


Next: Remedies
Up: Gradient Flow in Recurrent
Previous: Weak upper bound for
Dilemma: Avoiding gradient decay prevents long-term latching
In Bengio et al.'s paper [6], the analysis of the
problem of gradient
decays is generalized to parameterized dynamical systems (hence
including second order and other recurrent architectures).
The main theorem shows that a sufficient condition to obtain gradient
decay is also a necessary condition for the system to robustly store
discrete state information for the long-term.
In other words, when the weights
and the state trajectory are such that the network can ``latch'' on
information in its hidden units (i.e., represent long-term
dependencies), the problem of gradient decay is obtained. When the
long-term gradients decay exponentially, it is very difficult to learn
such long-term dependencies because the total gradient is the sum of
long-term and short-term influences and the short-term influences then
completely dominate the gradient.
This result is based on a decomposition of the state-space of hidden
units in two types of regions: one where gradients decay and one where
it is not possible to robustly latch information.
Let  denote the
denote the 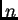 -dimensional state vector at time
-dimensional state vector at time 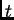 (for example,
the vector
(for example,
the vector
![$[net_1(t),\dots,net_n(t)]$](img81.png) when considering a standard first-order
recurrent network) and let
when considering a standard first-order
recurrent network) and let
 be the map from the
state at time
be the map from the
state at time  to for the autonomous (without inputs)
dynamical system. The above decomposition is expressed in terms of the
condition
to for the autonomous (without inputs)
dynamical system. The above decomposition is expressed in terms of the
condition
 (no robust latching possible) or
(no robust latching possible) or
 (gradient
decay), where
(gradient
decay), where
 is the norm of the Jacobian (matrix of partial
derivatives) of the map
is the norm of the Jacobian (matrix of partial
derivatives) of the map 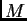 . The analysis focuses on the basins of
attraction of attractors of in the domain of (or manifolds
within that domain). In particular, the analysis is concerned with
so-called hyperbolic attractors, which are locally stable (but need
not be fixed points) and where the eigenvalues of
. The analysis focuses on the basins of
attraction of attractors of in the domain of (or manifolds
within that domain). In particular, the analysis is concerned with
so-called hyperbolic attractors, which are locally stable (but need
not be fixed points) and where the eigenvalues of  are less than 1
in absolute value. If the state (or a function of it) remains within
a certain region of space (versus another region) even in the presence
of perturbations (such as noise in the inputs) then it is possible
to store at least one bit of information for arbitrary durations.
are less than 1
in absolute value. If the state (or a function of it) remains within
a certain region of space (versus another region) even in the presence
of perturbations (such as noise in the inputs) then it is possible
to store at least one bit of information for arbitrary durations.
Figure 1:
Robust latching. For simplicity a fixed-point attractor
 is shown. The shadow region is the basin of
attraction. The dark shadow region is the subset where
is shown. The shadow region is the basin of
attraction. The dark shadow region is the subset where  and robust latch occurs. See text for details.
and robust latch occurs. See text for details.
|
In regions where
it can be shown that arbitrarily small
perturbations (for example due to the inputs) can eventually kick the
state out of a basin of attraction [18] (see the sample
trajectory on the right of Figure 1).
In regions where
there is a level of perturbation (depending on
) below which the state will remain in the basin of
attraction (and will gradually get closer to a certain volume around
the attractor -- see left of Figure 1). For
this reason we call this condition ``information
latching,'' since it allows to store discrete information for
arbitrary duration in the state variable .
Unfortunately, in the regions where
(where one can latch
information) one can also show that gradients decay. The argument
is similar to the one developed in the previous section. The
partial derivative of with respect to
with  is simply the product of the map derivatives between and :
is simply the product of the map derivatives between and :
When the norm of each of the factors on the right hand side is less than 1,
the left hand side converges exponentially fast to zero as  increases.
The effect of this decay of gradients can be made explicit as follows:
increases.
The effect of this decay of gradients can be made explicit as follows:
Hence for a term of the sum with , we have
This term tends to become very small in comparison to terms for
which 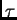 is close to .
This means that even though there might exist a change in
is close to .
This means that even though there might exist a change in 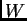 that
would allow to jump to another (better) basin of attraction,
the gradient of the cost with respect to does not
clearly reflect that possibility. The explanation is that
the effect of a small change in would be felt mostly on
the near past ( close to ).
that
would allow to jump to another (better) basin of attraction,
the gradient of the cost with respect to does not
clearly reflect that possibility. The explanation is that
the effect of a small change in would be felt mostly on
the near past ( close to ).
Next: Remedies
Up: Gradient Flow in Recurrent
Previous: Weak upper bound for
Juergen Schmidhuber
2003-02-19