by-layer training, no unsupervised pre-training). The rest is history.
By 2010, when compute was 1000 times more expensive than in 2025, both our feedforward NNs[MLP1] and our earlier recurrent NNs were able to beat all competing algorithms on important problems of that time.
This deep learning revolution quickly spread from Europe to North America and Asia.
[MOST]
J. Schmidhuber (AI Blog, 2021, updated 2025). The most cited neural networks all build on work done in my labs: 1. Long Short-Term Memory (LSTM), the most cited AI of the 20th century. 2. ResNet (open-gated Highway Net), the most cited AI of the 21st century. 3. AlexNet & VGG Net (the similar but earlier DanNet of 2011 won 4 image recognition challenges before them). 4. GAN (an instance of Adversarial Artificial Curiosity of 1990). 5. Transformer variants—see the 1991 unnormalised linear Transformer (ULTRA). Foundations of Generative AI were published in 1991: the principles of GANs (now used for deepfakes), Transformers (the T in ChatGPT), Pre-training for deep NNs (the P in ChatGPT), NN distillation, and the famous DeepSeek—see the tweet.
[UN]
J. Schmidhuber (AI Blog, 2021). 30-year anniversary. 1991: First very deep learning with unsupervised pre-training. First neural network distillation. Unsupervised hierarchical predictive coding (with self-supervised target generation) finds compact internal representations of sequential data to facilitate downstream deep learning. The hierarchy can be distilled into a single deep neural network (suggesting a simple model of conscious and subconscious information processing). 1993: solving problems of depth >1000.
[UN0]
J. Schmidhuber.
Neural sequence chunkers.
Technical Report FKI-148-91, Institut für Informatik, Technische
Universität München, April 1991.
PDF.
Unsupervised/self-supervised learning and predictive coding is used
in a deep hierarchy of recurrent neural networks (RNNs)
to find compact internal
representations of long sequences of data,
across multiple time scales and levels of abstraction.
Each RNN tries to solve the pretext task of predicting its next input, sending only unexpected inputs to the next RNN above.
The resulting compressed sequence representations
greatly facilitate downstream supervised deep learning such as sequence classification.
By 1993, the approach solved problems of depth 1000 [UN2]
(requiring 1000 subsequent computational stages/layers—the more such stages, the deeper the learning).
A variant collapses the hierarchy into a single deep net.
It uses a so-called conscious chunker RNN
which attends to unexpected events that surprise
a lower-level so-called subconscious automatiser RNN.
The chunker learns to understand the surprising events by predicting them.
The automatiser uses a
neural knowledge distillation procedure
to compress and absorb the formerly conscious insights and
behaviours of the chunker, thus making them subconscious.
The systems of 1991 allowed for much deeper learning than previous methods. More.
[UN1] J. Schmidhuber. Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242, 1992. Based on TR FKI-148-91, TUM, 1991.[UN0] PDF.
First working Deep Learner based on a deep RNN hierarchy (with different self-organising time scales),
overcoming the vanishing gradient problem through unsupervised pre-training and predictive coding (with self-supervised target generation).
Also: compressing or distilling a teacher net (the chunker) into a student net (the automatizer) that does not forget its old skills—such approaches are now widely used. See also this tweet. More.
[UN2] J. Schmidhuber. Habilitation thesis, TUM, 1993. PDF.
An ancient experiment on "Very Deep Learning" with credit assignment across 1200 time steps or virtual layers and unsupervised / self-supervised pre-training for a stack of recurrent NN
can be found here (depth > 1000).
.