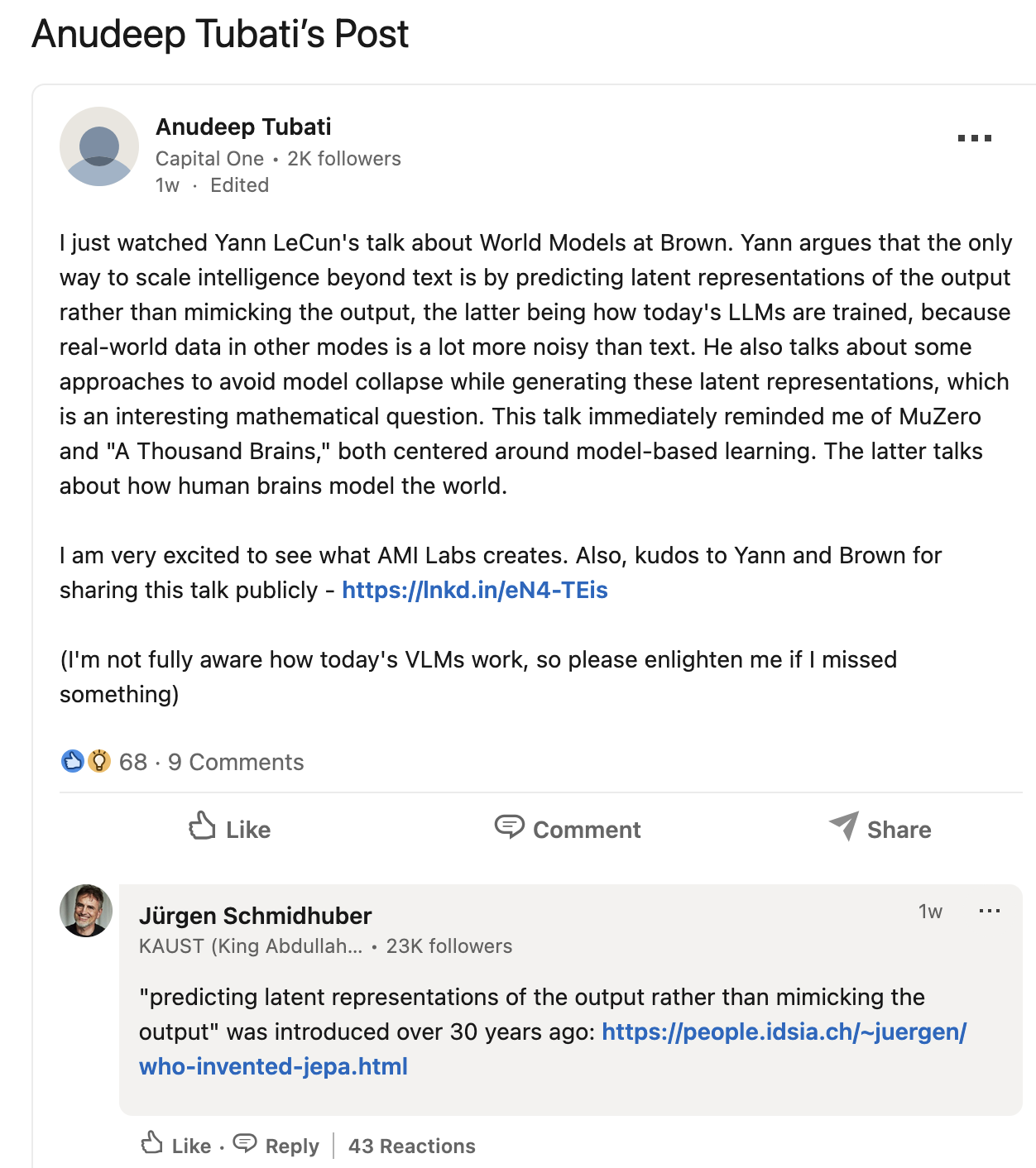
Dr. LeCun's heavily promoted Joint Embedding Predictive Architecture (JEPA, 2022) [LEC22a][LEC][DLP] is the heart of his new company [AMI1-2]. However, the core ideas are not original to LeCun. Instead, JEPA is essentially identical to our 1992 Predictability Maximization system [PMAX][UN2].
Since details of inputs are often unpredictable from related inputs, two non-generative
artificial neural networks interact as follows: one net tries to create a non-trivial, informative, latent representation of its own input that is predictable from the latent representation of the other net’s input.
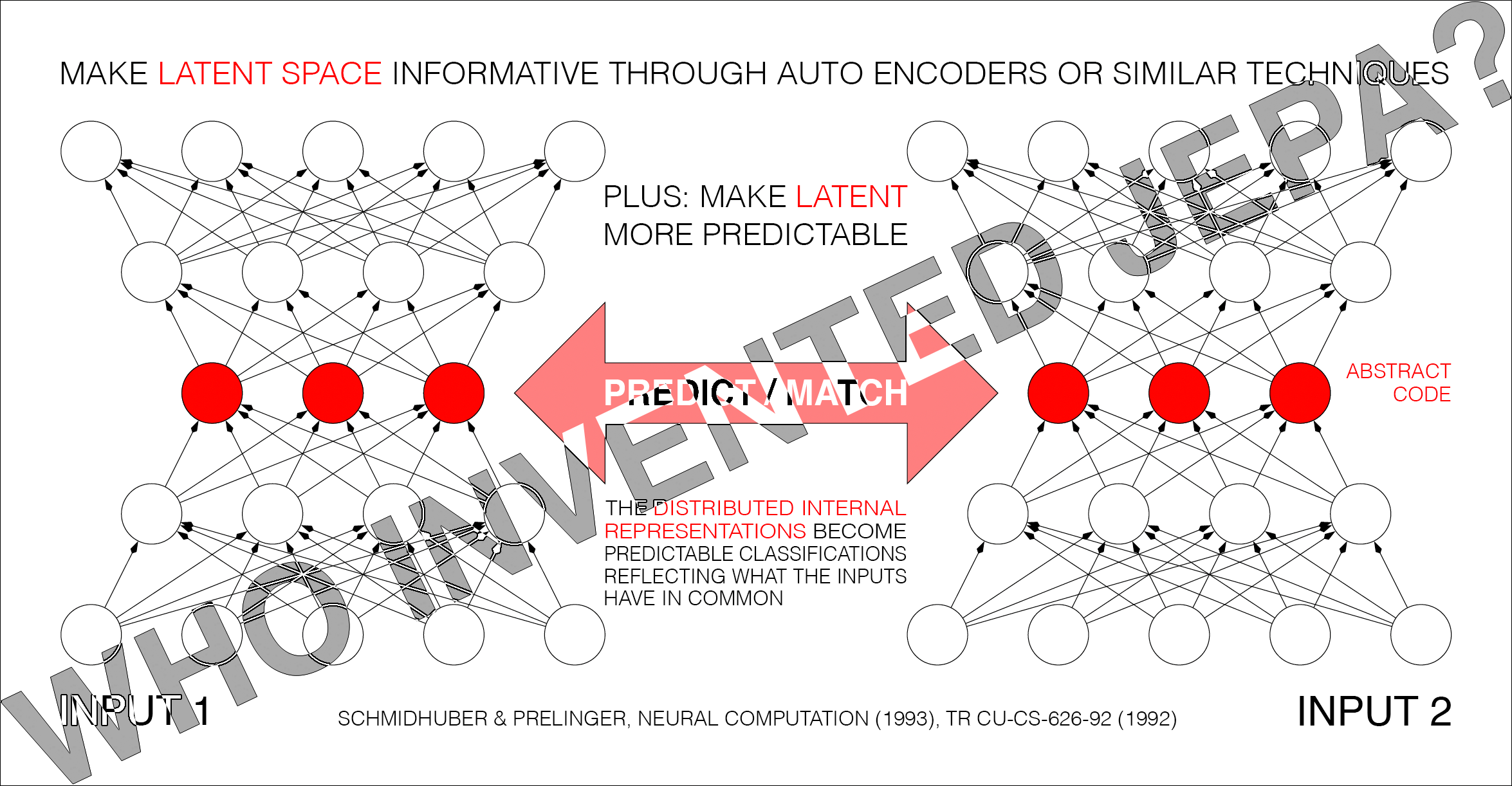
Predictability Maximization [PMAX][UN2] is actually a whole family of methods. Consider the simplest instance in Sec. 2.2 of [PMAX]: an auto encoder net sees an input and represents it in its hidden units (its latent space). The other net sees a different but related input and learns to predict (from its own latent space) the auto encoder's latent representation, which in turn tries to become more predictable, without giving up too much information about its own input, to prevent what's now called "collapse." See illustration 5.2 in [UN2]'s Sec. 5.5 on the "extraction of predictable concepts."
The 1992 [PMAX] paper discusses not only auto encoders but also other techniques for encoding data, e.g., maximizing constrained variance of the code (Sec. 2.1), Infomax (Sec. 2.3), and Predictability MINimization [PM1-2] (PMIN, see the footnotes). The experiments were conducted by my student Daniel Prelinger. The non-generative PMAX outperformed [IMAX] on a stereo vision task.
The 2020 [BYOL] is also closely related to PMAX. In 2026, Michal Valko, leader of the BYOL team, praised PMAX, and listed numerous similarities to much later work [VAL26].
Note that the self-created predictable classifications in the title of [PMAX] (and the so-called “outputs” of the entire system [PMAX]) are typically internal "distributed representations” (like in the title of Sec. 4.2 of [PMAX]).
Note also that the predictor can be absorbed into the encoder (see 2nd paragraph of Sec. 3 of [PMAX]).
The 1992 [PMAX] paper considers both symmetric and asymmetric nets. In the symmetric case, both nets are constrained to emit "equal (and therefore mutually predictable)" representations [PMAX]. Sec. 4.2 on "finding predictable distributed representations" has an experiment with 2 weight-sharing auto encoders which learn to represent in their latent space what their inputs have in common (see the cover image of the present note).
Of course, back then compute was was a million times more expensive [RAW], but the fundamental insights of "JEPA" were present, and LeCun has simply repackaged old ideas without citing them [LEC22a][LEC][DLP][FAKE1-3][WHO12].
This is hardly the first time LeCun (or others writing about him) have exaggerated LeCun's own significance by downplaying earlier work. He did not "co-invent deep learning" (as some know-nothing "AI influencers" have claimed) [WHO5][DLH], and he did not invent convolutional neural nets (CNNs) [WHO7][DLH], nor was he even the first to combine CNNs with backpropagation [WHO7]. While
he got awards for the inventions of other researchers whom he did not cite [DLP], he did not invent any of the key algorithms that underpin modern AI. See also tweets [LE1-9].
LeCun's recent pitch: 1. LLMs such as ChatGPT are insufficient for AGI (which has been obvious to experts in AI & decision making [WM26], and is something he once derided Gary Marcus for pointing out [MAR24]). 2. Neural AIs need what I baptized a neural world model in 1990 [GAN90][WM26] (earlier, less general neural nets of this kind [WER87-89][MUN87][NGU89] weren't called "world models," although the basic concept itself is ancient [WM26][PLA1][ARI1][CRA67]). 3. The world model should learn to predict (in non-generative "JEPA" fashion [LEC22a][LEC]) higher-level predictable abstractions instead of raw pixels: that's the essence of our 1992 PMAX [PMAX][UN2].
Astonishingly, PMAX or "JEPA" seems to be the unique selling proposition of LeCun's 2025 company called "AMI" [AMI1-2] which is apparently based on what we published over 3 decades ago [PMAX][LEC][DLP][DLH][UN2][WM26][WM26b], and modeled after our own 2014 company [NAI] on world model-based AGI in the physical world [LE7].
In short, little if anything in JEPA is new [WHO12]. But then the fact that LeCun would repackage old ideas and present them as his own clearly isn't new either [MAR25][DLP].
Footnotes
1.
Note that [PMAX] is not our 1991 adversarial PMIN [PM1-2]. However, PMAX may use PMIN as a submodule to create informative latent representations [PMAX] (Sec. 2.4), and to prevent what's now called "collapse." See the illustration on page 9 of [PMAX].
2.
Note that the 1991 PMIN [PM1-2] also predicts parts of latent space from other parts. However, PMIN's goal is to remove mutual predictability, to obtain maximally disentangled latent representations called factorial codes. PMIN by itself may use the auto encoder principle in addition to its latent space predictor [PM1].
3.
Neither PMAX nor PMIN was my first non-generative method for predicting latent space, which was published in 1991 in the context of neural network distillation [UN0-1][WHO9][MIR][MOST][WM26][DLP][DLH].
4.
Disclaimer: while the cognoscenti agree that LLMs are insufficient for AGI, JEPA is so, too. We should know: we have had it for over 3 decades under the name PMAX! Additional techniques are required to achieve AGI, e.g., meta learning [META1][META], artificial curiosity and creativity [AC09][AC],
efficient planning with world models [PLAN1-6][WM26],
and others [DLH][AIB].
Addendum I (4/27/2026): LeCun's response and my reply
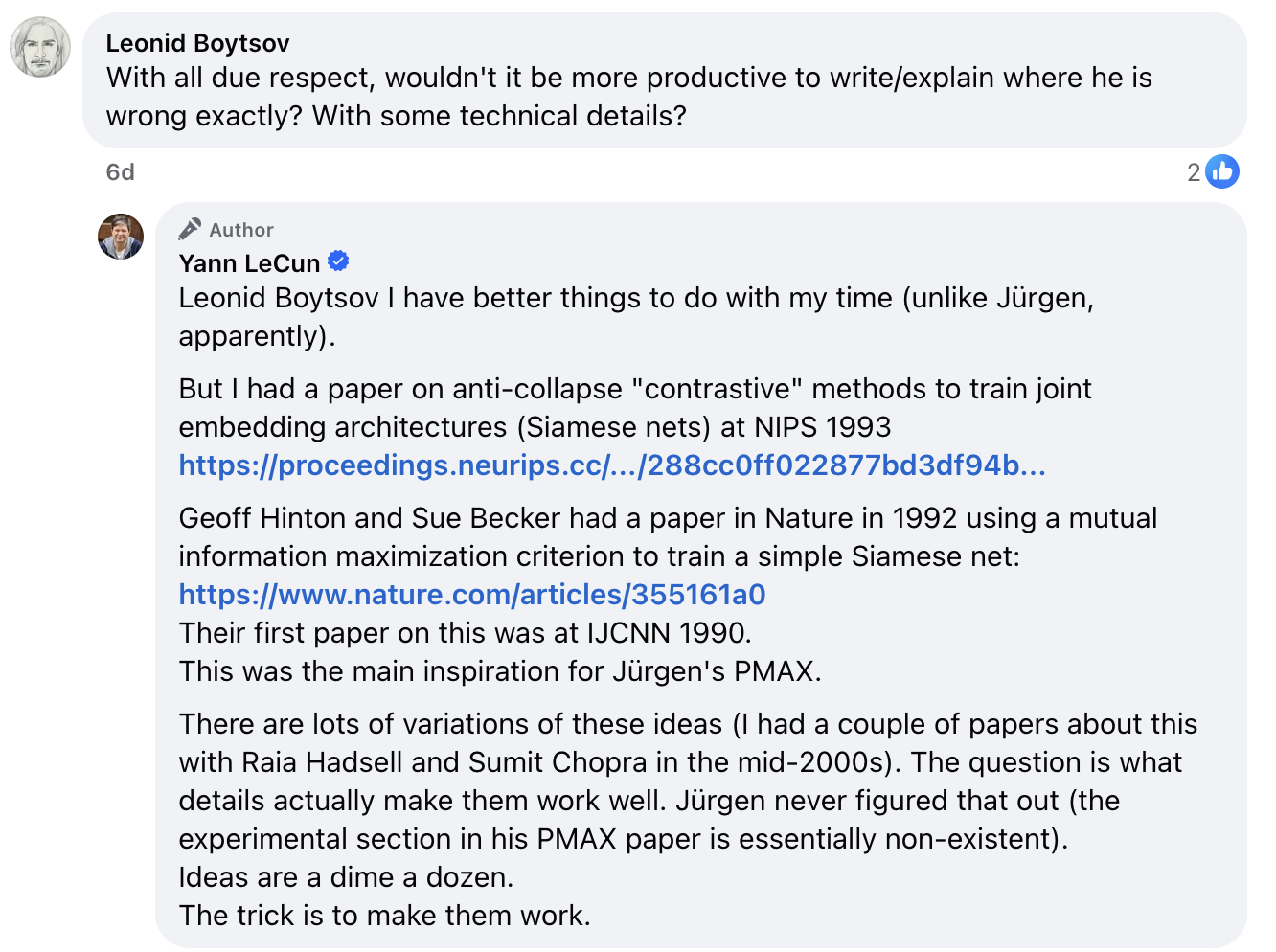
On 6 April 2026, Dr. LeCun replied at LinkedIn (see screenshots 1, 2, 3): "what we now called Joint Embedding Architectures, which include things like Siamese nets and JEPA was introduced decades ago. No one is claiming it's new. You didn't invent it either. A good example of early work is the Becker & Hinton 1989 technique for maximizing mutual information. It worked, but made strong hypotheses about the distribution and probably didn´t scale (I was a postdoc in Toronto when they were thinking about this). This paper is the inspiration for your PMAX paper. Lot's of people have used mutual information maximization to train neural nets. The concept goes back to Horace Barlow. The question is *precisely* how to measure mutual information and how to maximize it. It's difficult because we don't have any lower bound measure on information content. We only have upper bounds..... My own NIPS 1993 paper on Siamese nets use a contrastive criterion. This was later revived by Raia Hadsell, Sumit Chopra and me in CVPR 2005 and 2006 papers (Dr LIM). It was re--revived by the SimCLR work (for which Geoff Hinton is a co-author) which showed surprisingly good experimental results on ImageNet. But then in 2021, we proposed a new non-contrastive infomax method called Barlow Twins (owing to Barlow's early advocacy of infomax). We later refined it into VICReg which gave SOTA results in a self-supervised scenario on ImageNet. We then augmented the joint embedding architecture with a predictor so it could be used as a world model (that was the plan all along. I had been talking about world models since 2015, including in my NIPS 2016 keynote). JEPA is merely a name for a general concept. The question is, and has always been, how do you make it work (particularly how do you prevent it from collapsing), and how do you make it work at scale with SOTA results on non-toy problems. That's the hard part. Ideas are a dime a dozen. Making them work is what the community will give you credit for."
My reply (see also screenshot 5):
LeCun concedes that “JEA” was introduced decades ago [IMAX][LEC22a], but still attempts to frame “JEPA” as a novel contribution [LEC22a][LEC]. The broader scientific community knows better. As Michal Valko (lead of [BYOL]) explicitly detailed [VAL26][WHO12]: "the JEPA lines are instantiations of [PMAX]” ... "Barlow Twins: ... literally Sec 2.3 of [PMAX]" ... “VICReg: ... is one section from [PMAX]." Scaling these 1992 blueprints to modern compute is cool, but the architectural foundation remains PMAX.
Valko further pointed out (personal communication, 2026): it was actually [BYOL] that first made the [PMAX] skeleton work at scale on ImageNet, in the hardest possible regime where ε=1 (eq. (2) of [PMAX]), that is, without an explicit Dl term to prevent collapse.
BYOL’s collapse-prevention toolkit (EMA + stop-grad + predictor asymmetry) was introduced to survive without Dl and is exactly what I-JEPA and V-JEPA later adopted to address LeCun's question: how do you prevent collapse and make it work at scale? Punchline: In 2025, LeCun's [LeJEPA] dropped EMA and stop-gradient entirely and went back to an explicit anti-collapse regularizer (SIGReg). That's a full circle return to the original 1992 [PMAX] philosophy of explicit Dl terms. So even within the JEPA lineage, the trajectory went: [PMAX]’s explicit Dl (1992) → [BYOL]'s implicit architectural tricks (2020) → LeCun’s JEPAs using BYOL tricks (2023-2024) → back to explicit Dl in [LeJEPA] (2025). The field spent five years exploring the ε=1 regime opened up by BYOL, then came home to [PMAX]'s original ε<1 design. It's not just that JEPA is [PMAX], it's that even the detour away from explicit Dl eventually led back to [PMAX]'s origins.
Other comments.
On Facebook, LeCun claimed (see screenshot 4) that the experimental section in our [PMAX] paper "is essentially non-existent."
However, our 1992 [PMAX] paper had many experiments, while LeCun's JEPA paper [LEC22a] had none—despite compute being a million times cheaper in 2022.
LeCun refers to his "1993 paper on Siamese nets" which cited neither Becker & Hinton's "JEA" [IMAX] nor the 1992 [PMAX]/JEPA which solved a stereo task more readily than JEA and prevented "collapse."
LeCun keeps mentioning his "NIPS 2016 keynote" on "world models." It came after [PLAN4] and long after our earlier general purpose recurrent neural world models for partially observable environments since 1990 [GAN90][PLAN1-3][WM26] (key milestones in 1990, 91, 92, 97, 2000-2006, 2015).
Of course, my 1990 paper on recurrent neural nets as world models [GAN90] cited earlier works on less general, feedforward net-based systems (since 1987) for fully observable environments [WER87-89][MUN87][NGU89]. LeCun's much later 2022 paper on JEPA and world models [LEC22a] didn't. So I pointed him to these works in my 2022 critique [LEC], but he did not correct his paper [LEC22a].
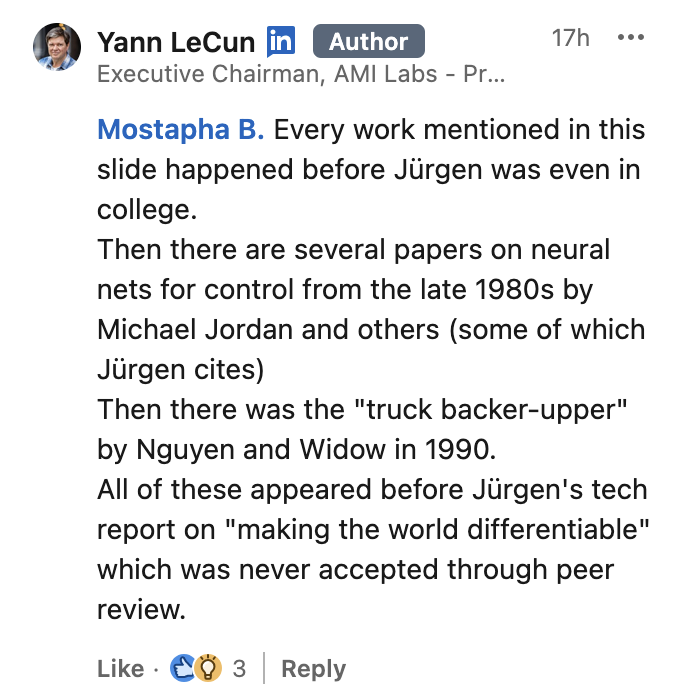
Years later, on 18 April 2026, LeCun finally mentioned at least [NGU89] (but not [WER87-89][MUN87]) on LinkedIn (see screenshot 6), then boldly claimed that [GAN90] "was never accepted through peer review." Of course, this is not true: [GAN90]'s planning part was published at IJCNN'90 [PLAN2], and the part on
artificial curiosity through generative & adversarial nets was published
at SAB'91 [GAN91][GAN20][WHO8].
LeCun spread additional falsehoods on social media: on 18 April 2026, he accused me of claiming that I "invented world models" (see screenshot 7) although I have always cited pre-1990 feedforward nets of this kind [WER87-89][MUN87][NGU89] which weren't called "world models" [GAN90] by their authors [WHO12]. In the 1980s, Werbos connected this work to earlier work on system identification in control theory, e.g., [WER87-89]. I even credited the ancient Greeks for the basic concept at a conference that LeCun attended [WM26b][WM26] (see video tweet).
LeCun's additional misleading statements about JEPA were discussed above [WHO12].
The conclusion still stands: the 2022 JEPA family is actually the 1992 PMAX family.
Acknowledgments
 Thanks to several expert reviewers for useful comments. (Let me know under juergen@idsia.ch if you can spot any remaining error.)
The contents of this article may be used for educational and non-commercial purposes, including articles for Wikipedia and similar sites.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Thanks to several expert reviewers for useful comments. (Let me know under juergen@idsia.ch if you can spot any remaining error.)
The contents of this article may be used for educational and non-commercial purposes, including articles for Wikipedia and similar sites.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

References
[AC]
J. Schmidhuber (AI Blog, 2021, updated 2025). 3 decades of artificial curiosity & creativity. Schmidhuber's artificial scientists not only answer given questions but also invent new questions. They achieve curiosity through: (1990) the principle of generative adversarial networks, (1991) neural nets that maximise learning progress, (1995) neural nets that maximise information gain (optimally since 2011), (1997) adversarial design of surprising computational experiments, (2006) maximizing compression progress like scientists/artists/comedians do, (2011) PowerPlay... Since 2012: applications to real robots.
[AC90]
J. Schmidhuber.
Making the world differentiable: On using fully recurrent
self-supervised neural networks for dynamic reinforcement learning and
planning in non-stationary environments.
Technical Report FKI-126-90, TUM, Feb 1990, revised Nov 1990.
PDF.
The first paper on planning with reinforcement learning recurrent neural networks (NNs) and recurrent world models (more), and on generative adversarial networks
where a generator NN is fighting a predictor NN in a minimax game
(more).
Apparently, it was also the first paper of this kind to use the term "world model" for the predictor NN (although the basic concept of a world model is much older than that.)
[AC90b]
J. Schmidhuber.
A possibility for implementing curiosity and boredom in
model-building neural controllers.
In J. A. Meyer and S. W. Wilson, editors, Proc. of the
International Conference on Simulation
of Adaptive Behavior: From Animals to
Animats, pages 222-227. MIT Press/Bradford Books, 1991. Based on [AC90].
PDF.
More.
[AC91]
J. Schmidhuber. Adaptive confidence and adaptive curiosity. Technical Report FKI-149-91, Inst. f. Informatik, Tech. Univ. Munich, April 1991.
PDF.
[AC91b]
J. Schmidhuber.
Curious model-building control systems.
Proc. International Joint Conference on Neural Networks,
Singapore, volume 2, pages 1458-1463. IEEE, 1991.
PDF.
[AC95]
J. Storck, S. Hochreiter, and J. Schmidhuber. Reinforcement-driven information acquisition in non-deterministic environments. In Proc. ICANN'95, vol. 2, pages 159-164. EC2 & CIE, Paris, 1995. PDF.
[AC97]
J. Schmidhuber.
What's interesting?
Technical Report IDSIA-35-97, IDSIA, July 1997.
Focus
on automatic creation of predictable internal
abstractions of complex spatio-temporal events:
two competing, intrinsically motivated agents agree on essentially
arbitrary algorithmic experiments and bet
on their possibly surprising (not yet predictable)
outcomes in zero-sum games,
each agent potentially profiting from outwitting / surprising
the other by inventing experimental protocols where both
modules disagree on the predicted outcome. The focus is on exploring
the space of general algorithms (as opposed to
traditional simple mappings from inputs to
outputs); the
general system
focuses on the interesting
things by losing interest in both predictable and
unpredictable aspects of the world. Unlike Schmidhuber et al.'s previous
systems with intrinsic motivation,[AC90-AC95] the system also
takes into account
the computational cost of learning new skills, learning when to learn and what to learn.
See later publications.[AC99][AC02]
[AC99]
J. Schmidhuber.
Artificial Curiosity Based on Discovering Novel Algorithmic
Predictability Through Coevolution.
In P. Angeline, Z. Michalewicz, M. Schoenauer, X. Yao, Z.
Zalzala, eds., Congress on Evolutionary Computation, p. 1612-1618,
IEEE Press, Piscataway, NJ, 1999.
[AC02]
J. Schmidhuber.
Exploring the Predictable.
In Ghosh, S. Tsutsui, eds., Advances in Evolutionary Computing,
p. 579-612, Springer, 2002.
PDF.
[AC09]
J. Schmidhuber. Art & science as by-products of the search for novel patterns, or data compressible in unknown yet learnable ways. In M. Botta (ed.), Et al. Edizioni, 2009, pp. 98-112.
PDF. (More on
artificial scientists and artists.)
[AC10]
J. Schmidhuber. Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990-2010). IEEE Transactions on Autonomous Mental Development, 2(3):230-247, 2010.
IEEE link.
PDF.
[AIB]
J. Schmidhuber's AI Blog.
With lessons on the history of AI & computing, e.g.:
Who invented deep learning?
Who invented backpropagation?
Who invented convolutional neural networks?
Who invented artificial neural networks?
Who invented generative adversarial networks?
Who invented Transformer neural networks?
Who invented deep residual learning?
Who invented neural knowledge distillation?
Who invented the computer?
Who invented the transistor?
Who invented the integrated circuit?
...
[AMI1]
Humanoids Daily (10 March 2026). Quote: "At the heart of AMI’s technical strategy is the Joint Embedding Predictive Architecture (JEPA)."
[AMI2]
36KR European Central Station (10 March 2026). Quote: "AMI Labs, a startup based on the Joint Embedding Predictive Architecture (JEPA) proposed by LeCun in 2022 ..."
[ARI1]
Aristotle (circa 350 BC). De Anima (On the Soul).
[BYOL]
J. Grill, F. Strub, F. Altché, C. Tallec, P. H. Richemond, E. Buchatskaya, C. Doersch, B. A. Pires, Z. D. Guo, M. Gheshlaghi Azar, B. Piot, K. Kavukcuoglu, R. Munos, M. Valko (2020). Bootstrap your own latent: a "new" approach to self-supervised learning. arXiv:2006.07733
[DLH]
J. Schmidhuber.
Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, IDSIA, Switzerland, 2022, updated 2025.
Preprint arXiv:2212.11279.
Tweet.
[DLP]
J. Schmidhuber.
How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23, Swiss AI Lab IDSIA, 14 Dec 2023, updated 2025.
Tweet of 2023.
[CRA67]
K. J. W. Craik (1967). The Nature of Explanation.
[FAKE1]
H. Hopf, A. Krief, G. Mehta, S. A. Matlin.
Fake science and the knowledge crisis: ignorance can be fatal.
Royal Society Open Science, May 2019.
Quote: "Scientists must be willing to speak out when they see false information being presented in social media, traditional print or broadcast press" and "must speak out against false information and fake science in circulation
and forcefully contradict public figures who promote it."
[FAKE2]
L. Stenflo.
Intelligent plagiarists are the most dangerous. Nature, vol. 427, p. 777 (Feb 2004).
Quote: "What is worse, in my opinion, ..., are cases where scientists rewrite previous findings in different words, purposely hiding the sources of their ideas, and then during subsequent years forcefully claim that they have discovered new phenomena."
[FAKE3] S. Vazire (2020). A toast to the error detectors. Let 2020 be the year in which we value those who ensure that science is self-correcting. Nature, vol 577, p 9, 2/2/2020.
[GAN90]
J. Schmidhuber.
Making the world differentiable: On using fully recurrent
self-supervised neural networks for dynamic reinforcement learning and
planning in non-stationary environments.
Technical Report FKI-126-90, TUM, Feb 1990, revised Nov 1990.
PDF.
The first paper on planning with reinforcement learning recurrent neural networks (NNs) and recurrent world models (more), and on generative adversarial networks
where a generator NN is fighting a predictor NN in a minimax game
(more).
Apparently, it was also the first paper of this kind to use the term "world model" for the predictor NN (although the basic concept of a world model is much older than that.)
[GAN91]
J. Schmidhuber.
A possibility for implementing curiosity and boredom in
model-building neural controllers.
In J. A. Meyer and S. W. Wilson, editors, Proc. of the
International Conference on Simulation
of Adaptive Behavior: From Animals to
Animats, pages 222-227. MIT Press/Bradford Books, 1991.
PDF.
More.
Based on [GAN90].
[GAN20]
J. Schmidhuber. Generative Adversarial Networks are Special Cases of Artificial Curiosity (1990) and also Closely Related to Predictability Minimization (1991).
Neural Networks, Volume 127, p 58-66, 2020.
Preprint arXiv/1906.04493.
[GAN25]
J. Schmidhuber. Who Invented Generative Adversarial Networks? Technical Note IDSIA-14-25, IDSIA, December 2025.
[IDEAS]
R. Sutton (2025).
Ideas Matter.
[IMAX]
S. Becker, G. E. Hinton. Spatial coherence as an internal teacher for a neural network. TR CRG-TR-89-7, Dept. of CS, U. Toronto, 1989.
[LE1]
J. Schmidhuber.
Who invented convolutional neural networks (CNNs)?
Tweet of 3 Aug 2025. See also
LinkedIn post.
See also F. Chollet's tweet of 3 Dec 2025.
[LE2]
J. Schmidhuber.
Fukushima's video (1986) shows a CNN that recognises handwritten digits, three years before LeCun's video (1989).
Tweet of 2 Dec 2025.
See also L. Bayer's tweet of 3 Dec 2025.
[LE3]
J. Schmidhuber. LeCun’s 2022 paper on autonomous machine intelligence rehashes but doesn’t cite essential work of 1990-2015.
Tweet of 7 Jul 2022.
[LE4]
J. Schmidhuber. LeCun's "5 best ideas 2012-22” are mostly from my lab, and older: 1 Self-supervised 1991 RNN stack; 2 ResNet = open-gated 2015 Highway Net; 3&4 Key/Value-based fast weights 1991; 5 Transformers with linearized self-attention 1991. (Also GAN 1990.)
Tweet of 15 Sep 2022.
[LE5]
J. Schmidhuber. Quote tweet (19 Nov 2025) of "The False Glorification ..." by G. Marcus.
[LE6]
J. Schmidhuber. How 3 Turing awardees republished key methods and ideas whose creators they failed to credit.
Tweet of 14 Dec 2023.
[LE7]
J. Schmidhuber.
LeCun’s 2025 company on physical AI with world models looks a lot like our 2014 company on physical AI with world models.
Tweet of 21 Dec 2025.
LinkedIn Post.
[LE8]
J. Schmidhuber.
Dr. LeCun's heavily promoted Joint Embedding Predictive Architecture (JEPA, 2022) is the heart of his new company. However, the core ideas are not original to LeCun. Instead, JEPA is essentially identical to our 1992 Predictability Maximization system (PMAX).
Tweet of 31 Mar 2026.
LinkedIn Post.
[LE9]
Calc Consulting. PMAX tweet of 6 April 2026. Quote: "In that sense, Juergen Schmidhuber made the real and original conceptual breakthrough: non-generative, latent-to-latent predictive learning."
[LEC] J. Schmidhuber (AI Blog, 2022). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015. Years ago, Schmidhuber's team published most of what LeCun calls his "main original contributions:" neural nets that learn multiple time scales and levels of abstraction, generate subgoals, use intrinsic motivation to improve world models, and plan (1990); controllers that learn informative predictable representations (1997), etc. This was also discussed on Hacker News, reddit, and in the media.
[LEC22a]
Y. LeCun (27 June 2022).
A Path Towards Autonomous Machine Intelligence.
OpenReview Archive.
Link. See critique [LEC].
[LeJEPA]
R. Balestriero, Y. LeCun.
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics.
arXiv:2511.08544.
[MAR24]
G. Marcus.
Open letter responding to Yann LeCun.
A memo for future intellectual historians.
Substack, June 2024.
[MAR25]
G. Marcus.
The False Glorification of Yann LeCun.
Don’t believe everything you read.
Substack, Nov 2025.
[META]
J. Schmidhuber (AI Blog, 2020). 1/3 century anniversary of
first publication on metalearning machines that learn to learn (1987).
For its cover I drew a robot that bootstraps itself.
1992-: gradient descent-based neural metalearning. 1994-: Meta-Reinforcement Learning with self-modifying policies. 1997: Meta-RL plus artificial curiosity and intrinsic motivation. 2002-: asymptotically optimal metalearning for curriculum learning. 2003-: mathematically optimal Gödel Machine. 2020: new stuff!
[META1]
J. Schmidhuber.
Evolutionary principles in self-referential learning, or on learning
how to learn: The meta-meta-... hook. Diploma thesis,
Institut für Informatik, Technische Universität München, 1987.
Searchable PDF scan (created by OCRmypdf which uses
LSTM).
HTML.
For example,
Genetic Programming
(GP) is applied to itself, to recursively evolve
better GP methods through Meta-Evolution. More.
[MIR] J. Schmidhuber (Oct 2019, updated 2021, 2022, 2025). Deep Learning: Our Miraculous Year 1990-1991. Preprint
arXiv:2005.05744. The Deep Learning Artificial Neural Networks (NNs)
of our team have
revolutionised
Machine Learning & AI.
Many of the basic ideas behind this revolution were published within the 12 months of our "Annus Mirabilis" 1990-1991 at our lab in TU Munich.
Back then, few people were interested. But a quarter century later, NNs based on our "Miraculous Year"
were on over 3 billion devices,
and used many billions of times per day,
consuming a significant fraction of the world's compute.
In particular, in 1990-91, we laid foundations of Generative AI, publishing principles of (1)
Generative Adversarial Networks for Artificial Curiosity and Creativity (now used for deepfakes), (2) Transformers (the T in ChatGPT—see the 1991 Unnormalized Linear Transformer), (3) Pre-training for deep NNs (see the P in ChatGPT), (4) NN distillation (key for DeepSeek), and (5) recurrent World Models for
Reinforcement Learning and Planning in partially observable environments. The year 1991 also marks the emergence of the defining features of (6)
LSTM, the most cited AI paper of the 20th century (based on constant error flow through residual NN connections), and (7) ResNet, the most cited AI paper of the 21st century, based on our LSTM-inspired Highway Net that was
10 times deeper than previous feedforward NNs.
[MOST]
J. Schmidhuber (AI Blog, 2021, updated 2025). The most cited neural networks all build on work done in my labs: 1. Long Short-Term Memory (LSTM), the most cited AI of the 20th century. 2. ResNet (open-gated Highway Net), the most cited AI of the 21st century. 3. AlexNet & VGG Net (the similar but earlier DanNet of 2011 won 4 image recognition challenges before them). 4. GAN (an instance of Adversarial Artificial Curiosity of 1990). 5. Transformer variants—see the 1991 unnormalised linear Transformer (ULTRA). Foundations of Generative AI were published in 1991: the principles of GANs (now used for deepfakes), Transformers (the T in ChatGPT), Pre-training for deep NNs (the P in ChatGPT), NN distillation, and the famous DeepSeek—see the tweet.
[MOST26]
J. Schmidhuber. The two most frequently cited papers of all time are based on our 1991 work. Technical Note IDSIA-1-26, January 2026.
[MUN87]
P. W. Munro. A dual back-propagation scheme for scalar reinforcement learning. Proceedings of the Ninth Annual Conference of the Cognitive Science Society, Seattle, WA, pages 165-176, 1987.
[NAI] NNAISENSE, the AGI company for AI in the physical world, founded in 2014, based on neural network world models. J. Schmidhuber was its President and Chief Scientist. See the 2020 NNAISENSE web page in the Internet Archive. (Lately, however, NNAISENSE has become less AGI-focused and more specialised, with a focus on asset management.)
[NGU89]
D. Nguyen and B. Widrow; The truck backer-upper: An example of self learning in neural networks. In IEEE/INNS International Joint Conference on Neural Networks, Washington, D.C., volume 1, pages 357-364, 1989.
[PLA1]
M. Uehleke (2022).
Plato's Theory of Forms: How Ancient Philosophy Still Shapes Modern Thinking. The Philosopher's Shirt, 2022.
[PLAG1]
Oxford's guide to types of plagiarism (2021).
Quote: "Plagiarism may be intentional or reckless, or unintentional."
Copy in the Internet Archive.
Local copy.
[PLAG2]
Jackson State Community College (2022).
Unintentional Plagiarism.
Copy in the Internet Archive.
[PLAG3]
R. L. Foster.
Avoiding Unintentional Plagiarism.
Journal for Specialists in Pediatric Nursing; Hoboken Vol. 12, Iss. 1, 2007.
[PLAG4]
N. Das.
Intentional or unintentional, it is never alright to plagiarize: A note on how Indian universities are advised to handle plagiarism.
Perspect Clin Res 9:56-7, 2018.
[PLAG5]
InfoSci-OnDemand (2023).
What is Unintentional Plagiarism?
Copy in the Internet Archive.
[PLAG6]
Copyrighted.com (2022).
How to Avoid Accidental and Unintentional Plagiarism (2023).
Copy in the Internet Archive. Quote: "May it be accidental or intentional, plagiarism is still plagiarism."
[PLAG7]
Cornell Review, 2024.
Harvard president resigns in plagiarism scandal. 6 January 2024.
[PLAN]
J. Schmidhuber (AI Blog, 2020). 30-year anniversary of planning & reinforcement learning with recurrent world models and artificial curiosity (1990). This work also introduced high-dimensional reward signals, deterministic policy gradients for RNNs, and
the GAN principle (widely used today). Agents with adaptive recurrent world models even suggest a simple explanation of consciousness & self-awareness.
[PLAN1]
J. Schmidhuber.
Making the world differentiable: On using fully recurrent
self-supervised neural networks for dynamic reinforcement learning and
planning in non-stationary environments.
Technical Report FKI-126-90, TUM, Feb 1990, revised Nov 1990.
PDF.
The first paper on long-term planning with self-supervised reinforcement learning recurrent neural networks (NNs) and recurrent predictive world models (more), and on generative adversarial networks
where a generator NN is fighting a predictor NN in a minimax game
(more).
Apparently, it was also the first paper of this kind to use the term "world model" for the predictor NN (although the basic concept of a world model is much older than that.)
[PLAN2]
J. Schmidhuber.
An on-line algorithm for dynamic reinforcement learning and planning
in reactive environments.
Proc. IEEE/INNS International Joint Conference on Neural
Networks, San Diego, volume 2, pages 253-258, June 17-21, 1990.
Based on TR FKI-126-90 (1990) [PLAN1].
More.
[PLAN3]
J. Schmidhuber.
Reinforcement learning in Markovian and non-Markovian environments.
In D. S. Lippman, J. E. Moody, and D. S. Touretzky, editors,
Advances in Neural Information Processing Systems 3, NIPS'3, pages 500-506. San
Mateo, CA: Morgan Kaufmann, 1991.
PDF.
Partially based on [PLAN1].
[PLAN4]
J. Schmidhuber.
On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models.
Report arXiv:1210.0118 [cs.AI], 2015.
This paper went beyond the inefficient millisecond by millisecond planning of 1990 [PLAN1], addressing planning and reasoning in abstract concept spaces. The controller C became an RL prompt engineer that learns to create a chain of thought: to speed up RL, C learns to query its world model for abstract reasoning and decision making.
[PLAN5]
One Big Net For Everything. Preprint arXiv:1802.08864 [cs.AI], Feb 2018.
This paper collapsed the control network and the world model network of [PLAN4] into a single One Big Net for everything, using my neural distillation procedure of 1991 [UN0-1]. Apparently, this is what DeepSeek used to shock the stock market in 2025.
[PLAN6]
D. Ha, J. Schmidhuber. Recurrent World Models Facilitate Policy Evolution. Advances in Neural Information Processing Systems (NIPS), Montreal, 2018. (Talk.)
Preprint: arXiv:1809.01999.
Github: World Models.
[PM1] J. Schmidhuber. Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879, 1992. Based on TR CU-CS-565-91, Univ. Colorado at Boulder, 1991. PDF.
More.
[PM2] J. Schmidhuber, M. Eldracher, B. Foltin. Semilinear predictability minimzation produces well-known feature detectors. Neural Computation, 8(4):773-786, 1996.
PDF. More.
[PMAX] J. Schmidhuber and D. Prelinger. Discovering predictable classifications. Neural Computation, 5(4):625-635, 1993. Based on TR CU-CS-626-92 (1992). PDF.
[RAW]
J. Schmidhuber (AI Blog, 2001). Raw Computing Power.
[UN0]
J. Schmidhuber.
Neural sequence chunkers.
Technical Report FKI-148-91, Institut für Informatik, Technische
Universität München, April 1991.
PDF.
Unsupervised/self-supervised pre-training for deep neural networks
(see the P in ChatGPT) and predictive coding is used
in a deep hierarchy of recurrent nets (RNNs)
to find compact internal
representations of long sequences of data,
across multiple time scales and levels of abstraction.
Each RNN tries to solve the pretext task of predicting its next input, sending only unexpected inputs to the next RNN above.
The resulting compressed sequence representations
greatly facilitate downstream supervised deep learning such as sequence classification.
By 1993, the approach solved problems of depth 1000 [UN2]
(requiring 1000 subsequent computational stages/layers—the more such stages, the deeper the learning).
A variant collapses the hierarchy into a single deep net.
It uses a so-called conscious chunker RNN
which attends to unexpected events that surprise
a lower-level so-called subconscious automatiser RNN.
The chunker learns to understand the surprising events by predicting them.
The automatiser uses a
neural knowledge distillation procedure (key for the famous 2025 DeepSeek)
to compress and absorb the formerly conscious insights and
behaviours of the chunker, thus making them subconscious.
The systems of 1991 allowed for much deeper learning than previous methods.
[UN1] J. Schmidhuber. Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242, 1992. Based on TR FKI-148-91, TUM, 1991.[UN0] PDF.
First working Deep Learner based on a deep RNN hierarchy (with different self-organising time scales),
overcoming the vanishing gradient problem through unsupervised pre-training of deep NNs (see the P in ChatGPT) and predictive coding (with self-supervised target generation).
Also: compressing or distilling a teacher net (the chunker) into a student net (the automatizer) that does not forget its old skills—such approaches are now widely used, e.g., by DeepSeek. See also this tweet. More.
[UN2] J. Schmidhuber. Network architectures, objective functions, and chain rule. Habilitation thesis, TUM, 1993. PDF. See Sec. 5.5 on "Vorhersagbarkeitsmaximierung" (Predictability Maximization).
[VAL26]
M. Valko, leader of the [BYOL] team (personal communication, March 2026, reprinted with permission). Quote:
"It's amazing how [PMAX] is a proto-self-supervised learning / contrastive learning framework, predating SimCLR, BYOL, Barlow Twins, VICReg by ~25-30 years. It's shocking how it's not celebrated more. Yes, I totally agree that the JEPA lines are instantiations of PMAX, sometimes with extra modification:
★ Barlow Twins: penalize off-diagonal cross-correlation (literally Sec. 2.3 of [PMAX] with a different name).
★ VICReg: variance hinge (Sec. 2.1) plus covariance penalty (Sec. 2.3) applied simultaneously, so indeed that paper is one section from [PMAX].
★ I-JEPA: Drop the discrimination (D) term of PMAX, use EMA stop-gradient instead; replace augmentation with image patch masking.
★ V-JEPA: I-JEPA but masking is spatiotemporal over video frames.
★ DINO: D based on centering (subtract teacher output mean) plus sharpening (low-temperature softmax).
★ DINOv2: DINO plus iBOT masking objective bolted on; adds I-JEPA-style masked prediction as auxiliary loss.
★ LeJEPA (2025): D is SIGReg, match 1D marginals to isotropic Gaussian; drops EMA/stop-gradient entirely.
★ LLM-JEPA (2025): [PMAX] applied to language; encoder predicts continuous embeddings of masked tokens instead of discrete tokens.
★ VL-JEPA (2025): [PMAX] with vision encoder and language encoder; cross-modal masked prediction.
★ Rectified LpJEPA (2026): D = RDMReg, match marginals to rectified generalized Gaussian; forces sparse non-negative codes."
[WER87]
P. J. Werbos. Building and understanding adaptive systems: A statistical/numerical approach to factory automation and brain research. IEEE Transactions on Systems, Man, and Cybernetics, 17, 1987.
[WER89]
P. J. Werbos. Backpropagation and neurocontrol: A review and prospectus. In IEEE/INNS International Joint Conference on Neural Networks, Washington, D.C., volume 1, pages 209-216, 1989.
[WHO4]
J. Schmidhuber. Who invented artificial neural networks? Technical Note IDSIA-15-25, IDSIA, Switzerland, Nov 2025.
[WHO5]
J. Schmidhuber. Who invented deep learning? Technical Note IDSIA-16-25, IDSIA, Switzerland, Nov 2025.
[WHO6] J. Schmidhuber (AI Blog, 2014; updated 2025).
Who invented backpropagation?
See also LinkedIn post.
[WHO7]
J. Schmidhuber.
Who invented convolutional neural networks? Technical Note IDSIA-17-25, IDSIA, Switzerland, 2025. See popular tweet.
[WHO8]
J. Schmidhuber. Who Invented Generative Adversarial Networks? Technical Note IDSIA-14-25, IDSIA, Switzerland, Dec 2025.
[WHO9]
J. Schmidhuber. Who invented knowledge distillation with artificial neural networks? Technical Note IDSIA-12-25, IDSIA, Nov 2025.
[WHO10]
J. Schmidhuber. Who Invented Transformer Neural Networks? Technical Note IDSIA-11-25, IDSIA, Switzerland, Nov 2025.
[WHO11]
J. Schmidhuber. Who Invented Deep Residual Learning? Technical Report IDSIA-09-25, IDSIA, Switzerland, Sept 2025. Preprint arXiv:2509.24732.
[WHO12]
J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026 (updated in April).
[WM26] J. Schmidhuber. The Neural World Model Boom. Technical Note IDSIA-2-26, 4 Feb 2026.
[WM26b] J. Schmidhuber. Simple but powerful ways of using world models and their latent space. Opening Keynote at the World Modeling Workshop, Agora, Mila - Quebec AI Institute, 4 Feb 2026. Also on YouTube (starts around 10:44). See video tweet.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}