Das möglicherweise vorhandene
Autoassoziationsmodul
sowie
jedes der ![]() Prediktonsmodule und der
Prediktonsmodule und der ![]() Repräsentationsmodule
läßt sich als azyklisches BP-Netzwerk implementieren.
Zum Training sind zwei alternierende Phasen vonnöten:
Repräsentationsmodule
läßt sich als azyklisches BP-Netzwerk implementieren.
Zum Training sind zwei alternierende Phasen vonnöten:
PHASE 1 (Minimierung der Prediktionsfehler):
Wiederhole für eine `hinreichende' Anzahl von `Trainingsepochen':
1. Für alle ![]() :
:
1.1. Berechne alle ![]() .
.
1.2. Berechne alle ![]() .
.
1.3. Berechne für alle Gewichte ![]() in
in ![]() mittels BP den Wert
mittels BP den Wert
2. Ändere alle Gewichte ![]() jedes Prediktors
jedes Prediktors ![]() gemäß
gemäß
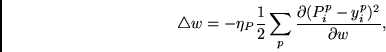
wobei ![]() die positive Lernrate
der Prediktormodule bezeichnet.
die positive Lernrate
der Prediktormodule bezeichnet.
PHASE 2:
1. Für alle ![]() :
:
1.1. Berechne alle ![]() .
.
1.2. Berechne alle ![]() .
.
1.3. Falls ein Autoassoziator verwendet wird, berechne ![]() .
.

Die Gewichte der ![]() ändern sich also während der zweiten
Phase nicht, finden jedoch trotzdem Verwendung, um
Gradienten für die Gewichte der Repräsentationsmodule zu
berechnen. Fehlersignale für die letzteren werden demgemäß
mittels Fehlerpropagierung durch die Eingabeknoten
der Prediktoren (welche ja gleichzeitig Ausgabeknoten
der Repräsentationsmodule sind) gewonnen.
Dies erinnert an die Art und Weise, in der
in Kapitel 4 (allerdings in höchst unterschiedlichem Kontext)
differenzierbare adaptive `Weltmodelle' zur Berechnung von Gradienten
für das eigentlich interessierende `Steuernetzwerk' verwendet werden.
Auch der Subzielgenerator desselben Kapitels bedient sich
eines vergleichbaren Tricks.
ändern sich also während der zweiten
Phase nicht, finden jedoch trotzdem Verwendung, um
Gradienten für die Gewichte der Repräsentationsmodule zu
berechnen. Fehlersignale für die letzteren werden demgemäß
mittels Fehlerpropagierung durch die Eingabeknoten
der Prediktoren (welche ja gleichzeitig Ausgabeknoten
der Repräsentationsmodule sind) gewonnen.
Dies erinnert an die Art und Weise, in der
in Kapitel 4 (allerdings in höchst unterschiedlichem Kontext)
differenzierbare adaptive `Weltmodelle' zur Berechnung von Gradienten
für das eigentlich interessierende `Steuernetzwerk' verwendet werden.
Auch der Subzielgenerator desselben Kapitels bedient sich
eines vergleichbaren Tricks.
Es sollte erwähnt werden, daß einige oder auch alle der Repräsentationsmodule sich versteckte Knoten teilen dürfen. Dasselbe gilt für die Prediktionsmodule. Prediktoren mit gemeinsamen versteckten Knoten müssen ihre Ausgaben allerdings sequentiell berechnen - kein Repräsentationsknoten darf dazu verwendet werden, seine eigene Aktivität vorherzusagen.
Obiger Algorithmus stellt eine `off-line'-Version dar. Gewichte ändern sich erst nach Präsentation des gesamten Eingabemusterensembles; den Prediktoren wird stets eine `hinreichende' Anzahl von Trainingsbeispielen angeboten, um mit den Repräsentationsmodulen Schritt zu halten. Die `off-line'-Version ist möglicherweise weniger attraktiv als eine `on-line'-Version, bei der (1) Eingabemuster zufällig angeboten werden, (2) Gewichtsänderungen sofort nach jeder Musterpräsentation stattfinden, und (3) Prediktoren und Repräsentationsmodule weitgehend simultan lernen. Bei solch einer `on-line'-Version führen allerdings sowohl die Prediktoren als auch die Repräsentationsmodule Gradientenabstieg in sich ändernden Funktionen durch. Wieviel derartige `on-line'-Interaktion gestattet werden darf, bleibt experimentellen Auswertungen überlassen. Bei den im nächsten Abschnitt zu berichtenden Experimenten verursachte die `on-line'-Version keine größeren Schwierigkeiten.
[104] betrachtet auch den Fall stochastischer Repräsentationsknoten, der uns jedoch im Rahmen dieser Arbeit nicht weiter interessieren soll.