This experimental case study will demonstrate that IS can successfully learn in a changing environment where the tasks to be solved become more and more difficult over time (inductive transfer).
Task sequence. Our system is exposed to a sequence of more and more
complex function approximation problems. The functions to be learned
are
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
Trials. The system's single life is decomposable into ![]() successive trials
successive trials ![]() ,
, ![]() , ...,
, ..., ![]() (but the learner has no a priori concept of a trial). The
(but the learner has no a priori concept of a trial). The ![]() -th trial lasts from discrete
time step
-th trial lasts from discrete
time step ![]() until discrete time step
until discrete time step ![]() , where
, where ![]() (system birth) and
(system birth) and ![]() (system death). In a given trial
(system death). In a given trial
![]() we first select a function
we first select a function
![]() .
As the trial number increases, so does the probability of selecting a
more complex function. In early trials the focus is on
.
As the trial number increases, so does the probability of selecting a
more complex function. In early trials the focus is on ![]() . In late
trials the focus is on
. In late
trials the focus is on ![]() . In between there is a gradual shift in
task difficulty: using a function pointer
. In between there is a gradual shift in
task difficulty: using a function pointer ![]() (initially 1) and an
integer counter
(initially 1) and an
integer counter ![]() (initially 100), in trial
(initially 100), in trial ![]() we select
we select
![]() with probability
with probability ![]() , and
, and
![]() with
probability
with
probability
![]() . If the reward acceleration during
the most recent two trials exceeds a certain threshold (0.05), then
. If the reward acceleration during
the most recent two trials exceeds a certain threshold (0.05), then ![]() is decreased by 1. If
is decreased by 1. If ![]() becomes 0 then
becomes 0 then ![]() is increased by 1,
and
is increased by 1,
and ![]() is reset to 100. This is repeated until
is reset to 100. This is repeated until
![]() . From
then on,
. From
then on, ![]() is always selected.
is always selected.
Once ![]() is selected, randomly generated real values
is selected, randomly generated real values ![]() ,
, ![]() and
and
![]() are put into work cells 0, 1, 2, respectively. The contents of an
arbitrarily chosen work cell (we always use cell 6) are interpreted as
the system's response. If
are put into work cells 0, 1, 2, respectively. The contents of an
arbitrarily chosen work cell (we always use cell 6) are interpreted as
the system's response. If ![]() fulfills the condition
fulfills the condition
![]() , then the trial ends and the current reward becomes
, then the trial ends and the current reward becomes
![]() ; otherwise the current reward is 0.0.
; otherwise the current reward is 0.0.
Instructions. Instruction sequences can be composed from the
following primitive instructions (compare section 4.1):
Add(![]() ), Sub(
), Sub(![]() ),
Mul(
),
Mul(![]() ),
Mov(
),
Mov(![]() ), IncProb(
), IncProb(![]() ),
EndSelfMod(
),
EndSelfMod(![]() ), JumpHome().
Each instruction occupies 4 successive program cells (some of them unused
if the instruction has less than 3 parameters). We use
), JumpHome().
Each instruction occupies 4 successive program cells (some of them unused
if the instruction has less than 3 parameters). We use ![]() .
.
Evaluation Condition. SSA is called after each 5th consecutive
non-zero reward signal after the end of each SMS, i.e., we set
![]() .
.
Huge search space. Given the primitives above, random search would
require about ![]() trials on average to find a solution for
trials on average to find a solution for ![]() -- the search space is huge. The gradual shift in task complexity,
however, helps IS to learn
-- the search space is huge. The gradual shift in task complexity,
however, helps IS to learn ![]() much faster, as will be seen below.
much faster, as will be seen below.
Results. After about
![]() instruction cycles
(ca.
instruction cycles
(ca. ![]() trials), the system is able to compute
trials), the system is able to compute ![]() almost
perfectly, given arbitrary real-valued inputs. The corresponding
speed-up factor over (infeasible) random or exhaustive search is about
almost
perfectly, given arbitrary real-valued inputs. The corresponding
speed-up factor over (infeasible) random or exhaustive search is about
![]() -- compare paragraph ``Huge search space'' above. The solution
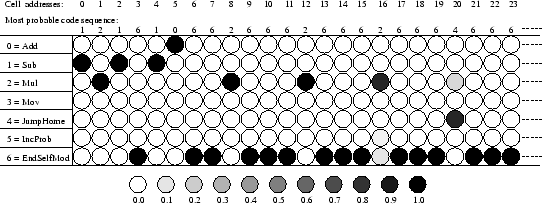
(see Figure 5) involves 21 strongly modified probability
distributions of the policy (after learning, the correct instructions
had extreme probability values). At the end, the most probable code is
given by the following integer sequence:
-- compare paragraph ``Huge search space'' above. The solution
(see Figure 5) involves 21 strongly modified probability
distributions of the policy (after learning, the correct instructions
had extreme probability values). At the end, the most probable code is
given by the following integer sequence:
1 2 1 6 1 0 6 6 2 6
6 6 2 6 6 6 2 6 6 6 4 ![]()
![]()
![]() ...
...
The corresponding ``program'' and the (very high)
probabilities of its instructions and parameters
are shown in Table 4.
Evolution of self-modification frequencies. During its life
the system generates a lot of self-modifications to compute the
strongly modified policy. This includes changes of the probabilities of
self-modifications. It is quite interesting (and also quite difficult) to
find out to which extent the system uses self-modifying instructions to
learn how to use self-modifying instructions. Figure 6 gives
a vague idea of what is going on by showing a typical plot of the frequency
of IncProb instructions during system life (sampled at intervals of
![]() basic cycles). Soon after its birth, the system found it useful to
dramatically increase the frequency of IncProb; near its death (when
there was nothing more to learn) it significantly reduced this frequency.
This is reminiscent of Schwefel's work (1974) on
self-adjusting mutation rates. One major novelty is
the adaptive, highly non-uniform distribution of self-modifications
on ``promising'' individual policy components.
basic cycles). Soon after its birth, the system found it useful to
dramatically increase the frequency of IncProb; near its death (when
there was nothing more to learn) it significantly reduced this frequency.
This is reminiscent of Schwefel's work (1974) on
self-adjusting mutation rates. One major novelty is
the adaptive, highly non-uniform distribution of self-modifications
on ``promising'' individual policy components.
Stack evolution. The temporary ups and downs of the stack reflect
that as the tasks change, the system selectively keeps still useful
old modifications (corresponding to information conveyed by previous
tasks that is still valuable for solving the current task), but deletes
modifications that are too much tailored to previous tasks. In the end,
there are only about 200 stack entries corresponding to only 200 valid probability modifications - this is a small number compared to
the about  self-modifications executed during system life.
self-modifications executed during system life.