



Nächste Seite: EXPERIMENTE
Aufwärts: WELTMODELLBAUER
Vorherige Seite: ARCHITEKTUR
Inhalt
Durch Präsentation von Kombinationen möglicher Zustands-
und Aktionsvektoren sowie durch Beobachtung der
entsprechenden Umgebungseffekte
wird zunächst 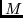 durch konventionelles
BP (siehe Kapitel 1) adjustiert. Nach jeder Präsentation
des Trainingsensembles ändert sich
dabei jedes Gewicht
durch konventionelles
BP (siehe Kapitel 1) adjustiert. Nach jeder Präsentation
des Trainingsensembles ändert sich
dabei jedes Gewicht 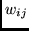 in gemäß
in gemäß
 |
(4.3) |
Nach Abschluß von 's Trainingsphase werden
's Gewichte `eingefroren'. dient ab jetzt als
starre Approximation von 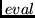 zur Berechnung von Fehlergradienten
für
zur Berechnung von Fehlergradienten
für 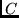 .
Jedes Gewicht in wird nun gemäß
.
Jedes Gewicht in wird nun gemäß
 |
(4.4) |
geändert, wobei
gilt.
Zu diesem Zweck berechnen wir für alle 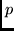 zunächst durch
konventionelles BP in die Werte
zunächst durch
konventionelles BP in die Werte
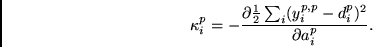 |
(4.5) |
Falls  einen Ausgabeknoten von bezeichnet, so ist
einen Ausgabeknoten von bezeichnet, so ist
Steht hingegen für einen versteckten Knoten der 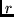 -ten Lage von ,
so gilt
-ten Lage von ,
so gilt
Erweiterung auf dynamische Umgebungen. Sind sowohl
als auch rekurrent, lassen sich alle drei in Kapitel
2 vorgestellten Algorithmen auf bzw. auf die ebenfalls
rekurrente Kombination von und anwenden.
Derartige Erweiterungen obigen Prinzips auf zyklische Netzwerke in
nichtstationären Umgebungen mit externer Rückkopplung4.2 wurden
in
[96],
[98], und
[94]
beschrieben.
Unterabschnitte
Nächste Seite: EXPERIMENTE
Aufwärts: WELTMODELLBAUER
Vorherige Seite: ARCHITEKTUR
Inhalt
Juergen Schmidhuber
2003-02-20
Related links in English: Recurrent networks - Fast weights - Subgoal learning - Reinforcement learning and POMDPs - Unsupervised learning and ICA - Metalearning and learning to learn
Deutsche Heimseite