



Nächste Seite: Zielverfolgung
Aufwärts: Experimente zur adaptiven räumlichen
Vorherige Seite: Ein Netz für mehrere
Inhalt
Es wurden zwei zusätzliche logistische Ausgabeknoten für 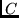 eingeführt.
Sie waren für Fokusrotationen in der Bildebene (um das Fokuszentrum)
zuständig. Dabei wurde die Aktivation des ersten zusätzlichen
Ausgabeknotens zu jedem Zeitschritt durch eine einfache
Multiplikationsoperation
in den Bereich zwischen 0 und 50
Winkelgraden transformiert,
die Aktivation des zweiten zusätzlichen
Ausgabeknotens in den Bereich zwischen -50 und 0 Winkelgraden.
Der Betrag der Rotation des Fokus um sein Zentrum ergab sich schließlich
durch Addition der beiden Werte.
Natürlich erhöhte sich auch die Zahl der Eingabeknoten
von
eingeführt.
Sie waren für Fokusrotationen in der Bildebene (um das Fokuszentrum)
zuständig. Dabei wurde die Aktivation des ersten zusätzlichen
Ausgabeknotens zu jedem Zeitschritt durch eine einfache
Multiplikationsoperation
in den Bereich zwischen 0 und 50
Winkelgraden transformiert,
die Aktivation des zweiten zusätzlichen
Ausgabeknotens in den Bereich zwischen -50 und 0 Winkelgraden.
Der Betrag der Rotation des Fokus um sein Zentrum ergab sich schließlich
durch Addition der beiden Werte.
Natürlich erhöhte sich auch die Zahl der Eingabeknoten
von 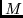 um 2.
um 2.
Das Erlernen korrekter Fokustrajektorien unter Einschluß
von Rotationen erwies sich erwartungsgemäß als langwieriger als
das Erlernen reiner Translationssequenzen. Bei den Experimenten
mit der sequentiellen Version des Algorithmus
erwiesen sich 100.000 Trainingsbeispiele für und 20.000
Trainingstrajektorien
für als zweckmäßig. (Die sonstigen Parameter und
Details wurden von
den reinen Translationsexperimenten übernommen.)
In den Abbildungen 7.4 bis 7.7 wird die Rotation des Fokus' zu einem
bestimmten Zeitschritt einer Trajektorie jeweils
durch die Richtung des abgebildeten Pfeils symbolisiert.
Nachdem 's Training abgeschlossen war,
bestand die Aufgabe für bei jedem Versuch darin, eine
Trajektorie zu erzeugen, die das Zentrum des Fokus (dessen
Position und Rotation zu Beginn einer Trajektorie
zufällig gewählt wurden) in
sequentieller Weise zu dem jeweils vorgegebenen Detail des
Testobjektes
zu führen hatte, wobei der Rotation des Objektes durch entsprechende
Retinarotation Rechnung
getragen werden mußte.
Die Experimente zeigten wiederum, daß das
System in der Lage war,
unter der Voraussetzung der teilweisen Überlappung des Objektes
durch die rezeptiven Felder zu Beginn einer Trajektorie ohne
Lehrer korrekte Sequenzen von Fokusbewegungen zu erlernen,
obwohl das Modellnetzwerk häufig falsche Voraussagen
lieferte [64].
Abbildung:
Einer für die Experimente typischen visuellen Szene (schwarzes
Objekt auf weißem Hintergrund) sind
die rezeptiven Felder der sich auf der beweglichen `Retina'
befindlichen Eingabeknoten überlagert.
|
Abbildung:
Translationen:
Der Fokus findet nach der Trainingsphase
seinen Weg von verschiedenen Teilen der
Pixelebene zu seinem
Ziel, dem Zentrum des Kreuzungspunktes in der Ziffer `4'.
Kein Lehrer sagte ihm, wie das zu machen sei!
Man beachte, daß der Fokus typischerweise nicht den
kürzesten Weg nimmt, sondern eine Vorliebe für
Kanten entwickelt.
|
Abbildung:
Ein Netzwerk für mehrere Ziele: Durch eine zusätzliche
stationäre Eingabe für das Steuernetzwerk
können verschiedene Ziele in ein und derselben
Szene definiert werden.
|
Abbildung 7.4:
Ein Experiment mit Rotationen und Translationen:
Nach dem Training findet der Fokus Wege von Startpunkten in
der Umgebung des Objekts zu seinem
Ziel.
|
Abbildung:
Die Pixelebene ist durch
Pseudo-Zufallsrauschen verunreinigt.
Der Fokus fährt dennoch an das Ziel heran.
|
Abbildung:
Auch bei diesem aus einem Ball und einem Kreuz komponierten Objekt
entdeckte das System eine erfolgreiche Strategie zur Lösung seiner
Aufgabe: Erst versuchte der Fokus, den Rand des Objektes zu finden
und sich in eine Art Normalstellung zu begeben. Dann rutschte
er solange am Rand des Balles entlang, bis er den Auswuchs
des Kreuzes wahrnehmen konnte. Von diesem Punkt an lief er mehr oder
weniger geradlinig zum Ziel, dem Zentrum des Kreuzes. Man beachte
erneut, daß kein überwachender Lehrer zu irgendeinem Zeitpunkt
dem Fokus mitteilte, daß dies eine gute Strategie ist!
|
Abbildung:
Ein Werkstück aus der SIEMENS-Datenbank und zwei in der Umgebung
des Werkstücks beginnende Fokustrajektorien. Das Ziel befindet
sich im Inneren des Objektes.
|
Nächste Seite: Zielverfolgung
Aufwärts: Experimente zur adaptiven räumlichen
Vorherige Seite: Ein Netz für mehrere
Inhalt
Juergen Schmidhuber
2003-02-20
Related links in English: Recurrent neural networks - Subgoal learning - Reinforcement learning and POMDPs - Reinforcement learning economies - Selective attention
Deutsche Heimseite