On 14 June 2022, a science tabloid that published
this article [LEC22b] (24 June)
on LeCun's report "A Path Towards Autonomous Machine Intelligence" [LEC22a] (27 June) sent me a draft of [LEC22a] (back then still under embargo) and asked for comments. I wrote a review (see below), telling them that this is essentially a rehash of our previous work that LeCun did not mention. My comments, however, fell on deaf ears. Now I am posting my not so enthusiastic remarks here such that the history of our field does not become further corrupted. The images below link to relevant blog posts from the
AI Blog.
I would like to start this by acknowledging that I am not without a conflict of interest here; my seeking to correct the record will naturally seem self-interested. The truth of the matter is that it is. Much of the closely related work pointed to below was done in my lab, and I naturally wish that it be acknowledged, and recognized. Setting my conflict aside, I ask the reader to study the original papers and judge for themselves the scientific content of these remarks, as I seek to set emotions aside and minimize bias so much as I am capable.
★ LeCun writes: "Many ideas described in this paper (almost all of them) have been formulated by many authors in various contexts in various form."
In fact, unfortunately, much of the paper reads like a déjà vu of our papers since 1990, without citation. Years ago we have already published most of what LeCun calls his "main original contributions" [LEC22a]. More on this below.
★ LeCun writes: "There are three main challenges that AI research must address today: (1) How can machines learn to represent the world, learn to predict, and learn to act largely by observation? ... (2) How can machine reason and plan in ways that are compatible with gradient-based learning? ... (3) How can machines learn to represent percepts (3a) and action plans (3b) in a hierarchical manner, at multiple levels of abstraction, and multiple time scales?"
These questions were addressed in detail in a series of papers published in 1990, 1991, 1997, and 2015. Since then we have elaborated upon these papers. Let me first focus on (1) and (2), then on (3a) and (3b).
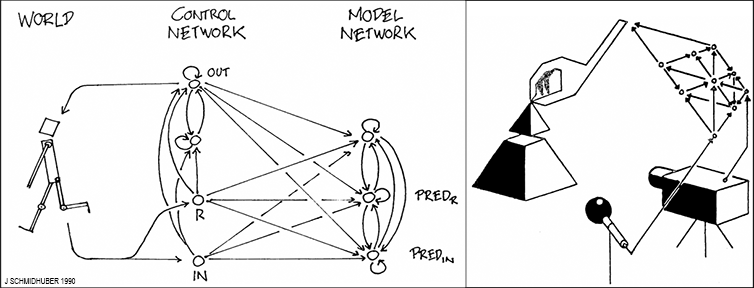
In 1990, I published the first works on gradient-based artificial neural networks (NNs) for long-term planning & reinforcement learning (RL) & exploration through artificial curiosity [AC90][PLAN2]. The well-known report "Making the world differentiable ..."
[AC90] (which spawned several conference publications, e.g., [PLAN2-3]) introduced several concepts mentioned by LeCun that are now widely used.
It describes a combination of two
recurrent neural networks (RNNs, the most powerful NNs) called the controller and the world model. The controller tries to emit sequences of actions that maximize cumulative expected
vector-valued (not necessarily scalar) pain and pleasure signals (special inputs to the controller) in an initially unknown environment. The world model learns to predict the consequences of the controller's actions. The controller can use the world model to plan ahead for several time steps through what's now called a rollout, selecting action sequences that maximise predicted reward [AC90][PLAN2].
This integrated architecture for learning, planning, and reacting was apparently published
[AC90][PLAN2]
before the important, related RL DYNA planner [DYNA90-91] cited by LeCun. [AC90] also cites relevant work on less general control and
system identification with feedforward
NNs (FNNs) that predates the FNN work cited by LeCun, who claims that this goes back to the early 1990s although the first papers appeared in the 1980s, e.g., [MUN87][WER87-89][NGU89] (compare Sec. 6 of [DL1]).
See also Sec. 11 of [MIR]
and our 1990 application of world models to the
learning of sequential attention and active foveation
[ATT][ATT0-2] (emphasized by LeCun [LEC22b]).
The approach led to lots of follow-up publications, not only
in 1990-91 [PLAN2-3][PHD],
but also in more recent years, e.g., [PLAN4-6].
In the beginning, the world model knows nothing. Which experiments should the controller invent to obtain data that will improve the world model? To solve this problem,
the 1990 paper [AC90] introduced
artificial curiosity [AC90b] or intrinsic motivation (emphasized by LeCun's abstract [LEC22b]) through
NNs that are both generative and adversarial—the 2014 generative adversarial NN [GAN1] cited by LeCun is actually a simple version of my 1990 approach [AC20][R2].
My well-known 2010 survey [AC10] summarised the GANs of 1990 as follows: a
"neural network as a predictive world model is used to maximize the controller's intrinsic reward, which is proportional to the model's prediction errors" (which are minimized).
See my
priority dispute on GANs [T22] with LeCun's co-author (who unsurprisingly had rather positive comments [LEC22b] on LeCun's article [LEC22a]).
In the 2010s [DEC], these concepts
became popular as
compute became cheaper. Our work of 1997-2002 [AC97][AC99][AC02] and more recent work since 2015 [PLAN4-5][OBJ2-4] go beyond the "millisecond by millisecond
planning" [PLAN] of 1990 [AC90][PLAN2], addressing planning and reasoning in abstract
concept spaces (emphasized by LeCun) and
learning to think [PLAN4],
including LeCun's "learning to act largely by observation"— see item (1) above.
The cartoon on top of the present page is based on Figure 1 in [PLAN4]: C denotes the recurrent control network, M the recurrent predictive world model which may be good at predicting some things but uncertain about others. C maximizes its objective function by learning to query (a copy of) M through sequences of self-invented questions (activation patterns) and to interpret the answers (more activation patterns). That is, in principle, C can profit from being able to extract any type of algorithmic information [KO0-2][CO1-3][PLAN4-5] from M, e.g., for hierarchical planning and reasoning, analogy building, etc.
Here is an illustrative quote from [PLAN4] (2015) on how C can learn from passive observations (frequently mentioned by LeCun [LEC22a]) encoded in M: "For example, suppose that M has learned to represent (e.g., through predictive coding)
videos of people placing toys in boxes,
or to summarize such videos through textual outputs.
Now suppose C's task is to learn to control a robot that places toys in boxes.
Although the robot's actuators may be quite different from human arms and hands,
and although videos and video-describing texts are quite different from desirable trajectories of
robot movements, M is expected to convey algorithmic information about C's task, perhaps in form of connected
high-level spatio-temporal feature detectors representing typical movements of hands and elbows independent of arm size.
Learning a [weight matrix of C] that addresses and extracts this information from M and partially reuses it to solve the robot's task may
be much faster than learning to solve the task from scratch without access to M" [PLAN4-5].
(See also the related "fingerprinting" and its recent applications [PEVN][GPE][GGP].)
[PLAN4] also explains concepts such as mirror neurons.
My agents with adaptive recurrent
world models even suggest a simple explanation of self-awareness and consciousness (mentioned by LeCun), dating back three decades [CON16]. Here is my 2020 overview page [PLAN] on this:
30-year anniversary of planning & reinforcement learning with recurrent world models and artificial curiosity (1990).
(3a) Answer regarding NN-based hierarchical percepts: this was already at least partially solved by my
first very deep learning machine
of 1991,
the neural sequence chunker aka neural history compressor
[UN][UN0-UN2] (see also [UN3]). It uses
unsupervised learning and predictive coding
in a deep hierarchy of recurrent neural networks (RNNs)
to find compact internal
representations of long sequences of data, at multiple levels of abstraction and multiple time scales (exactly what LeCun is writing about).
This greatly facilitates downstream supervised deep learning such as sequence classification.
By 1993, the approach solved problems of depth 1000
(requiring 1000 subsequent computational stages/layers—the more such stages, the deeper the learning).
A variant collapses the hierarchy into a single deep net.
It uses a so-called conscious chunker RNN
which attends to unexpected events that surprise
a lower-level so-called subconscious automatiser RNN.
The chunker learns to understand the surprising events by predicting them.
The automatiser uses my
neural knowledge distillation procedure
of 1991
[UN0-UN2]
to compress and absorb the formerly conscious insights and
behaviours of the chunker, thus making them subconscious.
The systems of 1991 allowed for much deeper learning than previous methods. Here is my 2021 overview page [UN] on this:
30-year anniversary. 1991: First very deep learning with unsupervised pre-training.
(See also the 1993 work on continuous history compression [UN3] and our 1995 neural probabilistic language model based on predictive coding [SNT].)

Furthermore, our more recent 2021 hierarchical world model [OBJ4] also explicitly distinguishes multiple levels of abstraction (to capture objects, parts, and their relations) to improve at modeling the visual world. Regarding LeCun's section 8.3.3 "Do We Need Symbols for Reasoning?," we have previously argued [BIND] for the importance of incorporating inductive biases in NNs that enable them to efficiently learn about symbols (e.g., [SYM1-3]) and the processes for manipulating them. Currently, many NNs suffer from a binding problem, which affects their ability to dynamically and flexibly combine (bind) information that is distributed throughout the NN, as is required to effectively form, represent, and relate symbol-like entities. Our 2020 position/survey paper [BIND] offers a conceptual framework for addressing this problem and provides an in-depth analysis of the challenges, requirements, and corresponding inductive biases required for symbol manipulation to emerge naturally in NNs.
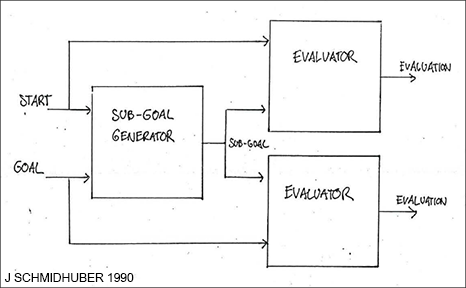 (3b) Answer regarding NN-based hierarchical action plans: already in 1990, this problem was at least partially solved through my Hierarchical Reinforcement Learning (HRL) with
end-to-end differentiable NN-based subgoal generators [HRL0], also with
recurrent NNs that learn to generate sequences of subgoals [HRL1-2][PHD].
An RL machine gets extra command inputs of the form (start, goal). An evaluator NN learns to predict the current rewards/costs of going from start to goal. An (R)NN-based subgoal generator also sees (start, goal), and uses (copies of) the evaluator NN to learn by gradient descent a sequence of cost-minimising intermediate subgoals. The RL machine tries to use such subgoal sequences to achieve final goals.
LeCun writes: "A general formulation can be done with the framework of Energy-Based Models (EBM).
The system is a scalar-valued function F(x,y) that produces low energy values when x and
y are compatible and higher values when they are not." That's exactly what the evaluator of our 1990 subgoal generator implements,
where x and y are start and goal, respectively.
The system is learning action plans
at multiple levels of abstraction and multiple time scales (exactly what LeCun is writing about).
Here is my 2021 overview [MIR] (Sec. 10):
Deep Learning: Our Miraculous Year 1990-1991.
(There are many more recent papers on "work on command," e.g.,
[ATT1][PP][PPa][PP1][SWA22][UDRL1-2][GGP].)
(3b) Answer regarding NN-based hierarchical action plans: already in 1990, this problem was at least partially solved through my Hierarchical Reinforcement Learning (HRL) with
end-to-end differentiable NN-based subgoal generators [HRL0], also with
recurrent NNs that learn to generate sequences of subgoals [HRL1-2][PHD].
An RL machine gets extra command inputs of the form (start, goal). An evaluator NN learns to predict the current rewards/costs of going from start to goal. An (R)NN-based subgoal generator also sees (start, goal), and uses (copies of) the evaluator NN to learn by gradient descent a sequence of cost-minimising intermediate subgoals. The RL machine tries to use such subgoal sequences to achieve final goals.
LeCun writes: "A general formulation can be done with the framework of Energy-Based Models (EBM).
The system is a scalar-valued function F(x,y) that produces low energy values when x and
y are compatible and higher values when they are not." That's exactly what the evaluator of our 1990 subgoal generator implements,
where x and y are start and goal, respectively.
The system is learning action plans
at multiple levels of abstraction and multiple time scales (exactly what LeCun is writing about).
Here is my 2021 overview [MIR] (Sec. 10):
Deep Learning: Our Miraculous Year 1990-1991.
(There are many more recent papers on "work on command," e.g.,
[ATT1][PP][PPa][PP1][SWA22][UDRL1-2][GGP].)
★ LeCun writes: "Our best approaches to learning rely on estimating and using the gradient of a loss."
This is true for some tasks, but not for many others. For example, simple problems such as the general parity problem [GUESS][LSTM1] or Towers of Hanoi [OOPS2] cannot easily be learned by gradient descent from large training examples. See, e.g., our work since 2002 on
asymptotically optimal curriculum learning through incremental universal search for problem-solving programs [OOPS1-3].
★ LeCun writes: "Because both submodules of the cost module are differentiable, the gradient of the energy can be back-propagated through the other modules, particularly the world model, the actor and the perception, for planning, reasoning, and learning."
That's exactly what I published in 1990 (see above), citing less general 1980s work on
system identification with feedforward
NNs [MUN87][WER87-89][NGU89] (see also Sec. 6 of [DL1]).
And in the early 2000s, my former postdoc Marcus Hutter even published theoretically optimal, universal, non-differentiable methods for learning both world model and controller [UNI].
(See also the mathematically optimal
self-referential AGI called the Gödel Machine [GM3-9].)
★ LeCun writes: "The short-term memory module ... architecture may be similar to that of Key-Value Memory Networks."
He does not mention, however, that I published the first such "Key-Value Memory Networks" in 1991 [FWP0-1,6], when I described sequence-processing "Fast Weight Controllers" or Fast Weight Programmers (FWPs). Such an FWP has a slow NN that learns by backpropagation [BP1-6][BPA-C] to rapidly modify the fast weights of another NN [FWP0-1]. The slow net does that by programming the fast net through outer products of self-invented Key-Value pairs (back then called From-To pairs). Today this is known as a linear Transformer [TR5-6] (without the softmax operation of modern Transformers [TR1-4]). In 1993, I also introduced the attention terminology [FWP2] now used in this context [ATT][FWP2]. Basically, I separated storage and control like in traditional computers,
but in a fully neural way (rather than in a hybrid fashion [PDA1][PDA2][DNC]). Here is my 2021 overview page on this: 26 Mar 1991: Neural nets learn to program neural nets with fast weights—like today's Transformer variants. 2021: New stuff!
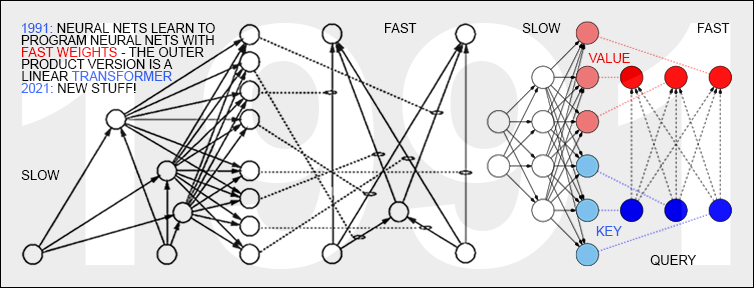
In fact, our very recent work on goal-conditioned generators of deep policies [GGP] (submitted in May 2022) has a Fast Weight Programmer that learns to obey commands of the form "generate a policy (an NN weight matrix) that achieves a desired expected return," generalizing Upside-Down RL [UDRL1-2], building on
Parameter-Based Value Functions [PBVF] and Policy Evaluation Networks [PEVN].
[GGP] exhibits competitive performance on a set of continuous control tasks, basically playing the role of LeCun's unspecified "configurator" which is supposed to configure other modules "for the task at hand by modulating their parameters and their attention circuits" [LEC22a].
See also our other very recent paper [GPE] (and references therein) on evaluating/improving weight matrices that are control policies.
On the other hand, LeCun also writes: "Perhaps the most important function of the configurator is to set subgoals for the agent and to configure the cost module for this subgoal." We implemented such an adaptive subgoal generator 3 decades ago [HRL0-2][PHD]—see item (3b) above.
★ LeCun writes: "The centerpiece of this paper is the Joint Embedding Predictive Architecture (JEPA). ... The main advantage of JEPA is that it performs predictions in representation space, eschewing the need to predict every detail of y."
This is what I published in the context of control in 1997-2002 [AC97][AC99][AC02]. Before 1997, the world models of our RL systems tried to predict all the details of future inputs, e.g., pixels [AC90-95]. But in 1997, a quarter-century ago [25y97], I built more general adversarial RL machines that could ignore many or all of these details and ask arbitrary abstract questions with computable answers in "representation space" [AC97][AC99][AC02]. For example, an agent may ask itself: if we run this policy (or program) for a while until it executes a special interrupt action, will the internal storage cell number 15 (a latent variable in representation space) contain the value 5, or not? The agent actually consists of two learning, reward-maximizing adversaries (called "left brain" and "right brain") playing a zero sum game, occasionally betting on different yes/no outcomes of such computational experiments. The winner of such a bet gets a reward of 1, the loser -1. So each brain is motivated to come up with questions whose answers surprise the other, until the answers become predictable and boring. Experiments showed that this type of abstraction-based curiosity may also accelerate the intake of external reward [AC97][AC02]. Here is my 2021 overview blog page [AC] on this (see Sec. 4):
Artificial Curiosity & Creativity Since 1990-91.
Note also that even our earlier, less general approaches to artificial curiosity since 1991 [AC91-95] naturally direct the world model towards representing predictable details in the environment, by rewarding a data-selecting controller for improvements of the world model. See Sections 2-5 of the overview [AC].

★ LeCun writes: "a JEPA can choose to train its encoders to eliminate irrelevant details of the inputs so as to make the representations more predictable. In other words, a JEPA will learn abstract representations that make the world predictable."
That's what we published in very general form for RL systems in 1997
[AC97][AC99][AC02] (title: "Exploring the Predictable"). See also earlier work on much less general supervised systems, e.g., "Discovering Predictable Classifications" (1992) [PMax], extending [IMAX] (1989). The
science tabloid article [LEC22b] also focuses on this issue, acting as if LeCun had some novel insight here, although it's really an old hat.
★ LeCun writes: "One question that is left unanswered is how the configurator can learn to decompose a complex task into a sequence of subgoals that can individually be accomplished by the agent. I shall leave this question open for future investigation."
Far from a future investigation, we published the first systems doing exactly this 3 decades ago when compute was a million times more expensive than today: learning to decompose by gradient descent "a complex task into a sequence of subgoals that can individually be accomplished by the agent" [HRL0-2][PHD]—see (3b) above and
Sec. 10 of "Deep Learning: Our Miraculous Year 1990-1991."
See also [HRL4] on a different approach (1997) to this problem, with my student Marco Wiering. I could point to many additional papers of ours on exactly this topic.
★ LeCun writes: "Perhaps the main original contributions of the paper reside in
(I) an overall cognitive architecture in which all modules are differentiable and many of
them are trainable.
(II) H-JEPA: a non-generative hierarchical architecture for predictive world models that
learn representations at multiple levels of abstraction and multiple time scales.
(III) a family of non-contrastive self-supervised learning paradigm that produces representations
that are simultaneously informative and predictable.
(IV) a way to use H-JEPA as the basis of predictive world models for hierarchical planning
under uncertainty."
Given my comments above, I cannot see any significant novelty here. Of course, I am not claiming that everything is solved. Nevertheless, in the past 32 years, we have already made substantial progress along the lines "proposed" by LeCun. I am referring the interested reader again to (I) our
"cognitive architectures in which all modules are differentiable and many of them are trainable" [HAB][PHD][AC90][AC90b][AC][HRL0-2][PLAN2-5], (II) our "hierarchical architecture for predictive world models that
learn representations at multiple levels of abstraction and multiple time scales" [UN,UN0-3], (III) our "self-supervised learning paradigm that produces
representations that are simultaneously informative and predictable" [AC97][AC99][AC02]([PMax]), and (IV) our predictive models "for hierarchical planning under uncertainty" [PHD][HRL0-2][PLAN4-5]. In particular, the work of 1997-2002 [AC97][AC99][AC02][AC] and more recent work since 2015 [PLAN4-5][OBJ2-4][BIND] focuses on reasoning in abstract
concept spaces and learning to think [PLAN4]. I am also recommending the work on Fast Weight Programmers (FWPs) and "Key-Value Memory Networks" since 1991 [FWP0-6][FWPMETA1-10] (recall LeCun's "configurator" [LEC22a]), including our recent work since 2020 [FWP6-7][FWPMETA6-9][GGP][GPE]. All of this is closely connected to our
metalearning machines that learn to learn (since 1987) [META].
★ LeCun writes: "Below is an attempt to connect the present proposal with relevant prior work. Given the scope of the proposal, the references cannot possibly be exhaustive." Then he goes on citing a few somewhat related, mostly relatively recent works, while ignoring most of the directly relevant original work mentioned above, possibly encouraged by an
award that he and his colleagues shared for inventions of other researchers whom they did not cite [T22].

Perhaps some of the prior work that I note here was simply unknown to LeCun. The point of this post is not to attack the ideas reflected in the paper under review, or its author. The point is that these ideas are not as new as may be understood by reading LeCun's paper. There is much prior work that is directly along the lines proposed, by my lab, and by others. I have naturally placed some emphasis on my own prior work, which has focused for decades on what LeCun now calls his "main original contributions,"
and hope the readers will judge for themselves the validity of my comments.
Acknowledgments
 Thanks to several machine learning experts for useful comments. Since science is about self-correction, let me know under juergen@idsia.ch if you can spot any remaining error. The contents of this article may be used for educational and non-commercial purposes, including articles for Wikipedia and similar sites. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Thanks to several machine learning experts for useful comments. Since science is about self-correction, let me know under juergen@idsia.ch if you can spot any remaining error. The contents of this article may be used for educational and non-commercial purposes, including articles for Wikipedia and similar sites. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
References
[25y97]
In 2022, we are celebrating the following works from a quarter-century ago.
1. Journal paper on Long Short-Term Memory, the
most cited neural network (NN) of the 20th century
(and basis of the most cited NN of the 21st).
2. First paper on physical, philosophical and theological consequences of the simplest and fastest way of computing
all possible metaverses
(= computable universes).
3. Implementing artificial curiosity and creativity through generative adversarial agents that learn to design abstract, interesting computational experiments.
4. Journal paper on
meta-reinforcement learning.
5. Journal paper on hierarchical Q-learning.
6. First paper on reinforcement learning to play soccer: start of a series.
7. Journal papers on flat minima & low-complexity NNs that generalize well.
8. Journal paper on Low-Complexity Art, the Minimal Art of the Information Age.
9. Journal paper on probabilistic incremental program evolution.
[AC]
J. Schmidhuber (AI Blog, 2021). 3 decades of artificial curiosity & creativity. Our artificial scientists not only answer given questions but also invent new questions. They achieve curiosity through: (1990) the principle of generative adversarial networks, (1991) neural nets that maximise learning progress, (1995) neural nets that maximise information gain (optimally since 2011), (1997) adversarial design of surprising computational experiments, (2006) maximizing compression progress like scientists/artists/comedians do, (2011) PowerPlay... Since 2012: applications to real robots.
[AC90]
J. Schmidhuber.
Making the world differentiable: On using fully recurrent
self-supervised neural networks for dynamic reinforcement learning and
planning in non-stationary environments.
Technical Report FKI-126-90, TUM, Feb 1990, revised Nov 1990.
PDF.
The first paper on long-term planning with reinforcement learning recurrent neural networks (NNs) (more) and on generative adversarial networks
where a generator NN is fighting a predictor NN in a minimax game
(more).
[AC90b]
J. Schmidhuber.
A possibility for implementing curiosity and boredom in
model-building neural controllers.
In J. A. Meyer and S. W. Wilson, editors, Proc. of the
International Conference on Simulation
of Adaptive Behavior: From Animals to
Animats, pages 222-227. MIT Press/Bradford Books, 1991.
PDF.
More.
[AC91]
J. Schmidhuber. Adaptive confidence and adaptive curiosity. Technical Report FKI-149-91, Inst. f. Informatik, Tech. Univ. Munich, April 1991.
PDF.
[AC91b]
J. Schmidhuber.
Curious model-building control systems.
In Proc. International Joint Conference on Neural Networks,
Singapore, volume 2, pages 1458-1463. IEEE, 1991.
PDF.
[AC95]
J. Storck, S. Hochreiter, and J. Schmidhuber. Reinforcement-driven information acquisition in non-deterministic environments. In Proc. ICANN'95, vol. 2, pages 159-164. EC2 & CIE, Paris, 1995. PDF.
[AC97]
J. Schmidhuber.
What's interesting?
Technical Report IDSIA-35-97, IDSIA, July 1997.
[Focus
on automatic creation of predictable internal
abstractions of complex spatio-temporal events:
two competing, intrinsically motivated agents agree on essentially
arbitrary algorithmic experiments and bet
on their possibly surprising (not yet predictable)
outcomes in zero-sum games,
each agent potentially profiting from outwitting / surprising
the other by inventing experimental protocols where both
modules disagree on the predicted outcome. The focus is on exploring
the space of general algorithms (as opposed to
traditional simple mappings from inputs to
outputs); the
general system
focuses on the interesting
things by losing interest in both predictable and
unpredictable aspects of the world. Unlike our previous
systems with intrinsic motivation,[AC90-AC95] the system also
takes into account
the computational cost of learning new skills, learning when to learn and what to learn.
See later publications.[AC99][AC02]]
[AC98]
M. Wiering and J. Schmidhuber.
Efficient model-based exploration.
In R. Pfeiffer, B. Blumberg, J. Meyer, S. W. Wilson, eds.,
From Animals to Animats 5: Proceedings
of the Fifth International Conference on Simulation of Adaptive
Behavior, p. 223-228, MIT Press, 1998.
[AC98b]
M. Wiering and J. Schmidhuber.
Learning exploration policies with models.
In Proc. CONALD, 1998.
[AC99]
J. Schmidhuber.
Artificial Curiosity Based on Discovering Novel Algorithmic
Predictability Through Coevolution.
In P. Angeline, Z. Michalewicz, M. Schoenauer, X. Yao, Z.
Zalzala, eds., Congress on Evolutionary Computation, p. 1612-1618,
IEEE Press, Piscataway, NJ, 1999.
[AC02]
J. Schmidhuber.
Exploring the Predictable.
In Ghosh, S. Tsutsui, eds., Advances in Evolutionary Computing,
p. 579-612, Springer, 2002.
PDF.
[AC05]
J. Schmidhuber.
Self-Motivated Development Through
Rewards for Predictor Errors / Improvements.
Developmental Robotics 2005 AAAI Spring Symposium,
March 21-23, 2005, Stanford University, CA.
PDF.
[AC06]
J. Schmidhuber.
Developmental Robotics,
Optimal Artificial Curiosity, Creativity, Music, and the Fine Arts.
Connection Science, 18(2): 173-187, 2006.
PDF.
[AC07]
J. Schmidhuber.
Simple Algorithmic Principles of Discovery, Subjective Beauty,
Selective Attention, Curiosity & Creativity.
In V. Corruble, M. Takeda, E. Suzuki, eds.,
Proc. 10th Intl. Conf. on Discovery Science (DS 2007)
p. 26-38, LNAI 4755, Springer, 2007.
Also in M. Hutter, R. A. Servedio, E. Takimoto, eds.,
Proc. 18th Intl. Conf. on Algorithmic Learning Theory (ALT 2007)
p. 32, LNAI 4754, Springer, 2007.
(Joint invited lecture for DS 2007 and ALT 2007, Sendai, Japan, 2007.)
Preprint: arxiv:0709.0674.
PDF.
Curiosity as the drive to improve the compression
of the lifelong sensory input stream: interestingness as
the first derivative of subjective "beauty" or compressibility.
[AC08]
Driven by Compression Progress. In Proc.
Knowledge-Based Intelligent Information and
Engineering Systems KES-2008,
Lecture Notes in Computer Science LNCS 5177, p 11, Springer, 2008.
(Abstract of invited keynote talk.)
PDF.
[AC09]
J. Schmidhuber. Art & science as by-products of the search for novel patterns, or data compressible in unknown yet learnable ways. In M. Botta (ed.), Et al. Edizioni, 2009, pp. 98-112.
PDF. (More on
artificial scientists and artists.)
[AC09a]
J. Schmidhuber.
Driven by Compression Progress: A Simple Principle Explains Essential Aspects of Subjective Beauty, Novelty, Surprise, Interestingness, Attention, Curiosity, Creativity, Art, Science, Music, Jokes.
Based on keynote talk for KES 2008 (below) and joint invited
lecture for ALT 2007 / DS 2007 (below). Short version: ref 17 below. Long version in G. Pezzulo, M. V. Butz, O. Sigaud, G. Baldassarre, eds.: Anticipatory Behavior in Adaptive Learning Systems, from Sensorimotor to Higher-level Cognitive Capabilities, Springer, LNAI, 2009.
Preprint (2008, revised 2009): arXiv:0812.4360.
PDF (Dec 2008).
PDF (April 2009).
[AC09b]
J. Schmidhuber.
Simple Algorithmic Theory of Subjective Beauty, Novelty, Surprise,
Interestingness, Attention, Curiosity, Creativity, Art,
Science, Music, Jokes. Journal of SICE, 48(1):21-32, 2009.
PDF.
[AC10]
J. Schmidhuber. Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990-2010). IEEE Transactions on Autonomous Mental Development, 2(3):230-247, 2010.
IEEE link.
PDF.
[AC10a]
J. Schmidhuber. Artificial Scientists & Artists Based on the Formal Theory of Creativity.
In
Proceedings of the Third Conference on Artificial General Intelligence (AGI-2010), Lugano, Switzerland.
PDF.
[AC11]
Sun Yi, F. Gomez, J. Schmidhuber.
Planning to Be Surprised: Optimal Bayesian Exploration in Dynamic Environments.
In Proc. Fourth Conference on Artificial General Intelligence (AGI-11),
Google, Mountain View, California, 2011.
PDF.
[AC11a]
V. Graziano, T. Glasmachers, T. Schaul, L. Pape, G. Cuccu, J. Leitner, J. Schmidhuber. Artificial Curiosity for Autonomous Space Exploration. Acta Futura 4:41-51, 2011 (DOI: 10.2420/AF04.2011.41). PDF.
[AC11b]
G. Cuccu, M. Luciw, J. Schmidhuber, F. Gomez.
Intrinsically Motivated Evolutionary Search for Vision-Based Reinforcement Learning.
In Proc. Joint IEEE International Conference on Development and Learning (ICDL) and on Epigenetic Robotics (ICDL-EpiRob 2011), Frankfurt, 2011.
PDF.
[AC11c]
M. Luciw, V. Graziano, M. Ring, J. Schmidhuber.
Artificial Curiosity with Planning for Autonomous Visual and Perceptual Development.
In Proc. Joint IEEE International Conference on Development and Learning (ICDL) and on Epigenetic Robotics (ICDL-EpiRob 2011), Frankfurt, 2011.
PDF.
[AC11d]
T. Schaul, L. Pape, T. Glasmachers, V. Graziano J. Schmidhuber.
Coherence Progress: A Measure of Interestingness Based on Fixed Compressors.
In Proc. Fourth Conference on Artificial General Intelligence (AGI-11),
Google, Mountain View, California, 2011.
PDF.
[AC11e]
T. Schaul, Yi Sun, D. Wierstra, F. Gomez, J. Schmidhuber. Curiosity-Driven Optimization. IEEE Congress on Evolutionary Computation (CEC-2011), 2011.
PDF.
[AC11f]
H. Ngo, M. Ring, J. Schmidhuber.
Curiosity Drive based on Compression Progress for Learning Environment Regularities.
In Proc. Joint IEEE International Conference on Development and Learning (ICDL) and on Epigenetic Robotics (ICDL-EpiRob 2011), Frankfurt, 2011.
[AC12]
L. Pape, C. M. Oddo, M. Controzzi, C. Cipriani, A. Foerster, M. C. Carrozza, J. Schmidhuber.
Learning tactile skills through curious exploration.
Frontiers in Neurorobotics 6:6, 2012, doi: 10.3389/fnbot.2012.00006
[AC12a]
H. Ngo, M. Luciw, A. Foerster, J. Schmidhuber.
Learning Skills from Play: Artificial Curiosity on a Katana Robot Arm.
Proc. IJCNN 2012.
PDF.
Video.
[AC12b]
V. R. Kompella, M. Luciw, M. Stollenga, L. Pape, J. Schmidhuber.
Autonomous Learning of Abstractions using Curiosity-Driven Modular Incremental Slow Feature Analysis.
Proc. IEEE Conference on Development and Learning / EpiRob 2012
(ICDL-EpiRob'12), San Diego, 2012.
[AC12c]
J. Schmidhuber. Maximizing Fun By Creating Data With Easily Reducible Subjective Complexity.
In G. Baldassarre and M. Mirolli (eds.), Roadmap for Intrinsically Motivated Learning.
Springer, 2012.
[AC20]
J. Schmidhuber. Generative Adversarial Networks are Special Cases of Artificial Curiosity (1990) and also Closely Related to Predictability Minimization (1991).
Neural Networks, Volume 127, p 58-66, 2020.
Preprint arXiv/1906.04493.
[ATT] J. Schmidhuber (AI Blog, 2020). 30-year anniversary of end-to-end differentiable sequential neural attention. Plus goal-conditional reinforcement learning. We had both hard attention[ATT0-2] (1990) and soft attention (1991-93).[FWP] Today, both types are very popular.
[ATT0] J. Schmidhuber and R. Huber.
Learning to generate focus trajectories for attentive vision.
Technical Report FKI-128-90, Institut für Informatik, Technische
Universität München, 1990.
PDF.
[ATT1] J. Schmidhuber and R. Huber. Learning to generate artificial fovea trajectories for target detection. International Journal of Neural Systems, 2(1 & 2):135-141, 1991. Based on TR FKI-128-90, TUM, 1990.
PDF.
More.
[ATT2]
J. Schmidhuber.
Learning algorithms for networks with internal and external feedback.
In D. S. Touretzky, J. L. Elman, T. J. Sejnowski, and G. E. Hinton,
editors, Proc. of the 1990 Connectionist Models Summer School, pages
52-61. San Mateo, CA: Morgan Kaufmann, 1990.
PS. (PDF.)
[BIND]
K. Greff, S. Van Steenkiste, J. Schmidhuber. On the binding problem in artificial neural networks.
Preprint: arXiv:2012.05208 (2020).
[BPA]
H. J. Kelley. Gradient Theory of Optimal Flight Paths. ARS Journal, Vol. 30, No. 10, pp. 947-954, 1960.
Precursor of modern backpropagation.[BP1-4]
[BPB]
A. E. Bryson. A gradient method for optimizing multi-stage allocation processes. Proc. Harvard Univ. Symposium on digital computers and their applications, 1961.
[BPC]
S. E. Dreyfus. The numerical solution of variational problems. Journal of Mathematical Analysis and Applications, 5(1): 30-45, 1962.
[BP1] S. Linnainmaa. The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's Thesis (in Finnish), Univ. Helsinki, 1970.
See chapters 6-7 and FORTRAN code on pages 58-60.
PDF.
See also BIT 16, 146-160, 1976.
Link.
The first publication on "modern" backpropagation, also known as the reverse mode of automatic differentiation.
[BP2] P. J. Werbos. Applications of advances in nonlinear sensitivity analysis. In R. Drenick, F. Kozin, (eds): System Modeling and Optimization: Proc. IFIP,
Springer, 1982.
PDF.
First application of backpropagation[BP1] to NNs (concretizing thoughts in his 1974 thesis).
[BP4] J. Schmidhuber (AI Blog, 2014; updated 2020).
Who invented backpropagation?
More.[DL2]
[BP5]
A. Griewank (2012). Who invented the reverse mode of differentiation?
Documenta Mathematica, Extra Volume ISMP (2012): 389-400.
[BP6]
S. I. Amari (1977).
Neural Theory of Association and Concept Formation.
Biological Cybernetics, vol. 26, p. 175-185, 1977.
See Section 3.1 on using gradient descent for learning in multilayer networks.
[CO1]
J. Koutnik, F. Gomez, J. Schmidhuber (2010). Evolving Neural Networks in Compressed Weight Space. Proceedings of the Genetic and Evolutionary Computation Conference
(GECCO-2010), Portland, 2010.
PDF.
[CO2]
J. Koutnik, G. Cuccu, J. Schmidhuber, F. Gomez.
Evolving Large-Scale Neural Networks for Vision-Based Reinforcement Learning.
In Proceedings of the Genetic and Evolutionary
Computation Conference (GECCO), Amsterdam, July 2013.
PDF.
[CO3]
R. K. Srivastava, J. Schmidhuber, F. Gomez.
Generalized Compressed Network Search.
Proc. GECCO 2012.
PDF.
[CON16]
J. Carmichael (2016).
Artificial Intelligence Gained Consciousness in 1991.
Why A.I. pioneer Jürgen Schmidhuber is convinced the ultimate breakthrough already happened.
Inverse, 2016. Link.
[DAN]
J. Schmidhuber (AI Blog, 2021).
10-year anniversary. In 2011, DanNet triggered the deep convolutional neural network (CNN) revolution. Named after my outstanding postdoc Dan Ciresan, it was the first deep and fast CNN to win international computer vision contests, and had a temporary monopoly on winning them, driven by a very fast implementation based on graphics processing units (GPUs).
1st superhuman result in 2011.[DAN1]
Now everybody is using this approach.
[DAN1]
J. Schmidhuber (AI Blog, 2011; updated 2021 for 10th birthday of DanNet): First superhuman visual pattern recognition.
At the IJCNN 2011 computer vision competition in Silicon Valley,
our artificial neural network called DanNet performed twice better than humans, three times better than the closest artificial competitor, and six times better than the best non-neural method.
[DEC] J. Schmidhuber (AI Blog, 02/20/2020; revised 2021). The 2010s: Our Decade of Deep Learning / Outlook on the 2020s. The recent decade's most important developments and industrial applications based on our AI, with an outlook on the 2020s, also addressing privacy and data markets.
[DEEP1]
Ivakhnenko, A. G. and Lapa, V. G. (1965). Cybernetic Predicting Devices. CCM Information Corporation. First working Deep Learners with many layers, learning internal representations.
[DEEP1a]
Ivakhnenko, Alexey Grigorevich. The group method of data of handling; a rival of the method of stochastic approximation. Soviet Automatic Control 13 (1968): 43-55.
[DEEP2]
Ivakhnenko, A. G. (1971). Polynomial theory of complex systems. IEEE Transactions on Systems, Man and Cybernetics, (4):364-378.
[DL1] J. Schmidhuber, 2015.
Deep learning in neural networks: An overview. Neural Networks, 61, 85-117.
More.
Got the first Best Paper Award ever issued by the journal Neural Networks, founded in 1988.
[DL2] J. Schmidhuber, 2015.
Deep Learning.
Scholarpedia, 10(11):32832.
[DNC] Hybrid computing using a neural network with dynamic external memory.
A. Graves, G. Wayne, M. Reynolds, T. Harley, I. Danihelka, A. Grabska-Barwinska, S. G. Colmenarejo, E. Grefenstette, T. Ramalho, J. Agapiou, A. P. Badia, K. M. Hermann, Y. Zwols, G. Ostrovski, A. Cain, H. King, C. Summerfield, P. Blunsom, K. Kavukcuoglu, D. Hassabis.
Nature, 538:7626, p 471, 2016.
[DYNA90]
R. S. Sutton (1990). Integrated Architectures for Learning, Planning, and Reacting Based on Approximating Dynamic Programming. Machine Learning Proceedings 1990, of the Seventh International Conference, Austin, Texas, June 21-23,
1990, p 216-224.
[DYNA91]
R. S. Sutton (1991). Dyna, an integrated architecture for learning, planning, and reacting. ACM Sigart Bulletin 2.4 (1991):160-163.
[FAST] C. v.d. Malsburg. Tech Report 81-2, Abteilung f. Neurobiologie,
Max-Planck Institut f. Biophysik und Chemie, Goettingen, 1981.
First paper on fast weights or dynamic links.
[FASTa]
J. A. Feldman. Dynamic connections in neural networks.
Biological Cybernetics, 46(1):27-39, 1982.
2nd paper on fast weights.
[FWP]
J. Schmidhuber (AI Blog, 26 March 2021).
26 March 1991: Neural nets learn to program neural nets with fast weights—like Transformer variants. 2021: New stuff!
30-year anniversary of a now popular
alternative[FWP0-1] to recurrent NNs.
A slow feedforward NN learns by gradient descent to program the changes of
the fast weights[FAST,FASTa] of
another NN.
Such Fast Weight Programmers[FWP0-7,FWPMETA1-9] can learn to memorize past data, e.g.,
by computing fast weight changes through additive outer products of self-invented activation patterns[FWP0-1]
(now often called keys and values for self-attention[TR1-6]).
The similar Transformers[TR1-2] combine this with projections
and softmax and
are now widely used in natural language processing.
For long input sequences, their efficiency was improved through
linear Transformers or Performers[TR5-6]
which are formally equivalent to the 1991 Fast Weight Programmers (apart from normalization).
In 1993, I introduced
the attention terminology[FWP2] now used
in this context,[ATT] and
extended the approach to
RNNs that program themselves.
[FWP0]
J. Schmidhuber.
Learning to control fast-weight memories: An alternative to recurrent nets.
Technical Report FKI-147-91, Institut für Informatik, Technische
Universität München, 26 March 1991.
PDF.
First paper on fast weight programmers: a slow net learns by gradient descent to compute weight changes of a fast net.
[FWP1] J. Schmidhuber. Learning to control fast-weight memories: An alternative to recurrent nets. Neural Computation, 4(1):131-139, 1992.
PDF.
HTML.
Pictures (German).
[FWP2] J. Schmidhuber. Reducing the ratio between learning complexity and number of time-varying variables in fully recurrent nets. In Proceedings of the International Conference on Artificial Neural Networks, Amsterdam, pages 460-463. Springer, 1993.
PDF.
First recurrent fast weight programmer based on outer products. Introduced the terminology of learning "internal spotlights of attention."
[FWP3] I. Schlag, J. Schmidhuber. Gated Fast Weights for On-The-Fly Neural Program Generation. Workshop on Meta-Learning, @N(eur)IPS 2017, Long Beach, CA, USA.
[FWP3a] I. Schlag, J. Schmidhuber. Learning to Reason with Third Order Tensor Products. Advances in Neural Information Processing Systems (N(eur)IPS), Montreal, 2018.
Preprint: arXiv:1811.12143. PDF.
[FWP4d]
Y. Tang, D. Nguyen, D. Ha (2020).
Neuroevolution of Self-Interpretable Agents.
Preprint: arXiv:2003.08165.
[FWP5]
F. J. Gomez and J. Schmidhuber.
Evolving modular fast-weight networks for control.
In W. Duch et al. (Eds.):
Proc. ICANN'05,
LNCS 3697, pp. 383-389, Springer-Verlag Berlin Heidelberg, 2005.
PDF.
HTML overview.
Reinforcement-learning fast weight programmer.
[FWP6] I. Schlag, K. Irie, J. Schmidhuber.
Linear Transformers Are Secretly Fast Weight Programmers. ICML 2021. Preprint: arXiv:2102.11174.
[FWP7] K. Irie, I. Schlag, R. Csordas, J. Schmidhuber.
Going Beyond Linear Transformers with Recurrent Fast Weight Programmers.
Advances in Neural Information Processing Systems (NeurIPS), 2021.
Preprint: arXiv:2106.06295 . See also the
Blog Post.
[FWPMETA1] J. Schmidhuber. Steps towards `self-referential' learning. Technical Report CU-CS-627-92, Dept. of Comp. Sci., University of Colorado at Boulder, November 1992.
First recurrent fast weight programmer that can learn
to run a learning algorithm or weight change algorithm on itself.
[FWPMETA2] J. Schmidhuber. A self-referential weight matrix.
In Proceedings of the International Conference on Artificial
Neural Networks, Amsterdam, pages 446-451. Springer, 1993.
PDF.
[FWPMETA3] J. Schmidhuber.
An introspective network that can learn to run its own weight change algorithm. In Proc. of the Intl. Conf. on Artificial Neural Networks,
Brighton, pages 191-195. IEE, 1993.
[FWPMETA4]
J. Schmidhuber.
A neural network that embeds its own meta-levels.
In Proc. of the International Conference on Neural Networks '93,
San Francisco. IEEE, 1993.
[FWPMETA5]
J. Schmidhuber. Habilitation thesis, TUM, 1993. PDF.
A recurrent neural net with a self-referential, self-reading, self-modifying weight matrix
can be found here.
[FWPMETA6]
L. Kirsch and J. Schmidhuber. Meta Learning Backpropagation & Improving It.
Advances in Neural Information Processing Systems (NeurIPS), 2021.
Preprint: arXiv:2012.14905.
[FWPMETA7]
I. Schlag, T. Munkhdalai, J. Schmidhuber.
Learning Associative Inference Using Fast Weight Memory.
ICLR 2021.
Report arXiv:2011.07831 [cs.AI], 2020.
[FWPMETA8]
K. Irie, I. Schlag, R. Csordas, J. Schmidhuber.
A Modern Self-Referential Weight Matrix That Learns to Modify Itself.
International Conference on Machine Learning (ICML), 2022.
Preprint: arXiv:2202.05780.
[FWPMETA9]
L. Kirsch and J. Schmidhuber.
Self-Referential Meta Learning.
First Conference on Automated Machine Learning (Late-Breaking Workshop), 2022.
[FWPMETA10]
L. Kirsch, S. Flennerhag, H. van Hasselt, A. Friesen, J. Oh, Y. Chen.
Introducing symmetries to black box meta reinforcement learning.
AAAI 2022, vol. 36(7), p 7207-7210, 2022.
[GAN1]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair,
A. Courville, Y. Bengio.
Generative adversarial nets. NIPS 2014, 2672-2680, Dec 2014.
Description of GANs that does not cite the original work of 1990[AC][AC90, AC90b][AC20][R2] (also containing wrong claims about
Predictability Minimization[PM0-2][AC20]).
[GGP]
F. Faccio, V. Herrmann, A. Ramesh, L. Kirsch, J. Schmidhuber.
Goal-Conditioned Generators of Deep Policies.
Preprint arXiv/2207.01570, 4 July 2022 (submitted in May 2022).
[GM3]
J. Schmidhuber (2003).
Gödel Machines: Self-Referential Universal Problem Solvers Making Provably Optimal Self-Improvements.
Preprint
arXiv:cs/0309048 (2003).
More.
[GM6]
J. Schmidhuber (2006).
Gödel machines:
Fully Self-Referential Optimal Universal Self-Improvers.
In B. Goertzel and C. Pennachin, eds.: Artificial
General Intelligence, p. 199-226, 2006.
PDF.
[GM9]
J. Schmidhuber (2009).
Ultimate Cognition à la Gödel.
Cognitive Computation 1(2):177-193, 2009. PDF.
More.
[GPE]
F. Faccio, A. Ramesh, V. Herrmann, J. Harb, J. Schmidhuber.
General Policy Evaluation and Improvement by Learning to Identify Few But Crucial States.
Preprint arXiv/2207.01566, 4 July 2022 (submitted in May 2022).
[GUESS]
J. Schmidhuber and S. Hochreiter.
Guessing can outperform many long time lag algorithms.
Technical Note IDSIA-19-96, IDSIA, May 1996.
[HAB]
J. Schmidhuber.
Netzwerkarchitekturen, Zielfunktionen und Kettenregel
(Network architectures, objective functions, and chain rule).
Habilitation (postdoctoral thesis - qualification for a
tenure professorship),
Institut für Informatik, Technische Universität
München, 1993.
PDF.
HTML.
[HRLW]
C. Watkins (1989). Learning from delayed rewards.
[HRL0]
J. Schmidhuber.
Towards compositional learning with dynamic neural networks.
Technical Report FKI-129-90, Institut für Informatik, Technische
Universität München, 1990.
PDF.
[HRL1]
J. Schmidhuber. Learning to generate sub-goals for action sequences. In T. Kohonen, K. Mäkisara, O. Simula, and J. Kangas, editors, Artificial Neural Networks, pages 967-972. Elsevier Science Publishers B.V., North-Holland, 1991. PDF. Extending TR FKI-129-90, TUM, 1990.
HTML & images in German.
[HRL2]
J. Schmidhuber and R. Wahnsiedler.
Planning simple trajectories using neural subgoal generators.
In J. A. Meyer, H. L. Roitblat, and S. W. Wilson, editors, Proc.
of the 2nd International Conference on Simulation of Adaptive Behavior,
pages 196-202. MIT Press, 1992.
PDF.
HTML without images.
HTML & images in German.
[HRL4]
M. Wiering and J. Schmidhuber.
HQ-Learning.
Adaptive Behavior 6(2):219-246, 1997 (122 K).
PDF.
[IMAX]
S. Becker, G. E. Hinton. Spatial coherence as an internal teacher for a neural network. TR CRG-TR-89-7, Dept. of CS, U. Toronto, 1989.
[KO0]
J. Schmidhuber.
Discovering problem solutions with low Kolmogorov complexity and
high generalization capability.
Technical Report FKI-194-94, Fakultät für Informatik,
Technische Universität München, 1994.
PDF.
[KO1] J. Schmidhuber.
Discovering solutions with low Kolmogorov complexity
and high generalization capability.
In A. Prieditis and S. Russell, editors, Machine Learning:
Proceedings of the Twelfth International Conference (ICML 1995),
pages 488-496. Morgan
Kaufmann Publishers, San Francisco, CA, 1995.
PDF.
[KO2]
J. Schmidhuber.
Discovering neural nets with low Kolmogorov complexity
and high generalization capability.
Neural Networks, 10(5):857-873, 1997.
PDF.
[LSTM1] S. Hochreiter, J. Schmidhuber. Long Short-Term Memory. Neural Computation, 9(8):1735-1780, 1997. PDF.
More.
[LEC22a]
Y. LeCun (27 June 2022).
A Path Towards Autonomous Machine Intelligence.
OpenReview Archive.
Link.
[LEC22b]
M. Heikkilä, W. D. Heaven.
Yann LeCun has a bold new vision for the future of AI.
MIT Technology Review, 24 June 2022.
Link.
[META]
J. Schmidhuber (2020). 1/3 century anniversary of
first publication on metalearning machines that learn to learn (1987).
For its cover I drew a robot that bootstraps itself.
1992-: gradient descent-based neural metalearning. 1994-: Meta-Reinforcement Learning with self-modifying policies. 1997: Meta-RL plus artificial curiosity and intrinsic motivation.
2002-: asymptotically optimal metalearning for curriculum learning. 2003-: mathematically optimal Gödel Machine. 2020: new stuff!
[MIR] J. Schmidhuber (AI Blog, Oct 2019, revised 2021). Deep Learning: Our Miraculous Year 1990-1991. Preprint
arXiv:2005.05744, 2020.
The deep learning neural networks of our team have revolutionised pattern recognition and machine learning, and are now heavily used in academia and industry. In 2020-21, we celebrate that many of the basic ideas behind this revolution were published within fewer than 12 months in our "Annus Mirabilis" 1990-1991 at TU Munich.
[MUN87]
P. W. Munro. A dual back-propagation scheme for scalar reinforcement learning. Proceedings of the Ninth Annual Conference of the Cognitive Science Society, Seattle, WA, pages 165-176, 1987.
[NGU89]
D. Nguyen and B. Widrow; The truck backer-upper: An example of self learning in neural networks. In IEEE/INNS International Joint Conference on Neural Networks, Washington, D.C., volume 1, pages 357-364, 1989.
[OBJ1] K. Greff, A. Rasmus, M. Berglund, T. Hao, H. Valpola, J. Schmidhuber (2016). Tagger: Deep unsupervised perceptual grouping. NIPS 2016, pp. 4484-4492.
Preprint arXiv/1606.06724.
[OBJ2] K. Greff, S. van Steenkiste, J. Schmidhuber (2017). Neural expectation maximization. NIPS 2017, pp. 6691-6701.
Preprint arXiv/1708.03498.
[OBJ3] S. van Steenkiste, M. Chang, K. Greff, J. Schmidhuber (2018). Relational neural expectation maximization: Unsupervised discovery of objects and their interactions. ICLR 2018.
Preprint arXiv/1802.10353.
[OBJ4]
A. Stanic, S. van Steenkiste, J. Schmidhuber (2021). Hierarchical Relational Inference. AAAI 2021.
Preprint arXiv/2010.03635.
[OBJ5]
A. Gopalakrishnan, S. van Steenkiste, J. Schmidhuber (2020). Unsupervised Object Keypoint Learning using Local Spatial Predictability.
Preprint arXiv/2011.12930.
[OOPS1]
J. Schmidhuber. Bias-Optimal Incremental Problem Solving.
In S. Becker, S. Thrun, K. Obermayer, eds.,
Advances in Neural Information Processing Systems 15, N(eur)IPS'15, MIT Press, Cambridge MA, p. 1571-1578, 2003.
PDF
[OOPS2]
J. Schmidhuber.
Optimal Ordered Problem Solver.
Machine Learning, 54, 211-254, 2004.
PDF.
HTML.
HTML overview.
Download
OOPS source code in crystalline format.
[OOPS3]
Schmidhuber, J., Zhumatiy, V. and Gagliolo, M. Bias-Optimal
Incremental Learning of Control Sequences for Virtual Robots. In Groen,
F., Amato, N., Bonarini, A., Yoshida, E., and Kroese, B., editors:
Proceedings of the 8-th conference
on Intelligent Autonomous Systems, IAS-8, Amsterdam,
The Netherlands, pp. 658-665, 2004.
PDF.
[PDA1]
G.Z. Sun, H.H. Chen, C.L. Giles, Y.C. Lee, D. Chen. Neural Networks with External Memory Stack that Learn Context - Free Grammars from Examples. Proceedings of the 1990 Conference on Information Science and Systems, Vol.II, pp. 649-653, Princeton University, Princeton, NJ, 1990.
[PDA2]
M. Mozer, S. Das. A connectionist symbol manipulator that discovers the structure of context-free languages. Proc. N(eur)IPS 1993.
[DNC] Hybrid computing using a neural network with dynamic external memory.
A. Graves, G. Wayne, M. Reynolds, T. Harley, I. Danihelka, A. Grabska-Barwinska, S. G. Colmenarejo, E. Grefenstette, T. Ramalho, J. Agapiou, A. P. Badia, K. M. Hermann, Y. Zwols, G. Ostrovski, A. Cain, H. King, C. Summerfield, P. Blunsom, K. Kavukcuoglu, D. Hassabis.
Nature, 538:7626, p 471, 2016.
[PBVF]
F. Faccio, L. Kirsch, J. Schmidhuber.
Parameter-based value functions.
Preprint arXiv/2006.09226, 2020.
[PEVN]
Policy Evaluation Networks.
J. Harb, T. Schaul, D. Precup, P. Bacon.
Preprint arXiv/2002.11833, 2020.
[PLAN]
J. Schmidhuber (AI Blog, 2020). 30-year anniversary of planning & reinforcement learning with recurrent world models and artificial curiosity (1990). This work also introduced high-dimensional reward signals, deterministic policy gradients for RNNs,
the GAN principle (widely used today). Agents with adaptive recurrent world models even suggest a simple explanation of consciousness & self-awareness.
[PLAN2]
J. Schmidhuber.
An on-line algorithm for dynamic reinforcement learning and planning
in reactive environments.
In Proc. IEEE/INNS International Joint Conference on Neural
Networks, San Diego, volume 2, pages 253-258, June 17-21, 1990.
Based on [AC90].
[PLAN3]
J. Schmidhuber.
Reinforcement learning in Markovian and non-Markovian environments.
In D. S. Lippman, J. E. Moody, and D. S. Touretzky, editors,
Advances in Neural Information Processing Systems 3, NIPS'3, pages 500-506. San
Mateo, CA: Morgan Kaufmann, 1991.
PDF.
Partially based on [AC90].
[PLAN4]
J. Schmidhuber.
On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models.
Report arXiv:1210.0118 [cs.AI], 2015.
[PLAN5]
One Big Net For Everything. Preprint arXiv:1802.08864 [cs.AI], Feb 2018.
[PLAN6]
D. Ha, J. Schmidhuber. Recurrent World Models Facilitate Policy Evolution. Advances in Neural Information Processing Systems (NIPS), Montreal, 2018. (Talk.)
Preprint: arXiv:1809.01999.
Github: World Models.
[PHD]
J. Schmidhuber.
Dynamische neuronale Netze und das fundamentale raumzeitliche
Lernproblem
(Dynamic neural nets and the fundamental spatio-temporal
credit assignment problem).
Dissertation,
Institut für Informatik, Technische
Universität München, 1990.
PDF.
HTML.
[PM0] J. Schmidhuber. Learning factorial codes by predictability minimization. TR CU-CS-565-91, Univ. Colorado at Boulder, 1991. PDF.
More.
[PM1] J. Schmidhuber. Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879, 1992. Based on [PM0], 1991. PDF.
More.
[PM2] J. Schmidhuber, M. Eldracher, B. Foltin. Semilinear predictability minimzation produces well-known feature detectors. Neural Computation, 8(4):773-786, 1996.
PDF. More.
[PMax0]
J. Schmidhuber and D. Prelinger. Discovering predictable classifications. Technical Report CU-CS-626-92, Dept. of Comp. Sci., University of Colorado at Boulder, November 1992.
[PMax]
J. Schmidhuber and D. Prelinger.
Discovering
predictable classifications.
Neural Computation, 5(4):625-635, 1993.
PDF.
[R2] Reddit/ML, 2019. J. Schmidhuber really had GANs in 1990.
[RPG]
D. Wierstra, A. Foerster, J. Peters, J. Schmidhuber (2010). Recurrent policy gradients. Logic Journal of the IGPL, 18(5), 620-634.
[RPG07]
D. Wierstra, A. Foerster, J. Peters, J. Schmidhuber. Solving Deep Memory POMDPs
with Recurrent Policy Gradients.
Intl. Conf. on Artificial Neural Networks ICANN'07,
2007.
PDF.
[PP] J. Schmidhuber.
POWERPLAY: Training an Increasingly General Problem Solver by Continually Searching for the Simplest Still Unsolvable Problem.
Frontiers in Cognitive Science, 2013.
ArXiv preprint (2011):
arXiv:1112.5309 [cs.AI]
[PPa]
R. K. Srivastava, B. R. Steunebrink, M. Stollenga, J. Schmidhuber.
Continually Adding Self-Invented
Problems to the Repertoire: First
Experiments with POWERPLAY.
Proc. IEEE Conference on Development and Learning / EpiRob 2012
(ICDL-EpiRob'12), San Diego, 2012.
PDF.
[PP1] R. K. Srivastava, B. Steunebrink, J. Schmidhuber.
First Experiments with PowerPlay.
Neural Networks, 2013.
ArXiv preprint (2012):
arXiv:1210.8385 [cs.AI].
[PP2] V. Kompella, M. Stollenga, M. Luciw, J. Schmidhuber. Continual curiosity-driven skill acquisition from high-dimensional video inputs for humanoid robots. Artificial Intelligence, 2015.
[SNT]
J. Schmidhuber, S. Heil (1996).
Sequential neural text compression.
IEEE Trans. Neural Networks, 1996.
PDF.
A probabilistic language model based on predictive coding;
an earlier version appeared at NIPS 1995.
[SYM1]
P. Smolensky (1988). On the proper treatment of connectionism. Behavioral and Brain Sciences, 11(1), 1-23. doi:10.1017/S0140525X00052432
[SYM2]
Mozer, M. C. (1990). The perception of multiple objects: A connectionist approach. Cambridge, MA: MIT Press.
[SYM3]
C. McMillan, M. C. Mozer, P. Smolensky. Rule induction through integrated symbolic and subsymbolic processing. Advances in Neural Information Processing Systems 4 (1991).
[SWA22]
J. Swan, E. Nivel, N. Kant, J. Hedges, T. Atkinson, B. Steunebrink (2022).
Work on Command: The Case for Generality. In: The Road to General Intelligence. Studies in Computational Intelligence, vol 1049. Springer, Cham. https://doi.org/10.1007/978-3-031-08020-3_6.
[T22] J. Schmidhuber (AI Blog, 2022).
Scientific Integrity and the History of Deep Learning: The 2021 Turing Lecture, and the 2018 Turing Award. Technical Report IDSIA-77-21 (v3), IDSIA, Lugano, Switzerland, 2021-2022.
[TR1]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin (2017). Attention is all you need. NIPS 2017, pp. 5998-6008.
[TR2]
J. Devlin, M. W. Chang, K. Lee, K. Toutanova (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. Preprint arXiv:1810.04805.
[TR3] K. Tran, A. Bisazza, C. Monz. The Importance of Being Recurrent for Modeling Hierarchical Structure. EMNLP 2018, p 4731-4736. ArXiv preprint 1803.03585.
[TR4]
M. Hahn. Theoretical Limitations of Self-Attention in Neural Sequence Models. Transactions of the Association for Computational Linguistics, Volume 8, p.156-171, 2020.
[TR5]
A. Katharopoulos, A. Vyas, N. Pappas, F. Fleuret.
Transformers are RNNs: Fast autoregressive Transformers
with linear attention. In Proc. Int. Conf. on Machine
Learning (ICML), July 2020.
[TR6]
K. Choromanski, V. Likhosherstov, D. Dohan, X. Song,
A. Gane, T. Sarlos, P. Hawkins, J. Davis, A. Mohiuddin,
L. Kaiser, et al. Rethinking attention with Performers.
In Int. Conf. on Learning Representations (ICLR), 2021.
[UDRL1]
J. Schmidhuber.
Reinforcement Learning Upside Down: Don't Predict Rewards—Just Map Them to Actions.
Preprint arXiv/1912.02875, 5 Dec 2019.
[UDRL2]
R. K. Srivastava, P. Shyam, F. Mutz, W. Jaskowski, J. Schmidhuber.
Training Agents using Upside-Down Reinforcement Learning.
Preprint arXiv/1912.02877, 5 Dec 2019.
[UN]
J. Schmidhuber (AI Blog, 2021). 30-year anniversary. 1991: First very deep learning with unsupervised pre-training. Unsupervised hierarchical predictive coding finds compact internal representations of sequential data to facilitate downstream learning. The hierarchy can be distilled into a single deep neural network (suggesting a simple model of conscious and subconscious information processing). 1993: solving problems of depth >1000.
[UN0]
J. Schmidhuber.
Neural sequence chunkers.
Technical Report FKI-148-91, Institut für Informatik, Technische
Universität München, April 1991.
PDF.
[UN1] J. Schmidhuber. Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242, 1992. Based on TR FKI-148-91, TUM, 1991.[UN0] PDF.
First working Deep Learner based on a deep RNN hierarchy (with different self-organising time scales),
overcoming the vanishing gradient problem through unsupervised pre-training and predictive coding.
Also: compressing or distilling a teacher net (the chunker) into a student net (the automatizer) that does not forget its old skills—such approaches are now widely used. More.
[UN2] J. Schmidhuber. Habilitation thesis, TUM, 1993. PDF.
An ancient experiment on "Very Deep Learning" with credit assignment across 1200 time steps or virtual layers and unsupervised pre-training for a stack of recurrent NN
can be found here (depth > 1000).
[UN3]
J. Schmidhuber, M. C. Mozer, and D. Prelinger.
Continuous history compression.
In H. Hüning, S. Neuhauser, M. Raus, and W. Ritschel, editors,
Proc. of Intl. Workshop on Neural Networks, RWTH Aachen, pages 87-95.
Augustinus, 1993.
[UNI]
Theory of Universal Learning Machines & Universal AI.
Work of Marcus Hutter (in the early 2000s) on J.
Schmidhuber's SNF project 20-61847:
Unification of universal induction and sequential decision theory.
[WER87]
P. J. Werbos. Building and understanding adaptive systems: A statistical/numerical approach to factory automation and brain research. IEEE Transactions on Systems, Man, and Cybernetics, 17, 1987.
[WER89]
P. J. Werbos. Backpropagation and neurocontrol: A review and prospectus. In IEEE/INNS International Joint Conference on Neural Networks, Washington, D.C., volume 1, pages 209-216, 1989.
.

