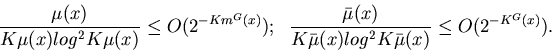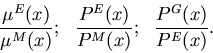Using
| (39) |
Proof.
The left-hand inequality follows by definition.
To show the right-hand side, one can build an EOM T that computes
![]() using not more than
KPE(x) + KT(KPE(x)) + O(1) input
bits in a way inspired by Huffman-Coding [#!Huffman:52!#].
The claim then follows from the Invariance Theorem.
The trick is to arrange T's computation such that T's output converges
yet never needs to decrease lexicographically.
T works as follows:
using not more than
KPE(x) + KT(KPE(x)) + O(1) input
bits in a way inspired by Huffman-Coding [#!Huffman:52!#].
The claim then follows from the Invariance Theorem.
The trick is to arrange T's computation such that T's output converges
yet never needs to decrease lexicographically.
T works as follows:
(A) Emulate UE to construct a real enumerable number 0.s encoded as a self-delimiting input program r, simultaneously run all (possibly forever running) programs on UE dovetail style; whenever the output of a prefix q of any running program starts with someThis will never violate the EOM constraints: the enumerable s cannot shrink, and since EOM outputs cannot decrease lexicographically, the interval boundaries RV(x) and LV(x) cannot grow (their negations are enumerable, compare Lemma 4.1), hence T's output cannot decrease.for the first time, set variable V(x) := V(x) + 2-l(q) (if no program has ever created output starting with x then first create V(x) initialized by 0); whenever the output of some extension q' of q (obtained by possibly reading additional input bits: q'=q if none are read) lexicographically increases such that it does not equal x any more, set V(x) := V(x) - 2-l(q').
(B) Simultaneously, starting at the right end of the unit interval [0,1), as the V(x) are being updated, keep updating a chain of disjoint, consecutive, adjacent, half-open (at the right end) intervals IV(x) = [LV(x), RV(x)) of size V(x) = RV(x) - LV(x) in alphabetic order on x, such that the right end of the IV(x) of the largest x coincides with the right end of [0,1), and IV(y) is to the right of IV(x) if
. After every variable update and each change of s, replace the output of T by the x of the IV(x) with
.
For ![]() the IV(x) converge towards an interval I(x) of
size PE(x). For
the IV(x) converge towards an interval I(x) of
size PE(x). For
![]() with
PE(x) > 0, we have: for any
with
PE(x) > 0, we have: for any
![]() there is a time t0 such that for all time steps t>t0
in T's computation, an interval
there is a time t0 such that for all time steps t>t0
in T's computation, an interval
![]() of size
of size
![]() will be completely covered by certain IV(y) satisfying
will be completely covered by certain IV(y) satisfying ![]() and
and
![]() .
So for
.
So for
![]() the
the
![]() also converge towards an interval I(x) of size PE(x).
Hence T will output larger and larger y approximating x from below,
provided
also converge towards an interval I(x) of size PE(x).
Hence T will output larger and larger y approximating x from below,
provided
![]() .
.
Since any interval of size c within [0,1) contains a number 0.z
with l(z) = -lg c, in both cases there is a number 0.s (encodable
by some r satisfying
![]() )
with l(s) =
-lg PE(x) + O(1), such that
)
with l(s) =
-lg PE(x) + O(1), such that
![]() ,
and therefore
,
and therefore
![]() .
.
![]()
Less symmetric statements can also be derived in very similar fashion:
Proof. Modify the proof of Theorem 5.3 for approximable
as opposed to enumerable interval boundaries and approximable 0.s.
![]()
A similar proof, but without the complication for the case
![]() ,
yields:
,
yields:
| (41) |
| (42) |
Proof.
Initialize variables
![]() and
and
![]() .
Dovetailing over all
.
Dovetailing over all
![]() ,
approximate the GTM-computable
,
approximate the GTM-computable
![]() in
variables Vx initialized by zero, and create a chain of adjacent
intervals IVx analogously to the proof of Theorem 5.3.
in
variables Vx initialized by zero, and create a chain of adjacent
intervals IVx analogously to the proof of Theorem 5.3.
The IVx converge against intervals Ix of size
![]() .
Hence x
is GTM-encodable by any program r producing an output s with
.
Hence x
is GTM-encodable by any program r producing an output s with
![]() :
after every update, replace the GTM's output by the x of
the IVx with
:
after every update, replace the GTM's output by the x of
the IVx with
![]() .
Similarly, if 0.s
is in the union of adjacent intervals Iy of strings y starting with x,
then the GTM's output
will converge towards some string starting with x.
The rest follows in a way similar
to the one described in the
final paragraph of the proof of Theorem 5.3.
.
Similarly, if 0.s
is in the union of adjacent intervals Iy of strings y starting with x,
then the GTM's output
will converge towards some string starting with x.
The rest follows in a way similar
to the one described in the
final paragraph of the proof of Theorem 5.3. ![]()
Using the basic ideas in the proofs of Theorem 5.3 and 5.5 in conjunction with Corollary 4.3 and Lemma 4.2, one can also obtain statements such as:
While PE dominates PM and PG dominates PE, the reverse statements are not true. In fact, given the results from Sections 3.2 and 5, one can now make claims such as the following ones:
Proof.
For the cases ![]() and PE, apply Theorems 5.2, 5.6 and
the unboundedness of (12).
For the case PG, apply Theorems 3.3 and 5.3.
and PE, apply Theorems 5.2, 5.6 and
the unboundedness of (12).
For the case PG, apply Theorems 3.3 and 5.3.