
|
(a Highway Net with open gates) |
Background: GPUs were originally developed for the video game industry. But they can also be used to speed up artificial neural networks (NNs), as shown in 2004 by Jung & Oh [1]. Nevertheless, until 2010, many researchers thought that one cannot train deep NNs by plain backpropagation, the popular technique published by Linnainmaa in 1970 [5,5a-c,6,27].

Why not? Because of the fundamental deep learning problem identified in 1991 by my very first student Sepp Hochreiter [2c]: In typical deep or recurrent networks, back-propagated error signals either grow or decay exponentially in the number of layers.
That's why many scientists thought that NNs have to be pre-trained by unsupervised learning - something that I did first for general purpose deep recurrent NNs in 1991 (my first very deep learner) [2,2a], and that others did for less general feedforward NNs in 2006 [19a] (in 2008 also on GPU [1b]).

In 2010, however, our team at IDSIA (Dan Ciresan et al [18a,18a+,18a++]) showed that GPUs can be used to train deep standard supervised NNs by plain backpropagation [5, 7], achieving a 50-fold speedup over CPUs, and breaking the long-standing famous MNIST [15c] benchmark record [18a,18a++], using pattern distortions [14]. This really was all about GPUs—no novel NN techniques were necessary, no unsupervised pre-training, only decades-old stuff. One of the reviewers called this a "wake-up call" to the machine learning community, which quickly adopted the method [18a+,18a++]. Compare also Sec. 19 of [24].
In 2011, we extended [18b-g] this approach to the convolutional NNs (CNNs) developed by Fukushima (1979), Waibel (1987), Zhang et al. (backpropagation for 2D CNNs, 1988), LeCun et al. (1989), Weng (1993), and others [4] (more on the history of CNNs in [28,30] and Sec. D & Sec. XVIII & Sec. XIV of [19a]). Our GPU-based deep DanNet [18b-g] was 60 times faster [18b] than CPU-based CNNs, and much faster and deeper than previous shallow GPU-CNNs [1b]. It became the basis for a whole series of victories in computer vision contests (see Table 1). In 2011, this attracted enormous interest from industry. Today, the world's most famous IT companies are heavily using such techniques.
 In particular, in 2011, DanNet was
the first pure, deep GPU-CNN to win international
pattern recognition contests [18c-g].
The very first event won by DanNet was the Chinese handwriting recognition contest at ICDAR 2011 [18e]—highly important for all those cell phone makers who want to build smartphones that can read signs and restaurant menus in foreign languages.
In particular, in 2011, DanNet was
the first pure, deep GPU-CNN to win international
pattern recognition contests [18c-g].
The very first event won by DanNet was the Chinese handwriting recognition contest at ICDAR 2011 [18e]—highly important for all those cell phone makers who want to build smartphones that can read signs and restaurant menus in foreign languages.
This attracted a lot of industry attention—it became clear that this was the way forward in computer vision. In particular, Apple hired one of our award-winning team. (Some people think that Apple came late to the deep learning GPU-CNN party, but no, they got active as soon as this became commercially relevant.)

Less than 3 months later, in August 2011 in Silicon Valley, DanNet achieved the first superhuman pattern recognition result in the history of computer vision [18c-g]. Our system was twice better than humans, three times better than the closest artificial competitor (from NYU), and six times better than the best non-neural method.
And then it kept winning those contests with larger and larger images, as shown in Table 1 (compare Kurzweil AI interview of 2012).
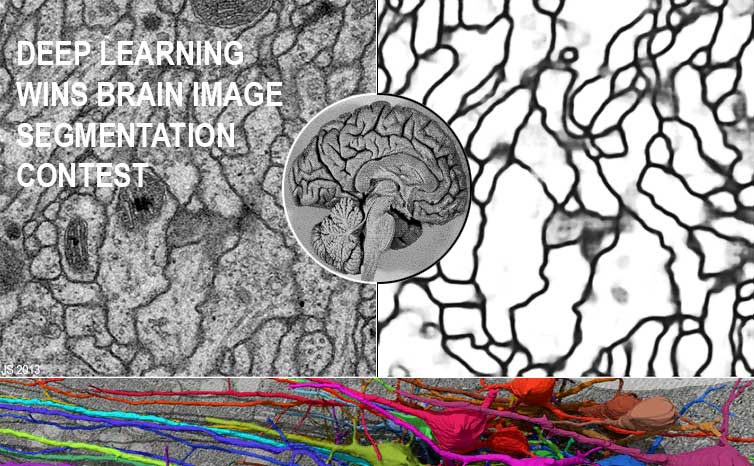
Table 1 also reflects that DanNet was the first neural network to win an image segmentation contest (Mar 2012) [20d,20d+], the first NN to win a contest on object detection in large images (10 Sep 2012) [20a,c], the first to win medical imaging contests in general, and the first to win cancer detection contests in particular (Mitosis Detection in Breast Cancer Histological Images, 2012 & 2013) [20a-c]. Our fast CNN image scanners were over 1000 times faster than previous methods [20e].
Today, many startups as well as established companies such as IBM & Google are using such deep GPU-CNNs for healthcare applications (note that healthcare makes up 10% of the world's GDP) [25].
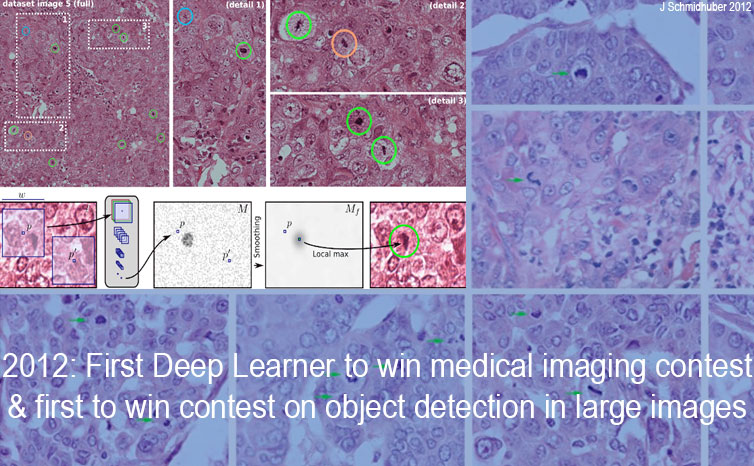
In 2011-2012, DanNet won every contest it entered. It did not participate in ImageNet competitions, focusing instead on contests with larger images (ISBI 2012, ICPR 2012, MICCAI 2013, see Table 1). However, the ImageNet 2012 winner AlexNet [19] (see Table 1) is similar to DanNet [18b-g] (compare [29] and Sec. XIV of [19a]). So is the ImageNet 2014 winner VGG Net [26,29].
We continued to make NNs even deeper and better. Until 2015, deep NNs had at most a few tens of layers, e.g., 20-30 layers. But in May 2015, there was something new: our Highway Network [11a-d] was the first working really deep feedforward NN with hundreds of layers, based on the LSTM principle [8,9] which enabled much deeper learning. The ImageNet 2015 winner ResNet [12] of Dec 2015 (Table 1) is a variant thereof. In fact, ResNets are Highway Nets whose gates are always open.

(Table 1 does not list contests won through combinations of CNNs and other techniques such as Support Vector Machines and Bag of Features, e.g., the 2009 TRECVID competitions [21, 22]. It also does not include benchmark records broken outside of contests with concrete deadlines.)
We never needed any of the popular NN regularisers, which tend to improve error rates by at most a few percent, which pales against the dramatic improvements brought by sheer GPU computing power. Compare [28] and Sec. XIV of [19a].

We used the GPUs of NVIDIA, which rebranded itself as a deep learning company during the period covered by the competitions in Table 1. BTW, thanks to NVIDIA and its CEO Jensen H. Huang (see image above) for our 2016 NN Pioneers of AI Award, and for generously funding our research!
Most of the major IT companies such as Facebook are now using such deep GPU-CNNs for image recognition and a multitude of other applications [22]. Arcelor Mittal, the world's largest steel maker, worked with us to greatly improve steel defect detection [3].
 However, long before our
feedforward DanNet started winning competitions in 2011,
our
CTC-trained Long Short-Term Memory (LSTM) [8,9,10,10a]
became the first general purpose recurrent NN to win competitions, namely, three
ICDAR 2009 Connected Handwriting Competitions (French, Farsi, Arabic).
By the mid 2010s,
LSTM was
heavily used
for natural language processing, image captioning, speech recognition and generation, chatbots, smart assistants, prediction, etc. Remarkably,
LSTM concepts also invaded CNN territory [11a,b,c,d,12],
also through GPU-friendly multi-dimensional LSTMs such as PyraMiD-LSTM [23].
However, long before our
feedforward DanNet started winning competitions in 2011,
our
CTC-trained Long Short-Term Memory (LSTM) [8,9,10,10a]
became the first general purpose recurrent NN to win competitions, namely, three
ICDAR 2009 Connected Handwriting Competitions (French, Farsi, Arabic).
By the mid 2010s,
LSTM was
heavily used
for natural language processing, image captioning, speech recognition and generation, chatbots, smart assistants, prediction, etc. Remarkably,
LSTM concepts also invaded CNN territory [11a,b,c,d,12],
also through GPU-friendly multi-dimensional LSTMs such as PyraMiD-LSTM [23].

We are proud that our deep learning methods developed since 1991 have transformed machine learning and Artificial Intelligence (AI), and became available to billions of users through the world's four most valuable public companies: Apple (#1 as of March 31, 2017), Google (Alphabet, #2), Microsoft (#3), and Amazon (#4).

Acknowledgments
Thanks to several expert reviewers for useful comments.
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
References
[1] Oh, K.-S. and Jung, K. (2004). GPU implementation of neural networks. Pattern Recognition, 37(6):1311-1314. [Speeding up traditional NNs on GPU by a factor of 20.]
[1a] K. Chellapilla, S. Puri, P. Simard. High performance convolutional neural networks for document processing. International Workshop on Frontiers in Handwriting Recognition, 2006. [Speeding up shallow CNNs on GPU by a relatively small factor of 4.]
[1b] Raina, R., Madhavan, A., and Ng, A. (2009). Large-scale deep unsupervised learning using graphics processors. In Proceedings of the 26th Annual International Conference on Machine Learning (ICML), pages 873-880. ACM. Based on a NIPS 2008 workshop paper.
[2] Schmidhuber, J. (1992). Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242. Based on TR FKI-148-91, TUM, 1991. More.
[2a] J. Schmidhuber. Habilitation thesis, TUM, 1993. PDF. An ancient experiment with credit assignment across 1200 time steps or virtual layers and unsupervised pre-training for a stack of recurrent NNs can be found here.
[2c] S. Hochreiter. Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, TU Munich, in J. Schmidhuber's lab, 1991.
[3] J. Masci, U. Meier, D. Ciresan, G. Fricout, J. Schmidhuber. Steel Defect Classification with Max-Pooling Convolutional Neural Networks. Proc. IJCNN 2012.
[4] Fukushima's CNN architecture [13a, 13b] (1979) (with Weng's Max-Pooling [13g], 1993) is trained [6] in the shift-invariant 1D case [13c, 13e] or 2D case [13d, 16, 17] by Linnainmaa's automatic differentiation or backpropagation algorithm of 1970 [5, 7] (extending earlier work in control theory [5a-c]).
[5] S. Linnainmaa. The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's Thesis (in Finnish), Univ. Helsinki, 1970. See chapters 6-7 and FORTRAN code on pages 58-60. PDF. See also BIT 16, 146-160, 1976. Link. [The first publication of "modern" backpropagation, also known as the reverse mode of automatic differentiation.]
[5a] Kelley, H. J. (1960). Gradient theory of optimal flight paths. ARS Journal, 30(10):947-954.
[5b] Bryson, A. E. (1961). A gradient method for optimizing multi-stage allocation processes. In Proc. Harvard Univ. Symposium on digital computers and their applications.
[5c] Dreyfus, S. E. (1962). The numerical solution of variational problems. Journal of Mathematical Analysis and Applications, 5(1):30-45.
[6] P. J. Werbos. Applications of advances in nonlinear sensitivity analysis. In R. Drenick, F. Kozin, (eds): System Modeling and Optimization: Proc. IFIP, Springer, 1982. PDF. [First application of backpropagation [5, 7] to neural networks. Extending preliminary thoughts in his 1974 thesis.]
[7] J. Schmidhuber (AI Blog, 2014, updated 2020). Who invented backpropagation? More.
[8] Hochreiter, S. and Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8):1735-1780. Based on TR FKI-207-95, TUM (1995). More.
[9] F. A. Gers, J. Schmidhuber, F. Cummins. Learning to Forget: Continual Prediction with LSTM. Neural Computation, 12(10):2451-2471, 2000. PDF. [The "vanilla LSTM architecture" with forget gates that everybody is using today, e.g., in Google's Tensorflow.]
[10] Graves, A., Fernandez, S., Gomez, F. J., and Schmidhuber, J. (2006). Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural nets. Proc. ICML'06, pp. 369-376.
[10a] A. Graves, M. Liwicki, S. Fernandez, R. Bertolami, H. Bunke, J. Schmidhuber. A Novel Connectionist System for Improved Unconstrained Handwriting Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 5, 2009.
[11a] Srivastava, R. K., Greff, K., Schmidhuber, J. Highway networks. Preprints arXiv:1505.00387 (May 2015) and arXiv:1507.06228 (Jul 2015). Also at NIPS'2015. The first working very deep feedforward nets with over 100 layers. Let g, t, h, denote non-linear differentiable functions. Each non-input layer of a highway net computes g(x)x + t(x)h(x), where x is the data from the previous layer. (Like LSTM [8] with forget gates [9] for RNNs.) The later ResNets [12] are Highway Nets whose gates are always open, that is, g(x)=t(x)=const=1. Highway Nets perform roughly as well as ResNets on ImageNet [11c]. Highway layers are also often used for natural language processing, where the simpler residual layers do not work as well [11c]. More.]
[11b] R. K. Srivastava, K. Greff, J. Schmidhuber. Highway networks. Presentation at the Deep Learning Workshop, ICML'15, July 10-11, 2015. Link.
[11c] K. Greff, R. K. Srivastava, J. Schmidhuber. Highway and Residual Networks learn Unrolled Iterative Estimation. Preprint arxiv:1612.07771 (2016). Also at ICLR 2017.
[11d] J. Schmidhuber (AI Blog, 2015): Overview of Highway Networks: First working really deep feedforward neural networks with over 100 layers. (Updated 2025 for 10-year anniversary.)
 [12] He, K., Zhang,
X., Ren, S., Sun, J. Deep residual learning for image recognition. Preprint arXiv:1512.03385 (Dec 2015). Residual Nets [12] are Highway Nets [11] whose gates are always open, with
g(x)=1 (a typical Highway Net initialisation) and t(x)=1.
[12] He, K., Zhang,
X., Ren, S., Sun, J. Deep residual learning for image recognition. Preprint arXiv:1512.03385 (Dec 2015). Residual Nets [12] are Highway Nets [11] whose gates are always open, with
g(x)=1 (a typical Highway Net initialisation) and t(x)=1.
[13a] K. Fukushima: Neural network model for a mechanism of pattern recognition unaffected by shift in position—Neocognitron. Trans. IECE, vol. J62-A, no. 10, pp. 658-665, 1979. [The first deep convolutional neural network architecture, with alternating convolutional layers and downsampling layers. In Japanese. English version: [13b]. More in Scholarpedia.]
[13b] K. Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4): 193-202, 1980. Scholarpedia.
[13c] A. Waibel. Phoneme Recognition Using Time-Delay Neural Networks. Meeting of IEICE, Tokyo, Japan, 1987. [First application of backpropagation [5] and weight-sharing to a 1D convolutional network.]
[13d] W. Zhang, J. Tanida, K. Itoh, Y. Ichioka. Shift-invariant pattern recognition neural network and its optical architecture. Proc. Annual Conference of the Japan Society of Applied Physics, 1988. First backpropagation-trained 2D CNN.
[13e] A. Waibel, T. Hanazawa, G. Hinton, K. Shikano and K. J. Lang. Phoneme recognition using time-delay neural networks. IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 37, no. 3, pp. 328-339, March 1989.
[13f] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, L. D. Jackel: Backpropagation Applied to Handwritten Zip Code Recognition, Neural Computation, 1(4):541-551, 1989.
[13g] Weng, J., Ahuja, N., and Huang, T. S. (1993). Learning recognition and segmentation of 3-D objects from 2-D images. Proc. 4th Intl. Conf. Computer Vision, Berlin, Germany, pp. 121-128.
[14] Baird, H. (1990). Document image defect models. In Proc. IAPR Workshop on Syntactic and Structural Pattern Recognition, Murray Hill, NJ.
[16] M. A. Ranzato, Y. LeCun: A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images. Proc. ICDAR, 2007
[17] D. Scherer, A. Mueller, S. Behnke. Evaluation of pooling operations in convolutional architectures for object recognition. In Proc. ICANN 2010.
[18a] Ciresan, D. C., Meier, U., Gambardella, L. M., and Schmidhuber, J. (2010). Deep big simple neural nets for handwritten digit recognition. Neural Computation, 22(12):3207-3220.
[18a+] J. Schmidhuber (AI Blog, Sep 2020). 10-year anniversary of supervised deep learning breakthrough (2010). No unsupervised pre-training. The rest is history
[18a++] J. Schmidhuber (AI Blog, 2025). 2010: Breakthrough of end-to-end deep learning on GPUs (no layer-by-layer training, no unsupervised pre-training). The rest is history.. By 2010, when compute was 1000 times more expensive than in 2025, both our feedforward NNs and our earlier recurrent NNs were able to beat all competing algorithms on important problems of that time. This deep learning revolution quickly spread from Europe to North America and Asia. The rest is history.
[18b] D. C. Ciresan, U. Meier, J. Masci, L. M. Gambardella, J. Schmidhuber. Flexible, High Performance Convolutional Neural Networks for Image Classification. International Joint Conference on Artificial Intelligence (IJCAI-2011, Barcelona), 2011. [DanNet: Speeding up deep CNNs on GPU by a factor of 60. Basis of all our computer vision contest winners since 2011.]
[18c] D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber. A Committee of Neural Networks for Traffic Sign Classification. International Joint Conference on Neural Networks (IJCNN-2011, San Francisco), 2011.
[18c+] D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber. Multi-Column Deep Neural Network for Traffic Sign Classification. Neural Networks 32: 333-338, 2012. PDF of preprint.
[18d] Results of 2011 IJCNN traffic sign recognition contest
[18e] Results of 2011 ICDAR Chinese handwriting recognition competition: WWW site, PDF.
[18f] Ciresan, D. C., Meier, U., and Schmidhuber, J. (2012c). Multi-column deep neural networks for image classification. Proc. CVPR, July 2012. Long preprint arXiv:1202.2745v1 [cs.CV], February 2012.
[18g] Reddit/ML, 2019. DanNet, the CUDA CNN of Dan Ciresan in J. Schmidhuber's team, won 4 image recognition challenges prior to AlexNet.
[19] A. Krizhevsky, I. Sutskever, G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. NIPS 25, MIT Press, December 2012.
[19a] J. Schmidhuber (2020). Critique of 2018 Turing Award for deep learning.
[20a] Results of 2012 ICPR cancer detection contest
[20b] Results of 2013 MICCAI Grand Challenge (cancer detection)
[20c] D. C. Ciresan, A. Giusti, L. M. Gambardella, J. Schmidhuber. Mitosis Detection in Breast Cancer Histology Images using Deep Neural Networks. MICCAI 2013.
[20d] D. Ciresan, A. Giusti, L. Gambardella, J. Schmidhuber. Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images. NIPS 2012, Lake Tahoe, 2012.
[20d+] I. Arganda-Carreras, S. C. Turaga, D. R. Berger, D. Ciresan, A. Giusti, L. M. Gambardella, J. Schmidhuber, D. Laptev, S. Dwivedi, J. M. Buhmann, T. Liu, M. Seyedhosseini, T. Tasdizen, L. Kamentsky, R. Burget, V. Uher, X. Tan, C. Sun, T. Pham, E. Bas, M. G. Uzunbas, A. Cardona, J. Schindelin, H. S. Seung. Crowdsourcing the creation of image segmentation algorithms for connectomics. Front. Neuroanatomy, November 2015.
 [20e] J. Masci,
A. Giusti, D. Ciresan, G. Fricout, J. Schmidhuber. A Fast Learning Algorithm for Image Segmentation with Max-Pooling Convolutional Networks. ICIP 2013. Preprint arXiv:1302.1690.
[20e] J. Masci,
A. Giusti, D. Ciresan, G. Fricout, J. Schmidhuber. A Fast Learning Algorithm for Image Segmentation with Max-Pooling Convolutional Networks. ICIP 2013. Preprint arXiv:1302.1690.
[21] Ji, S., Xu, W., Yang, M., and Yu, K. (2013). 3D convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1):221-231.
 [22] Schmidhuber, J. (2015).
Deep learning in neural networks: An overview. Neural Networks, 61, 85-117.
More.
Short version at
Scholarpedia.
[22] Schmidhuber, J. (2015).
Deep learning in neural networks: An overview. Neural Networks, 61, 85-117.
More.
Short version at
Scholarpedia.
[23] M. Stollenga, W. Byeon, M. Liwicki, J. Schmidhuber. Parallel Multi-Dimensional LSTM, with Application to Fast Biomedical Volumetric Image Segmentation. NIPS 2015; arxiv:1506.07452.
[24] J. Schmidhuber (AI Blog, 2019). Deep Learning: Our Miraculous Year 1990-1991. See also arxiv:2005.05744.
[25] J. Schmidhuber (AI Blog, 2020). The 2010s: Our Decade of Deep Learning / Outlook on the 2020s.
[26] K. Simonyan, A. Zisserman. Very deep convolutional networks for large-scale image recognition. Preprint arXiv:1409.1556 (2014).
[27] J. Schmidhuber. A Nobel Prize for Plagiarism. Technical Report IDSIA-24-24. Sadly, the Nobel Prize in Physics 2024 for Hopfield & Hinton is a Nobel Prize for plagiarism. They republished methodologies developed in Ukraine and Japan by Ivakhnenko and Amari in the 1960s & 1970s, as well as other techniques, without citing the original papers. Even in later surveys, they didn't credit the original inventors (thus turning what may have been unintentional plagiarism into a deliberate form). None of the important algorithms for modern Artificial Intelligence were created by Hopfield & Hinton. See also popular tweet1, tweet2, and LinkedIn post.
[28] J. Schmidhuber (AI Blog, 2023). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23, Swiss AI Lab IDSIA, 14 Dec 2023. The piece is aimed at people who are not aware of the numerous AI priority disputes, but are willing to check the facts (see tweet).
[29] J. Schmidhuber (AI Blog, 2021, updated 2025). The most cited neural networks all build on work done in my labs: 1. Long Short-Term Memory (LSTM), the most cited AI of the 20th century. 2. ResNet (open-gated Highway Net), the most cited AI of the 21st century. 3. AlexNet & VGG Net (the similar but earlier DanNet of 2011 won 4 image recognition challenges before them). 4. GAN (an instance of Adversarial Artificial Curiosity of 1990). 5. Transformer variants (unnormalised linear Transformers are formally equivalent to the Fast Weight Programmers of 1991). Foundations of Generative AI were published in 1991: the principles of GANs (now used for deepfakes), Transformers (the T in ChatGPT), Pre-training for deep NNs (the P in ChatGPT), NN distillation, and the famous DeepSeek—see the tweet.
[30] J. Schmidhuber (AI Blog, 2022). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, IDSIA, Lugano, Switzerland, 2022. Preprint arXiv:2212.11279. Tweet of 2022.
Fibonacci web design © Jürgen Schmidhuber. Click here for the old version of this page before its update for DanNet's 10-year anniversary 2021.