Viele Lernverfahren (u. a. auch die Weltmodellbauer aus Kapitel 4) basieren auf Untermodulen, die gewisse Muster aus anderen Mustern vorhersagen sollen. Häufig sind perfekte Vorhersagen jedoch prinzipiell unmöglich.
Informationstragende Musterklassifikationen hingegen mögen sehr wohl prophezeihbar sein. Unüberwachte Extraktion vorhersagbarer Konzepte (im folgenden auch Vorhersagbarkeitsmaximierung genannt - ein weiterer größerer originärer Beitrag dieser Arbeit, siehe auch [121] ) beschäftigt sich mit dem Problem, möglichst spezifische vorhersagbare Musterklassifikationen zu finden.
Die folgenden vier Beispiele sollen dies näher erläutern.
Beispiel 1: Man gehe in den Tierpark, um sich den Elefanten anzuschauen. Es ist unmöglich, von vornherein alle Details wie z.B. seinen genauen Aufenthaltsort, sein exaktes Gewicht und die Schattierung seiner Hautfarbe vorherzusagen. Man kann sich jedoch darauf verlassen, daß sich der Elefant auf dem Boden befinden wird (statt in der Luft zu schweben) und daß er eher grau als pinkfarben sein wird. Eine nützliche Klassifikation wird die von beliebigen Elefanten verursachten Eingaben auf eine einzige vorhersagbare interne Repräsentation abbilden, die sich von der internen Repräsentation beliebiger Nilpferde unterscheidet (und damit informationstragend ist5.3).
Beispiel 2: Man werfe einen Spielwürfel. Die Fläche, auf der er zu liegen kommen wird, läßt sich gewöhnlich nicht vorhersagen - wohl aber die Tatsache, daß der Würfel, nachdem er zur Ruhe gekommen ist, nicht in der Luft hängen wird oder auf einer Ecke balancieren wird. Das Resultat einer Abbildung, die alle zur Ruhe gekommene Würfel auf dieselbe Klassenrepräsentation abbildet, ist vorhersagbar. Es sollte sich unterscheiden von vorhersagbaren Repräsentanten von, sagen wir, zur Ruhe gekommenen Kugelschreibern.
Beispiel 3: Sind die ersten beiden Wörter des Satzes `Henrietta ißt Gemüse' bekannt, so läßt sich vorhersagen, daß das dritte Wort wohl für etwas Eßbares stehen wird, nicht aber, für welches Nahrungsmittel. Die Klasse des dritten Wortes ist aus den beiden vorangegangenen Wörtern prophezeihbar - die spezielle Instanz der Klasse ist es nicht. Die Klasse `Eßbares' ist nicht nur vorhersagbar, sondern auch spezifisch in dem Sinne, daß sie nicht alles mögliche umfaßt - `Ferdinand' ist beispielsweise keine Instanz von `Eßbares'.
Das Problem besteht darin, Muster so zu klassifizieren, daß sie sowohl vorhersagbar als auch nicht zu allgemein sind, um solcherart in der Umgebung verborgene Regelmäßigkeiten zu extrahieren. Eine allgemeine Lösung für dieses Problem wäre beispielsweise nützlich für die Entdeckung von Struktur in von unbekannten Grammatiken generierten Sätzen (wie im letzten Beispiel). Eine weitere wichtige Anwendung wäre die unüberwachte Klassifizierung von zur gleichen Klasse gehörigen Mustern, wie im folgenden erläutert werden soll.
Gegeben sei eine Menge von Paaren von Eingabemustern. Wir wissen, daß beide Muster eines Paares zur selben Klasse gehören. Wir wissen jedoch nichts über die Klassen selbst, wieviele Klassen es gibt, oder welche Muster zu welcher Klasse gehören. Das Ziel sei die Erstellung einer Abbildung von Eingabemustern auf Klassenrepräsentanten dergestalt, daß Muster, die zur selben Klasse gehören, auf gleiche Weise repräsentiert werden, während Muster, die zu verschiedenen Klassen gehören, auf unterschiedliche Weise repräsentiert werden. Wir wollen den Sinn dieses Ziels an einem weiteren praktischen Beispiel verdeutlichen:
Beispiel 4 (Stereoproblem, nach Becker und Hinton, 1989): Becker und Hinton beschreiben eine `Stereoaufgabe', bei der es darum geht, aus zwei getrennten Pixelfeldern Stereoinformation zu extrahieren [11]. Eines der Pixelfelder wird mit einem zufällig generierten Bild belegt, während das andere Pixelfeld dasselbe Bild in um ein Pixel nach links oder rechts verschobener Position darstellt (siehe Abbildung 5.2). Pixel, die über den rechten Rand des Eingabefeldes hinausgeschoben werden, erscheinen auf der linken Seite des Feldes wieder (und umgekehrt). Zweideutige `shifts' werden ausgeschlossen. 8-dimensionale Eingabemuster werden durch Konkatenation eines 4-dimensionalen Streifens des linken Bildes mit dem entsprechenden 4-dimensionalen Streifens des rechten Bildes generiert. Betrachten wir nun Paare solcherart konstruierter, nicht überlappender Eingabemuster. Kennt man das erste Muster eines Paars, so kann man eine nicht-triviale Aussage über das zweite Muster machen (und umgekehrt), denn beiden Mustern ist etwas gemeinsam, nämlich die Information über die `stereoskopische Tiefe'. Diese ist gleichzeitig die einzige nicht-triviale Eigenschaft, die beiden Eingaben zu eigen ist. Das Ziel besteht darin, ohne irgendetwas über das Konzept `stereoskopische Tiefe' erzählt zu bekommen, diese einzige nicht-triviale wechselseitig vorhersagbare Eigenschaft zu finden und Eingabemuster mit gleicher stereoskopischer Tiefe auf dieselbe Klasse abzubilden, während Eingabemuster mit unterschiedlicher stereoskopischer Tiefe auf unterschiedliche Klassen abzubilden sind.
Die Beispiele ![]() sind Vertreter des sogenannten asymmetrischen
Falles, während Beispiel 4 eine Instanz des
sogenannten symmetrischen Falles darstellt.
Welche Architekturen und Zielfunktionen eignen sich nun
zum Finden möglichst informativer und doch gleichzeitig
vorhersagbarer Eingabetransformationen?
sind Vertreter des sogenannten asymmetrischen
Falles, während Beispiel 4 eine Instanz des
sogenannten symmetrischen Falles darstellt.
Welche Architekturen und Zielfunktionen eignen sich nun
zum Finden möglichst informativer und doch gleichzeitig
vorhersagbarer Eingabetransformationen?
Im einfachsten Fall basiert der hier vorgeschlagene Ansatz zur
unüberwachten Extraktion vorhersagbarer Klassifikationen
auf zwei neuronalen Netzwerken
![]() und
und ![]() .
Beide lassen sich als BP-Netze implementieren
[143][46][66][85]
(siehe auch Kapitel 1).
.
Beide lassen sich als BP-Netze implementieren
[143][46][66][85]
(siehe auch Kapitel 1).
![]() sieht bei einem gegebenen Paar von Eingabemustern das erste Muster,
sieht bei einem gegebenen Paar von Eingabemustern das erste Muster,
![]() sieht das zweite Muster.
Konzentrieren wir uns zunächst auf den asymmetrischen Fall:
Im Falle des Beispiels 3 sieht
sieht das zweite Muster.
Konzentrieren wir uns zunächst auf den asymmetrischen Fall:
Im Falle des Beispiels 3 sieht ![]() beispielsweise eine Repräsentation
der Wörter `Henrietta ißt', während
beispielsweise eine Repräsentation
der Wörter `Henrietta ißt', während
![]() eine Repräsentation des Wortes
`Gemüse' als Eingabe bekommt.
eine Repräsentation des Wortes
`Gemüse' als Eingabe bekommt.
![]() 's Aufgabe besteht darin, seine Eingabe zu klassifizieren.
's Aufgabe besteht darin, seine Eingabe zu klassifizieren.
![]() 's Aufgabe besteht nicht etwa darin,
's Aufgabe besteht nicht etwa darin,
![]() 's rohe Eingabe zu prophezeihen, sondern statt dessen
's rohe Eingabe zu prophezeihen, sondern statt dessen
![]() 's Ausgabe.
's Ausgabe.
Beide Netze besitzen ![]() Ausgabeknoten.
Ausgabeknoten.
![]() indiziere die Trainingsmuster.
indiziere die Trainingsmuster.
![]() beantwortet einen Eingabevektor
beantwortet einen Eingabevektor
![]() durch die
Klassifikation
durch die
Klassifikation
![]() .
.
![]() beantwortet einen Eingabevektor
beantwortet einen Eingabevektor
![]() durch die
Vorhersage
durch die
Vorhersage
![]() der Klassifikation
der Klassifikation
![]() .
.
Wir sehen uns zwei miteinander im Konflikt stehenden Zielen
gegenüber:
(A) Alle Vorhersagen ![]() sollen
den entsprechenden Klassifikationen
sollen
den entsprechenden Klassifikationen ![]() gleichkommen.
(B) Die
gleichkommen.
(B) Die ![]() sollen diskriminierend sein -
verschiedene Eingaben
sollen diskriminierend sein -
verschiedene Eingaben ![]() sollen verschiedene Klassifikationen
sollen verschiedene Klassifikationen
![]() nach sich ziehen.
nach sich ziehen.
Wir drücken den Konflikt zwischen (A) und (B) durch zwei gegensätzliche Zielfunktionen aus, welche gleichzeitig minimiert werden sollen.
(A) wird durch einen Fehlerterm ![]() (für `Match') ausgedrückt:
(für `Match') ausgedrückt:
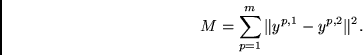 |
(5.12) |
(B) wird durch einen zusätzlichen Fehlerterm
![]() (für `Diskriminierung') repräsentiert,
welchen (im asymmetrischen Fall) nur
(für `Diskriminierung') repräsentiert,
welchen (im asymmetrischen Fall) nur ![]() zu minimieren braucht.
Im nächsten Unterabschnitt werden
wir
zu minimieren braucht.
Im nächsten Unterabschnitt werden
wir ![]() so wählen, daß signifikante
Euklidische Abstände zwischen Klassifikationen unterschiedlicher
Eingabemuster ermutigt werden.
Es gibt mehr als einen vernünftigen Weg,
so wählen, daß signifikante
Euklidische Abstände zwischen Klassifikationen unterschiedlicher
Eingabemuster ermutigt werden.
Es gibt mehr als einen vernünftigen Weg,
![]() zu definieren -
der nächste Unterabschnitt
wird vier alternative Möglichkeiten mit verschiedenen
Vor- und Nachteilen erwähnen.
zu definieren -
der nächste Unterabschnitt
wird vier alternative Möglichkeiten mit verschiedenen
Vor- und Nachteilen erwähnen.
![]() 's zu minimierende Zielfunktion ist
's zu minimierende Zielfunktion ist
| (5.13) |
Im asymmetrischen Fall
ist ![]() 's zu minimierende Zielfunktion
's zu minimierende Zielfunktion
| (5.14) |
Die Zielfunktionen werden wie üblich
durch Gradientenabstieg minimiert.
Dies zwingt einerseits die Klassifikationen, sich den Vorhersagen
anzugleichen,
und andererseits in symmetrischer Weise die Vorhersagen,
sich den Klassifikationen anzugleichen, während die Klassifikationen
gleichzeitig ermutigt werden, möglichst aussagekräftig zu sein.
Abbildung 5.1 zeigt ein entsprechendes aus einem Prediktor und einem
Klassifikator bestehendes System, welches sich zur Implementierung
von ![]() eines Autoassoziators bedient (siehe auch den folgenden
Unterabschnitt 5.5.1).
eines Autoassoziators bedient (siehe auch den folgenden
Unterabschnitt 5.5.1).
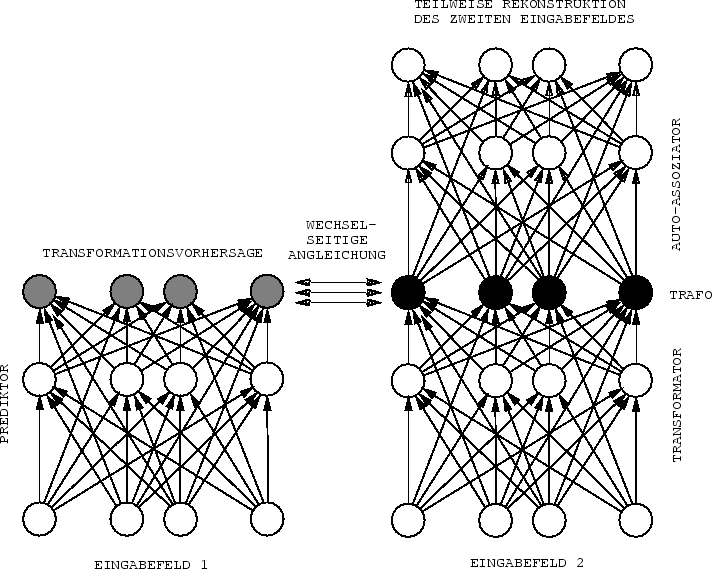 |
Gelegentlich (siehe das Stereoexperiment aus Beiapiel 4) ist es angebracht,
![]() und
und ![]() in
symmetrischer Manier zu behandeln. In solchen Fällen
dienen beide
Netzwerke als Klassifikatoren.
Jeder der beiden Klassifikatoren `sieht' ein Eingabemuster eines Paars.
Die Klassifikatoren sollen ohne Lehrer lernen,
die nicht-trivialen wechselseitig vorhersagbaren
Eigenschaften in ihren Ausgaben
zu repräsentieren.
Um solchen
symmetrischen Problemen in natürlicher Weise zu begegnen,
brauchen wir
in
symmetrischer Manier zu behandeln. In solchen Fällen
dienen beide
Netzwerke als Klassifikatoren.
Jeder der beiden Klassifikatoren `sieht' ein Eingabemuster eines Paars.
Die Klassifikatoren sollen ohne Lehrer lernen,
die nicht-trivialen wechselseitig vorhersagbaren
Eigenschaften in ihren Ausgaben
zu repräsentieren.
Um solchen
symmetrischen Problemen in natürlicher Weise zu begegnen,
brauchen wir
![]() 's Zielfunktion nur leicht durch Einführung
eines zusätzlichen `Diskriminationsterm'
's Zielfunktion nur leicht durch Einführung
eines zusätzlichen `Diskriminationsterm' ![]() für
für ![]() zu modifizieren: Beide
zu modifizieren: Beide
![]() minimieren5.4nun
minimieren5.4nun
| (5.15) |
Gewichtsteilung. Sollen beide Klassifikatoren gleiche Eingaben mit gleichen Ausgaben beantworten (dies gilt z. B. für obige Stereoaufgabe), so läßt sich das Verfahren weiter vereinfachen. Dann genügt es nämlich, für beide Klassifikatoren dieselben Gewichtsparameter zu verwenden - dies reduziert die Anzahl der freien Parameter und erhöht demzufolge die Generalisierungsperformanz [10].