Für einige der in späteren Kapiteln vorgestellten Problembereiche bieten sich Methoden der zeitlichen Differenzen an, um bestimmte Eigenschaften einer dynamischen Umgebung zu modellieren. Das durch TD-Methoden gewonnene Modell dieser Eigenschaften kann für die adaptive Konstruktion zielgerichteter Programme ausgenützt werden. Dieser Abschnitt liefert die nötigen Grundlagen.
Es liege eine Sequenz von Beobachtungen
![]() eines dynamischen Systems zu aufeinanderfolgenden Zeitpunkten
eines dynamischen Systems zu aufeinanderfolgenden Zeitpunkten ![]() vor.
Das Problem besteht darin, zu jedem Zeitpunkt
vor.
Das Problem besteht darin, zu jedem Zeitpunkt ![]() eine Vorhersage
eine Vorhersage ![]() über den finalen Zustand
über den finalen Zustand
![]() zu treffen. Purer Gradientenabstieg würde bedeuten:
zu treffen. Purer Gradientenabstieg würde bedeuten:
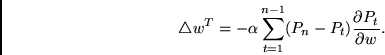
Dabei ist ![]() wieder der Gewichtsvektor des Netzes,
wieder der Gewichtsvektor des Netzes, ![]() eine
positive Lernrate, und
eine
positive Lernrate, und ![]() die von der Lernregel induzierte Gewichtsänderung.
die von der Lernregel induzierte Gewichtsänderung.
TD![]() -Methoden werden im Gegensatz dazu
nun wie folgt definiert:
-Methoden werden im Gegensatz dazu
nun wie folgt definiert:
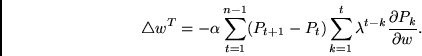
Hierbei ist
![]() ein `Schwundfaktor', welcher
bestimmt, wie stark vergangene Voraussageänderungen in die
Gewichtsänderung mit einfließen.
ein `Schwundfaktor', welcher
bestimmt, wie stark vergangene Voraussageänderungen in die
Gewichtsänderung mit einfließen.
Bei den
TD![]() -Methoden
handelt es sich um eine Generalisierung des Gradientenabstiegs.
Für
-Methoden
handelt es sich um eine Generalisierung des Gradientenabstiegs.
Für ![]() ergibt sich mit etwas Hin- und Herschaufeln von Indizes
nämlich exakt der pure Gradientenabstieg.
ergibt sich mit etwas Hin- und Herschaufeln von Indizes
nämlich exakt der pure Gradientenabstieg.
Für
![]() allerdings bekommt man etwas, was kein Gradientenabstieg ist. Ist das, was
man da erhält, nun gut, oder ist es schlecht?
Es läßt sich zeigen, daß TD
allerdings bekommt man etwas, was kein Gradientenabstieg ist. Ist das, was
man da erhält, nun gut, oder ist es schlecht?
Es läßt sich zeigen, daß TD![]() mit
mit
![]() zumindest für spezielle Arten von dynamischen Systemen
bessere Voraussagen ermöglicht als der pure Gradientenabstieg
TD
zumindest für spezielle Arten von dynamischen Systemen
bessere Voraussagen ermöglicht als der pure Gradientenabstieg
TD![]() : Unter der Voraussetzung,
daß das vorherzusagende System sich als ein absorbierender
Markov-Prozeß beschreiben läßt, konnte Sutton demonstrieren, daß
lineare TD
: Unter der Voraussetzung,
daß das vorherzusagende System sich als ein absorbierender
Markov-Prozeß beschreiben läßt, konnte Sutton demonstrieren, daß
lineare TD![]() zu den optimalen Voraussagen (im Sinne der
`maximum likelihood estimates') konvergiert [67].
(Wiederholung: Ein Markov-Prozeß ist ein Prozeß, bei dem die Weiterevolution
von einem gegebenen Zustand zur Zeit
zu den optimalen Voraussagen (im Sinne der
`maximum likelihood estimates') konvergiert [67].
(Wiederholung: Ein Markov-Prozeß ist ein Prozeß, bei dem die Weiterevolution
von einem gegebenen Zustand zur Zeit ![]() nicht von früheren
Zuständen abhängt. Ein absorbierender Markov-Prozeß ist einer,
bei dem die Wahrscheinlichkeit der Terminierung
nicht von früheren
Zuständen abhängt. Ein absorbierender Markov-Prozeß ist einer,
bei dem die Wahrscheinlichkeit der Terminierung ![]() ist.)
ist.)
Ein weiterer wichtiger Vorteil der
TD![]() -Methoden ist ihre Zugänglichkeit für inkrementelle
Gewichtsänderungen und dem damit verbundenen niedrigen
Spitzenberechnungsaufwand. Am deutlichsten wird das für den
Fall, der uns im weiteren am meisten interessieren soll,
nämlich TD
-Methoden ist ihre Zugänglichkeit für inkrementelle
Gewichtsänderungen und dem damit verbundenen niedrigen
Spitzenberechnungsaufwand. Am deutlichsten wird das für den
Fall, der uns im weiteren am meisten interessieren soll,
nämlich TD![]() . Man führt für jeden Zeitpunkt
. Man führt für jeden Zeitpunkt ![]() einen Wert
einen Wert
![]() ein, welcher sich wie folgt berechnet:
ein, welcher sich wie folgt berechnet:
![]() liefert die Gesamtgewichtsänderung, welche
stattfindet, nachdem
alle Beobachtungen gemacht wurden. Schon während das dynamische
System beobachtet wird, kann man in akkumulativen Variablen die
Summe der bisher berechneten Gewichtsänderungen für jedes
Gewicht inkrementell auf den neuesten Stand bringen. Daher ist
der Spitzenberechnungsaufwand pro Zeitschritt und Gewicht
liefert die Gesamtgewichtsänderung, welche
stattfindet, nachdem
alle Beobachtungen gemacht wurden. Schon während das dynamische
System beobachtet wird, kann man in akkumulativen Variablen die
Summe der bisher berechneten Gewichtsänderungen für jedes
Gewicht inkrementell auf den neuesten Stand bringen. Daher ist
der Spitzenberechnungsaufwand pro Zeitschritt und Gewicht ![]() .
.
Will man ein Verfahren, das komplett `on-line' arbeitet, so kann
man jede Gewichtsänderung in dem Moment durchführen, in dem
sie berechnet wird. Für den TD![]() -Fall bedeutet das:
-Fall bedeutet das:
Dabei ist
![]() die entsprechende Voraussage basierend auf
die entsprechende Voraussage basierend auf
![]() und
und ![]() .
.
Auch für Voraussagen kumulativer Art sind TD-Methoden geeignet.
Später wird es zum Beispiel darauf ankommen, zu jedem
Zeitpunkt ![]() eine Summe noch ausstehender Reinforcementsignale
eine Summe noch ausstehender Reinforcementsignale ![]() zu allen späteren Zeitpunkten
zu allen späteren Zeitpunkten ![]() vorherzusagen. Nach der Lernphase soll für alle
vorherzusagen. Nach der Lernphase soll für alle ![]() gelten:
gelten:

Hierbei kann ![]() für angemessenes
für angemessenes ![]() unendlich sein, denn
unendlich sein, denn
![]() ist
wieder eine `Discountrate', welche
bestimmt, wie stark Erwartungen über verschieden weit in
der Zukunft liegende Ereignisse die
Gewichtsänderung mit beeinflussen sollen.
Da nach obiger Gleichung
ist
wieder eine `Discountrate', welche
bestimmt, wie stark Erwartungen über verschieden weit in
der Zukunft liegende Ereignisse die
Gewichtsänderung mit beeinflussen sollen.
Da nach obiger Gleichung
Für den `on-line' Fall muß man Voraussagen wiederum mit Indizes versehen, die Gewichtsvektoren zu verschiedenen Zeitpunkten anzeigen.
Man sollte nicht vergessen, daß die vorausgesetzte Markov-Eigenschaft in der Praxis oft nicht gegeben ist. Für den Fall, daß die Umgebung (oder zumindest die für ein lernendes System wahrnehmbare Umgebung) nicht vom Markov-Typ ist, kann man allerdings TD-Methoden und generelle Gradientenabstiegsverfahren für rekurrente Netze in sinnvoller Weise kombinieren, wie sich in Kapitel 6 zeigen wird.