



Nächste Seite: UNÜBERWACHTE GESCHICHTSKOMPRESSION
Aufwärts: APPENDIX
Vorherige Seite: ZUR VERMUTUNG 6.4.1
Inhalt
Peter Dayan und Richard Zemel wiesen
in persönlicher Kommunikation
darauf hin, daß das Verfahren
aus Abschnitt 6.3.6 und Vorhersagbarkeitsminimerung gemäß
Abschnitt 6.4 für
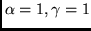 Kraft
folgender Argumentation im wesentlichen
äquivalent sind:
Kraft
folgender Argumentation im wesentlichen
äquivalent sind:
(6.11) läßt sich umschreiben als
![\begin{displaymath}
-2\sum_{i,p} P(x^p) (y_i^p - \bar{y_i})\left(E\left[y_i\vert\left\{y_j^p, j \neq
i\right\}\right]-\bar{y_i}\right).
\end{displaymath}](img664.png) |
(6.19) |
Da
ist die dritte Zeile von (6.15) gleich
Wie nun von Alex Pouget bemerkt wurde6.4, gilt
![\begin{displaymath}
= \sum_{i,p} P(x^p) \left(E\left[y_i\vert\left\{y_j^p, j \neq
i\right\}\right]-\bar{y_i}\right)^2
\end{displaymath}](img672.png) |
(6.20) |
und damit auch
was zu zeigen war.
Juergen Schmidhuber
2003-02-20
Related links in English: Recurrent networks - Fast weights - Subgoal learning - Reinforcement learning and POMDPs - Unsupervised learning and ICA - Metalearning and learning to learn
Deutsche Heimseite