



Nächste Seite: Zielerkennung mit Rotationen
Aufwärts: Experimente zur adaptiven räumlichen
Vorherige Seite: Zielerkennung ohne Rotationen
Inhalt
Indem man eine für die Dauer einer Trajektorie zeitinvariante
zusätzliche statische Eingabe für 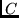 einführt, können
für ein und dasselbe Netzwerk während aufeinanderfolgender
Versuche verschiedene Zieldetails definiert werden.
Zu diesem Zweck muß die Anzahl der Eingabeknoten von verdoppelt
werden.
einführt, können
für ein und dasselbe Netzwerk während aufeinanderfolgender
Versuche verschiedene Zieldetails definiert werden.
Zu diesem Zweck muß die Anzahl der Eingabeknoten von verdoppelt
werden. 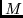 ändert sich nicht, es sagt nach wie vor lediglich
die zeitlich variierenden Eingaben von voraus.
ändert sich nicht, es sagt nach wie vor lediglich
die zeitlich variierenden Eingaben von voraus.
Solch ein erweitertes System
ist fähig zu lernen, denjenigen Teil der Szene zu finden, der
mit der zeitinvarianten Eingabe übereinstimmt
(siehe Abbildung 7.3).
Diese Möglichkeit ist bedeutsam für die später
anzusprechenden Subzielgeneratoren.
Juergen Schmidhuber
2003-02-20
Related links in English: Recurrent neural networks - Subgoal learning - Reinforcement learning and POMDPs - Reinforcement learning economies - Selective attention
Deutsche Heimseite