


Next: A.3. RELATION TO HINTON
Up: APPENDIX - THEORETICAL JUSTIFICATION
Previous: A.1. OVERFITTING ERROR
To find nets with flat outputs,
two conditions will be defined
to specify 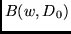 (see section 3).
The first condition ensures flatness.
The second condition enforces ``equal flatness'' in all
weight space directions.
In both cases, linear approximations will be made
(to be justified in [4]).
We are looking for weights (causing tolerable error) that
can be perturbed without causing significant
output changes.
Perturbing the weights
(see section 3).
The first condition ensures flatness.
The second condition enforces ``equal flatness'' in all
weight space directions.
In both cases, linear approximations will be made
(to be justified in [4]).
We are looking for weights (causing tolerable error) that
can be perturbed without causing significant
output changes.
Perturbing the weights 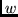 by
by
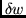 (with components
(with components 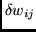 ),
we obtain
),
we obtain
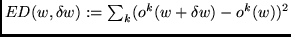 ,
where
,
where 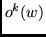 expresses
expresses 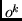 's
dependence on (in what follows,
however, often will be suppressed for
convenience).
Linear approximation (justified in [4])
gives us ``Flatness Condition 1'':
's
dependence on (in what follows,
however, often will be suppressed for
convenience).
Linear approximation (justified in [4])
gives us ``Flatness Condition 1'':
 |
|
|
(4) |
where
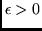 defines tolerable output changes within a box
and is small enough to allow for linear approximation
(it does not appear in 's gradient, see section 3).
defines tolerable output changes within a box
and is small enough to allow for linear approximation
(it does not appear in 's gradient, see section 3).
Many 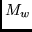 satisfy flatness condition 1.
To select a particular, very flat ,
the following
``Flatness Condition 2''
uses up degrees of freedom left by (4):
satisfy flatness condition 1.
To select a particular, very flat ,
the following
``Flatness Condition 2''
uses up degrees of freedom left by (4):
 |
|
|
(5) |
Flatness Condition 2
enforces equal ``directed errors''
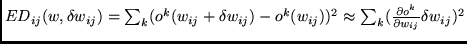 ,
where
,
where 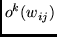 has the obvious meaning.
It can be shown (see [4]) that
with given box volume, we need
flatness condition 2 to minimize the expected description length of
the box center.
Flatness condition 2 influences
the algorithm as follows: (1) The algorithm prefers to
increase the 's of weights which
currently are not important to generate the target output.
(2) The algorithm enforces equal sensitivity of all
output units with respect to the weights.
Hence,
the algorithm tends to group hidden units
according to their relevance for groups of output units.
Flatness condition 2 is essential:
flatness condition 1 by itself
corresponds to nothing more but first order derivative reduction
(ordinary sensitivity reduction, e.g. []).
Linear approximation is justified by
the choice of
has the obvious meaning.
It can be shown (see [4]) that
with given box volume, we need
flatness condition 2 to minimize the expected description length of
the box center.
Flatness condition 2 influences
the algorithm as follows: (1) The algorithm prefers to
increase the 's of weights which
currently are not important to generate the target output.
(2) The algorithm enforces equal sensitivity of all
output units with respect to the weights.
Hence,
the algorithm tends to group hidden units
according to their relevance for groups of output units.
Flatness condition 2 is essential:
flatness condition 1 by itself
corresponds to nothing more but first order derivative reduction
(ordinary sensitivity reduction, e.g. []).
Linear approximation is justified by
the choice of  in equation (4).
in equation (4).
We first solve equation (5) for
 (fixing
(fixing 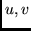 for all
for all 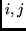 ).
Then we insert
).
Then we insert
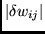 into equation
(4)
(replacing the second ``
into equation
(4)
(replacing the second ``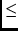 '' in (4) by ``
'' in (4) by ``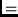 '').
This gives us an equation for
the
(which depend on
, but this is notationally suppressed):
'').
This gives us an equation for
the
(which depend on
, but this is notationally suppressed):
 |
(6) |
The
approximate
the 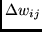 from section 2.
Thus,
from section 2.
Thus,
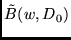 (see section 3) can be
approximated by
(see section 3) can be
approximated by
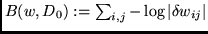 .
This immediately leads to the algorithm given by
equation (1).
.
This immediately leads to the algorithm given by
equation (1).
How can this approximation be justified?
The learning process itself enforces its validity
(see justification in [4]).
Initially, the conditions above are
valid only in a very small environment of
an ``initial'' acceptable minimum. But during search
for new acceptable minima with more associated box volume,
the corresponding environments are enlarged, which implies that
the absolute values of the entries in the Hessian decrease.
It can be shown (see [4]) that the
algorithm tends to suppress the following values:
(1) unit activations,
(2) first order activation derivatives,
(3) the sum of all contributions
of an arbitary unit activation to the net
output.
Since weights, inputs, activation functions,
and their first and second
order derivatives are bounded,
it can be shown (see [4]) that
the entries in the
Hessian decrease
where the corresponding
increase.
Next: A.3. RELATION TO HINTON
Up: APPENDIX - THEORETICAL JUSTIFICATION
Previous: A.1. OVERFITTING ERROR
Juergen Schmidhuber
2003-02-25
Back to Financial Forecasting page