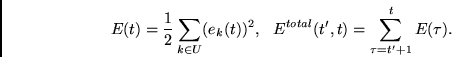 |
(2.4) |
Bei einer Trainingssequenz mit ![]() Zeitschritten
wollen wir durch einen geeigneten Lernalgorithmus
Zeitschritten
wollen wir durch einen geeigneten Lernalgorithmus
| (2.5) |
Die drei folgenden Lernalgorithmen beruhen
auf dem Prinzip des einfachen Gradientenabstiegs.
Die Trainingssequenz wird dabei wiederholt präsentiert.
Nach jeder Präsentation bestimmt man
für jedes Gewicht ![]() eine Gewichtsänderung
eine Gewichtsänderung
| (2.6) |
Wie schon verschiedentlich erwähnt, kennt die Numerik trickreichere und häufig effizientere Standardverfahren zur Ausnützung der einmal gewonnenen Gradienteninformation (z.B. konjugierte Gradientenverfahren, `line search', Methoden zweiter Ordnung, effiziente Approximationen von Methoden zweiter Ordnung, etc., siehe e.g. [24][89][67][127]). Derartige Modifizierungen sind allerdings orthogonal zum Ziel dieser Arbeit - wir werden daher in den Experimenten stets einfachen Gradientenabstieg verwenden. Auch zur Behandlung lokaler Minima der Zielfunktion machen wir nur von der einfachsten Lösung Gebrauch, welche darin besteht, ausgehend von verschiedenen zufällig gewählten Gewichtsmatrizen solange ein wiederholtes, lokales, gradientenbasiertes Suchen im Raum der möglichen Gewichtsmatrizen durchzuführen, bis ein Programm mit zufriedenstellender Performanz gefunden worden ist.
In der Regel hat man es mit vielen Trainingssequenzen zu tun - in diesem Fall ergibt sich die Gewichtsänderung für jedes Gewicht bei jeder Iteration des Gradientenabstiegsprozesses zur Summe der Beiträge, die man durch einen der nachfolgenden gradientenbasierten Algorithmen für jede einzelne Trainingssequenz erhält. Gerechtfertigt ist dies durch den Hinweis auf die Tatsache, daß der Gradient der Summe aller Fehler gleich der Summe der entsprechenden Gradienten ist.