



Nächste Seite: ABLEITUNG DER ALGORITHMEN
Aufwärts: DYNAMISCHE VERBINDUNGEN
Vorherige Seite: ARCHITEKTUR 2
Inhalt
Wie bei den rekurrenten Netzen des zweiten Kapitels
wollen wir auch mit der neuen
Architektur Fehlertrajektorien minimieren.
Der Gradient des Fehlers über alle Trainingssequenzen ist
gleich der Summe der Fehlergradienten.
Daher interessiert uns wieder nur der während einer Sequenz
betrachtete Fehler
wobei
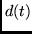 ist dabei erneut der von einem externen
Lehrer vorgegebene Ausgabevektor.
ist dabei erneut der von einem externen
Lehrer vorgegebene Ausgabevektor.
Juergen Schmidhuber
2003-02-20
Related links in English: Recurrent networks - Fast weights - Subgoal learning - Reinforcement learning and POMDPs - Unsupervised learning and ICA - Metalearning and learning to learn
Deutsche Heimseite