



Nächste Seite: Beschreibung einer verwandten Idee
Aufwärts: Einführung eines rekurrenten Kritikers
Vorherige Seite: Einführung eines rekurrenten Kritikers
Inhalt
Auch das im letzten Unterabschnitt beschriebene Verfahren ist noch
einer Erweiterung durch die im vorletzten Unterabschnitt
angegebene Methode zugänglich. Man ändert die Aktivierungsfunktion
von 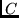 's Knoten wieder so ab, daß die Aktivierungsverteilungen
differenzierbar sind (z.B. mit Hilfe von Gauß-Verteilungen).
Die vom rekurrenten Kritiker
aufgrund von Unterschieden sukzessiver Voraussagen produzierten
internen R-Signale muß man mittels eines dritten
(im allgemeinen Fall ebenfalls rekurrenten) Netzwerkes
's Knoten wieder so ab, daß die Aktivierungsverteilungen
differenzierbar sind (z.B. mit Hilfe von Gauß-Verteilungen).
Die vom rekurrenten Kritiker
aufgrund von Unterschieden sukzessiver Voraussagen produzierten
internen R-Signale muß man mittels eines dritten
(im allgemeinen Fall ebenfalls rekurrenten) Netzwerkes 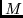 in Abhängigkeit
von vergangenen Zuständen von
modellieren. Gradientenabstieg im Sinne des Systemidentifikationsansatzes
führt dann unter Zuhilfenahme von
zu informierten R-Signalen für [60].
Eine vereinfachte Version erhält man wiederum dadurch, daß man
Kritiker und Modellnetzwerk analog zum letzten Abschnitt zu einem
einzigen rekurrenten Modellkritiker
kollabiert [54].
in Abhängigkeit
von vergangenen Zuständen von
modellieren. Gradientenabstieg im Sinne des Systemidentifikationsansatzes
führt dann unter Zuhilfenahme von
zu informierten R-Signalen für [60].
Eine vereinfachte Version erhält man wiederum dadurch, daß man
Kritiker und Modellnetzwerk analog zum letzten Abschnitt zu einem
einzigen rekurrenten Modellkritiker
kollabiert [54].
Im 5. Kapitel wurde bereits vorgeführt, wie
zunächst nur zwei (statt drei)
interagierende rekurrente Netzwerke den Systemidentifikationsansatz
für R-Lernen dienstbar machen können.
Um aus diesem Ansatz einen rekurrenten Modellkritiker zu gewinnen,
muß 's Fehlerfunktion in A2 in einem
wesentlichen Punkt geändert werden: Der Fehler für die
Vorhersagen der Reinforcementknoten muß gleich
der Differenz zwischen der Summe des nächsten
externen Reinforcements und 's nächster gewichteter Vorhersage
und der gegenwärtigen Vorhersage sein.
Nächste Seite: Beschreibung einer verwandten Idee
Aufwärts: Einführung eines rekurrenten Kritikers
Vorherige Seite: Einführung eines rekurrenten Kritikers
Inhalt
Juergen Schmidhuber
2003-02-20
Related links in English: Recurrent neural networks - Subgoal learning - Reinforcement learning and POMDPs - Reinforcement learning economies - Selective attention
Deutsche Heimseite