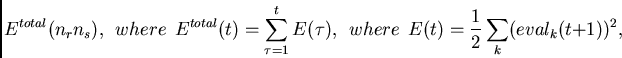Next: 3. INITIAL LEARNING ALGORITHM
Up: 2. THE `INTROSPECTIVE' NETWORK
Previous: 2. THE `INTROSPECTIVE' NETWORK
I assume that the input sequence observed by the network
has length
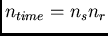 (where
(where
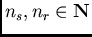 ) and
can be divided into
) and
can be divided into 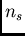 equal-sized blocks of
length
equal-sized blocks of
length 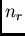 during which the input pattern
during which the input pattern 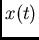 does not change.
This does not imply a loss of generality --
it just means speeding up the network's hardware such that
each input pattern is presented for time-steps before the
next pattern can be observed. This gives
the architecture time-steps to do some
sequential processing (including immediate weight changes)
before seeing a new pattern
of the input sequence.
does not change.
This does not imply a loss of generality --
it just means speeding up the network's hardware such that
each input pattern is presented for time-steps before the
next pattern can be observed. This gives
the architecture time-steps to do some
sequential processing (including immediate weight changes)
before seeing a new pattern
of the input sequence.
In what follows, unquantized
variables are assumed to take on their maximal range. The network
dynamics are specified as follows:
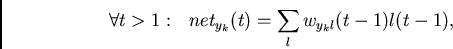 |
(1) |
The network can quickly read information about
its current weights
into the special 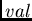 input unit according to
input unit according to
![\begin{displaymath}
val(1) = 0,~~\forall t\geq 1:~
val(t+1) = \sum_{i,j}g[ \Vert ana(t) - adr(w_{ij}) \Vert^2]w_{ij}(t),
\end{displaymath}](img47.png) |
(2) |
where  denotes Euclidean length,
and
denotes Euclidean length,
and 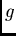 is a differentiable function emitting values
between 0 and 1 that determines
how close a connection address
has to be to the activations of the
analyzing units in order for its weight to contribute to
at that time. Such a function
might have a narrow peak at 1 around the origin and be zero (or
nearly zero)
everywhere else. This essentially allows the network to
pick out a single connection at a time
and obtain its current weight value without receiving
`cross-talk' from other weights.
is a differentiable function emitting values
between 0 and 1 that determines
how close a connection address
has to be to the activations of the
analyzing units in order for its weight to contribute to
at that time. Such a function
might have a narrow peak at 1 around the origin and be zero (or
nearly zero)
everywhere else. This essentially allows the network to
pick out a single connection at a time
and obtain its current weight value without receiving
`cross-talk' from other weights.
The network can quickly modify its current weights using
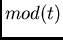 and
and
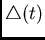 according to
according to
![\begin{displaymath}
~~\forall t \geq 1:~~
w_{ij}(t+1) =
w_{ij}(t) +
\bigtriangleup(t)~g[~ \Vert adr(w_{ij}) - mod(t) \Vert^2~ ].
\end{displaymath}](img51.png) |
(3) |
Again, if has a narrow peak at 1 around the origin and is zero (or
nearly zero) everywhere else, the network will be able to
pick out a single connection at a time and change its weight without
affecting other weights.
Objective function and dynamics of the eval units.
As with typical supervised sequence-learning tasks,
we want to minimize
where
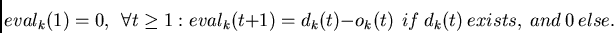 |
(4) |
Here 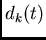 may be a desired target value for the
may be a desired target value for the 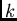 -th
output unit at time step
-th
output unit at time step 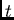 .
.
Next: 3. INITIAL LEARNING ALGORITHM
Up: 2. THE `INTROSPECTIVE' NETWORK
Previous: 2. THE `INTROSPECTIVE' NETWORK
Juergen Schmidhuber
2003-02-21
Back to Metalearning page
Back to Recurrent Neural Networks page