



Nächste Seite: STEREO-EXPERIMENT
Aufwärts: EXPERIMENTE ZUR VORHERSAGBARKEITSMAXIMIERUNG
Vorherige Seite: VORHERSAGBARE LOKALE KLASSENREPRÄSENTANTEN
Inhalt
Wir verwenden wieder Aufgabe 2 aus dem letzten
Unterabschnitt. Da bei distribuierter binärer
Repräsentation der 4 möglichen wechselseitig
vorhersagbaren Eigenschaftskombinationen im Gegensatz
zu lokaler Repräsentation nur 2 Ausgabevariablen
vonnöten sind,
besaßen 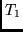 und
und 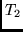 bei diesem Experiment
nur noch 2 (statt 4) Ausgabeknoten sowie
4 versteckte Knoten.
bei diesem Experiment
nur noch 2 (statt 4) Ausgabeknoten sowie
4 versteckte Knoten.
Trainingsiterationen wurden abgewickelt
wie im vorherigen Abschnitt beschrieben.
10 Testläufe
mit 15,000 Musterpräsentationen und
Vorhersagbarkeitsmaximierung
gemäß (5.15)
wurden durchgeführt.
Dabei war
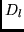 durch einen Autoassoziator definiert (5.16),
durch einen Autoassoziator definiert (5.16),
 besaß 4 versteckte Knoten,
besaß 4 versteckte Knoten,
 war gleich
war gleich 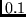 , und
alle Lernraten waren gleich 0.5.
Das System fand stets eine distribuierte, nahezu binäre
Repräsentation der
4 möglichen vorhersagbaren Eigenschaftskombinationen.
, und
alle Lernraten waren gleich 0.5.
Das System fand stets eine distribuierte, nahezu binäre
Repräsentation der
4 möglichen vorhersagbaren Eigenschaftskombinationen.
Das gleiche Experiment wurde mit vergleichbarem Erfolg
durchgeführt, wobei jedoch durch
Vorhersagbarkeitsminimierung (Abschnitt 5.5.1, siehe auch
das nächste Kapitel)
statt durch einen Autoassoziator
definiert war.
Juergen Schmidhuber
2003-02-20
Related links in English: Recurrent networks - Fast weights - Subgoal learning - Reinforcement learning and POMDPs - Unsupervised learning and ICA - Metalearning and learning to learn
Deutsche Heimseite