Zur Zeit ![]() bezeichnen wir die Aktivation des
bezeichnen wir die Aktivation des ![]() -ten Knotens mit
-ten Knotens mit
![]() ,
das Gewicht der gerichteten Verbindung von
,
das Gewicht der gerichteten Verbindung von ![]() nach
nach ![]() mit
mit ![]() und ihren Beitrag mit
und ihren Beitrag mit
![]() .
.
Die Aktivationsausbreitungsregel lautet:
Knoten ![]() wird zur Zeit
wird zur Zeit ![]() aktiviert, falls er als Eingabeknoten
eine sensorische Perzeption macht, oder falls er als Nicht-Eingabeknoten
den lokalen Wettbewerb seiner WTA-Einheit gewinnt, weil ihm
unter allen Mitbewerbern
die größte positive Netzeingabe
aktiviert, falls er als Eingabeknoten
eine sensorische Perzeption macht, oder falls er als Nicht-Eingabeknoten
den lokalen Wettbewerb seiner WTA-Einheit gewinnt, weil ihm
unter allen Mitbewerbern
die größte positive Netzeingabe
![]() zu eigen ist.
Wir beschränken uns hier auf den einfachsten Fall:
zu eigen ist.
Wir beschränken uns hier auf den einfachsten Fall:
![]() ist gleich
ist gleich ![]() , falls
, falls ![]() aktiv ist, und
aktiv ist, und ![]() sonst.
sonst.
Die Gewichtsänderungsregel findet simultan mit der Aktivationsausbreitungsregel ihre Anwendung (wir wollen ja Lokalität nicht nur im Raum, sondern auch in der Zeit):
Ist der Nicht-Eingabeknoten ![]() aktiv, ändern sich die Gewichte
gemäß
aktiv, ändern sich die Gewichte
gemäß
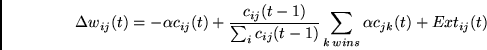
Dabei ist ![]() eine positive Lernrate.
eine positive Lernrate.
![]() ist die zum Zeitpunkt
ist die zum Zeitpunkt ![]() vom externen Kritiker
an
vom externen Kritiker
an ![]() spendierte Gewichtssubstanz, welche z.B wie
folgt berechnet werden kann:
Falls der Kritiker (noch) nicht weiß, ob das Systemverhalten
belohnenswert war, ist
spendierte Gewichtssubstanz, welche z.B wie
folgt berechnet werden kann:
Falls der Kritiker (noch) nicht weiß, ob das Systemverhalten
belohnenswert war, ist
![]() .
Ist der Kritiker aber der Ansicht, daß Belohnung vergeben werden
sollte, und war der Knoten
.
Ist der Kritiker aber der Ansicht, daß Belohnung vergeben werden
sollte, und war der Knoten ![]() zur Zeit
zur Zeit
![]() aktiv, so ist
aktiv, so ist
![]() . Dabei ist
. Dabei ist
![]() ein positiver Proportionalitätsfaktor.
ein positiver Proportionalitätsfaktor.
Im Abschnitt über die Experimente mit der neuronalen Eimerkette
werden wir sehen, daß es viel Raum für mehr oder weniger überwachte
Strategien gibt, das System durch die Bestimmung von
![]() mit Lehrinformation zu versorgen: Es ist ohne weiteres
möglich, jeden Knoten zu jedem Zeitpunkt oder aber
auch nur einige wenige Knoten zu isolierten Zeitpunkten
von externer Seite her zu instruieren.
mit Lehrinformation zu versorgen: Es ist ohne weiteres
möglich, jeden Knoten zu jedem Zeitpunkt oder aber
auch nur einige wenige Knoten zu isolierten Zeitpunkten
von externer Seite her zu instruieren.
Dank der zeitlich veränderlichen Umgebung sind es im allgemeinen nicht die Aktivationen (wie bei Hopfield-Netzen oder bei Equilibriums-BP), sondern höchstens die Gewichte, die einen Zustand des dynamischen Gleichgewichts erreichen können. Ein stabiler Zustand stellt sich ein, wenn jede Verbindung zu jedem Zeitpunkt gerade soviel Gewichtssubstanz verliert, wie sie im nächsten Zeitschritt wieder gewinnt. Das bedeutet, daß (parallel laufende) bereits etablierte `Eimerketten' sequentielle Kooperation und Arbeitsteilung hervorrufen.
Der lokale Charakter aller für die neuronale Eimerkette
notwendigen Berechnungen sei hier noch einmal betont. Es gibt
keinen Bedarf nach extern definierten Trainingsintervallgrenzen.
Es ist nicht notwendig, über weit vergangene Aktivationen
Buch zu führen. Es wird nicht einmal eine kumulative Berechnung
(etwa von exponentiell gewichteten Summen vergangener Aktivationen)
gefordert.
Jeder Knoten und jede Verbindung führen zu jedem Zeitpunkt im
wesentlichen dieselben Berechnungen aus. Für beliebige
Netzwerkstrukturen ist damit der Spitzenberechnungsaufwand
pro Verbindung und Zeitschritt ![]() . Auf
einer sequentiellen v. Neumann Maschine
kann das Verfahren mit einem
Spitzenberechnungsaufwand pro Zeitschritt
von
. Auf
einer sequentiellen v. Neumann Maschine
kann das Verfahren mit einem
Spitzenberechnungsaufwand pro Zeitschritt
von ![]() implementiert werden,
wobei
implementiert werden,
wobei ![]() die Dimension des Gesamtgewichtsvektors
die Dimension des Gesamtgewichtsvektors ![]() ist.
ist.