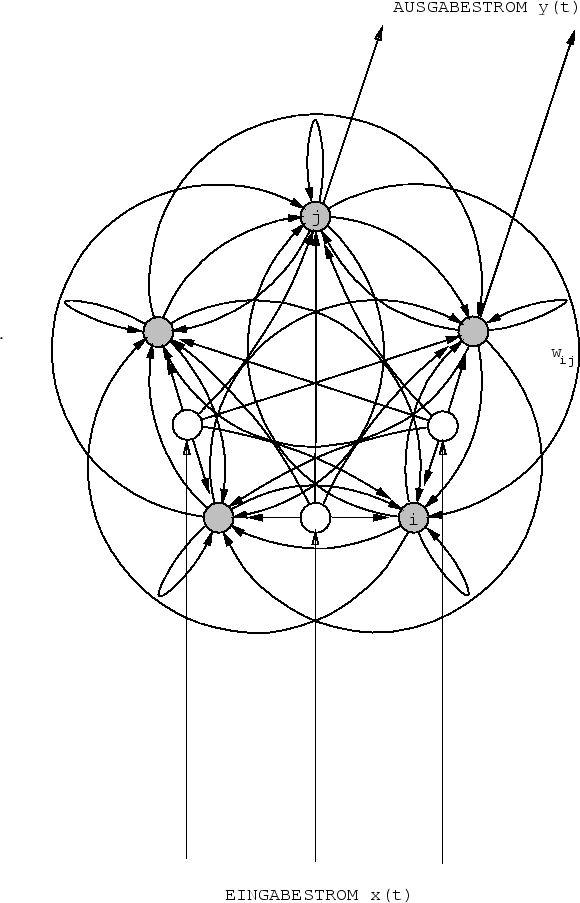
 |
Bei der Wahl formaler Symbole halten wir uns relativ eng an die Notation von
Williams und Peng [149].
Um Indizes zu sparen,
betrachten wir der Einfachheit halber eine einzelne, ![]() diskrete Zeitschritte umfassende geordnete Sequenz
von vektorwertigen Eingabemustern. Zu jedem Zeitpunkt
diskrete Zeitschritte umfassende geordnete Sequenz
von vektorwertigen Eingabemustern. Zu jedem Zeitpunkt ![]() ist der reellwertige Vektor der Aktivationen der Eingabeknoten
gleich dem
ist der reellwertige Vektor der Aktivationen der Eingabeknoten
gleich dem ![]() -ten Eingabemuster.
Alle Knoten seien in beliebiger Weise eindeutig durchnumeriert.
-ten Eingabemuster.
Alle Knoten seien in beliebiger Weise eindeutig durchnumeriert.
![]() bezeichne die Menge von Indizes
bezeichne die Menge von Indizes ![]() mit der Eigenschaft, daß
mit der Eigenschaft, daß
![]() die Ausgabe des internen Knotens mit der Nummer
die Ausgabe des internen Knotens mit der Nummer ![]() zum Zeitpunkt
zum Zeitpunkt ![]() ist.
ist.
![]() stehe für die Menge von Indizes
stehe für die Menge von Indizes ![]() mit der Eigenschaft, daß
mit der Eigenschaft, daß
![]() die Eingabe des Eingabeknotens mit der Nummer
die Eingabe des Eingabeknotens mit der Nummer ![]() zum Zeitpunkt
zum Zeitpunkt ![]() darstellt. Es sei
darstellt. Es sei
Die Ablaufdynamik
definieren wir
für ![]() wie folgt:
wie folgt:
| (2.1) |
| (2.2) |
| (2.3) |
Turingäquivalenz. Obige zyklische Verbindungsstruktur weist zwar Ähnlichkeiten zur Topologie von Hopfieldnetzen [38], Boltzmannmaschinen [36], Schürmann-Netzen [123], und BP-Equilibriumsnetzen ([2], [81], [70], [71]) auf. Diese Ansätze sind allerdings nur für stationären Eingaben gedacht und für das Erlernen von Sequenzen ungeeignet - die Rekurrenz im Netz dient bei obigen Referenzen lediglich zur Ermittlung eines Aktivationsequilibriums. Die Aktivierungsdynamik (2.1) hingegen erlaubt zeitlich veränderliche Eingaben. Dieser wesentliche Unterschied bildet die Grundlage für ein System, das im Prinzip die Mächtigkeit einer Turingmaschine besitzt - und zwar im selben Sinne, in dem jeder konventionelle Rechner einer Turingmaschine gleichkommt. Dies ist unschwer einzusehen: Mit entsprechenden Gewichten kann man in einem hinreichend großen Netzwerk jede Boolesche Funktion und damit auch jede Kombination Boolescher Funktionen verdrahten. Damit läßt sich bei geeigneter Gewichtsbelegung die sequentielle Arbeitsweise eines herkömmlichen seriell arbeitenden Digitalrechners exakt emulieren - das einzige Hemmnis auf dem Weg zur `wahren' Turingäquivalenz ist, wie stets, der endliche Speicherplatz.
Natürlich hat dieses Argument nur theoretische Bedeutung: Niemand wollte ernsthaft mittels eines zyklischen Netzes einen gewöhnlichen Digitalrechner nachbauen2.1. Vorteile erhofft man sich ja gerade von der Möglichkeit zumindest teilweise paralleler Informationsverarbeitung. Um unter den vielen Programmen, die ein zyklisches neuronales Netz ausführen könnte, bestimmte zweckmäßige Programme (= Gewichtsbelegungen) auszuzeichnen, definieren wir nun ein geeignetes