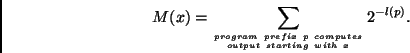How to predict the future from the past? To get a grip on this
fundamental question,
let us first introduce some notation. ![]() denotes the set of finite
sequences over the binary alphabet
denotes the set of finite
sequences over the binary alphabet ![]() ,
, ![]() the set of
infinite sequences over
the set of
infinite sequences over ![]() ,
, ![]() the empty string,
the empty string,
![]() .
. ![]() stand for strings in
stand for strings in ![]() .
If
.
If ![]() then
then ![]() is the concatenation of
is the concatenation of ![]() and
and ![]() (e.g.,
if
(e.g.,
if ![]() and
and ![]() then
then
![]() ). For
). For ![]() ,
,
![]() denotes the number of bits in
denotes the number of bits in ![]() , where
, where ![]() for
for
![]() ;
;
![]() .
. ![]() is the prefix of
is the prefix of ![]() consisting of the first
consisting of the first ![]() bits, if
bits, if ![]() , and
, and ![]() otherwise
(
otherwise
(
![]() ).
). ![]() denotes the logarithm with basis 2,
denotes the logarithm with basis 2, ![]() functions mapping integers to integers. We write
functions mapping integers to integers. We write ![]() if
there exist positive constants
if
there exist positive constants ![]() such that
such that
![]() for
all
for
all ![]() . For simplicity let us consider universal Turing Machines
(TMs) with input alphabet
. For simplicity let us consider universal Turing Machines
(TMs) with input alphabet ![]() and trinary output alphabet including the
symbols ``0'', ``1'', and `` '' (blank). For efficiency reasons,
the TMs should have several work tapes
to avoid potential quadratic slowdowns associated with 1-tape TMs.
The remainder of this paper refers assumes a fixed universal reference TM.
and trinary output alphabet including the
symbols ``0'', ``1'', and `` '' (blank). For efficiency reasons,
the TMs should have several work tapes
to avoid potential quadratic slowdowns associated with 1-tape TMs.
The remainder of this paper refers assumes a fixed universal reference TM.
Now suppose bitstring ![]() represents the data observed so far.
What is its most likely continuation
represents the data observed so far.
What is its most likely continuation
![]() ? Bayes' theorem yields
? Bayes' theorem yields
The next section will offer an alternative to the celebrated but noncomputable algorithmic simplicity measure or Solomonoff-Levin measure [24,29,25]. But let us first review Solomonoff's traditional approach.
Roughly fourty years ago Solomonoff started the theory of
universal optimal induction based on the apparently harmless
simplicity assumption that ![]() is computable [24].
While Equation (1) makes predictions of
the entire future, given the past,
Solomonoff [25] focuses just on the next
bit in a sequence. Although this provokes surprisingly nontrivial
problems associated with translating the bitwise approach to alphabets
other than the binary one -- only recently Hutter managed to do this
[8] -- it is sufficient for obtaining essential
insights. Given an observed bitstring
is computable [24].
While Equation (1) makes predictions of
the entire future, given the past,
Solomonoff [25] focuses just on the next
bit in a sequence. Although this provokes surprisingly nontrivial
problems associated with translating the bitwise approach to alphabets
other than the binary one -- only recently Hutter managed to do this
[8] -- it is sufficient for obtaining essential
insights. Given an observed bitstring ![]() , Solomonoff assumes the data are drawn
according to a recursive measure
, Solomonoff assumes the data are drawn
according to a recursive measure ![]() ; that is, there is a program for
a universal Turing machine that reads
; that is, there is a program for
a universal Turing machine that reads ![]() and
computes
and
computes ![]() and halts. He estimates the probability of the next bit
(assuming there will be one), using the remarkable, well-studied,
enumerable prior
and halts. He estimates the probability of the next bit
(assuming there will be one), using the remarkable, well-studied,
enumerable prior
![]() [24,29,25,6,15]
[24,29,25,6,15]
| (3) |
However, while ![]() is enumerable, it is not recursive, and thus
practically infeasible. This drawback inspired less general yet
practically more feasible principles of minimum description length
(MDL) [27,17] as well as priors derived from
time-bounded restrictions [15]
of Kolmogorov complexity
[12,24,4].
No particular instance of these approaches, however, is universally
accepted or has a general convincing motivation that carries beyond rather
specialized application scenarios. For instance, typical efficient MDL
approaches require the specification of a class of computable models of
the data, say, certain types of neural networks, plus some computable
loss function expressing the coding costs of the data relative to the
model. This provokes numerous ad-hoc choices.
is enumerable, it is not recursive, and thus
practically infeasible. This drawback inspired less general yet
practically more feasible principles of minimum description length
(MDL) [27,17] as well as priors derived from
time-bounded restrictions [15]
of Kolmogorov complexity
[12,24,4].
No particular instance of these approaches, however, is universally
accepted or has a general convincing motivation that carries beyond rather
specialized application scenarios. For instance, typical efficient MDL
approaches require the specification of a class of computable models of
the data, say, certain types of neural networks, plus some computable
loss function expressing the coding costs of the data relative to the
model. This provokes numerous ad-hoc choices.
The novel approach pursued here agrees that Solomonoff's assumption of recursive priors without any time and space limitations is too weak, and that we somehow should specify additional resource constraints on the data-generating process to obtain a convincing basis for feasible inductive inference. But which constraints are plausible? Which reflect the ``natural'' concept of simplicity? Previous resource-oriented priors derived from, say, polynomial time bounds [15] have no obvious and plausible a priori justification.
Therefore we will suggest a novel, natural prior reflecting data-independent, optimally efficient use of computational resources. Based on this prior, Section 3 will derive a near-optimal computable strategy for making predictions, given past observations.