Ein noch zu spezifizierender `Autoassoziator' ![]() wird daraufhin trainiert,
jede Eingabesequenz sowie all ihre Anfangssequenzen
in eindeutiger Weise zu repräsentieren (dies ist eine
Form der Quellenkodierung). Ein zusätzliches überwacht
lernendes azyklisches Netzwerk erhält
wird daraufhin trainiert,
jede Eingabesequenz sowie all ihre Anfangssequenzen
in eindeutiger Weise zu repräsentieren (dies ist eine
Form der Quellenkodierung). Ein zusätzliches überwacht
lernendes azyklisches Netzwerk erhält ![]() 's eindeutige
Repräsentationen als Eingabe und lernt,
ein durch allgemeine Fehlertrajektorien definiertes
Performanzmaß zu minimieren7.6.
's eindeutige
Repräsentationen als Eingabe und lernt,
ein durch allgemeine Fehlertrajektorien definiertes
Performanzmaß zu minimieren7.6.
Wir fokussieren uns hier auf den Autoassoziator ![]() .
.
![]() 's einziges Ziel besteht in der Kreierung unterschiedlicher
interner Zustandsvektoren in Antwort auf unterschiedliche
Eingabesequenzen.
's einziges Ziel besteht in der Kreierung unterschiedlicher
interner Zustandsvektoren in Antwort auf unterschiedliche
Eingabesequenzen.
Architektur und Zielfunktion.
Es gibt drei Klassen von Knoten: Eingabeknoten, `versteckte' Knoten,
und Ausgabeknoten.
Alle Eingabeknoten von ![]() sind mit allen versteckten Knoten
verbunden. Alle versteckten Knoten weisen Verbindungen zu
allen Ausgabeknoten auf.
sind mit allen versteckten Knoten
verbunden. Alle versteckten Knoten weisen Verbindungen zu
allen Ausgabeknoten auf.
![]() 's interner Zustandsvektor
's interner Zustandsvektor ![]() ist der Aktivationsvektor seiner versteckten Knoten zum
Zeitpunkt
ist der Aktivationsvektor seiner versteckten Knoten zum
Zeitpunkt ![]() der sich über
der sich über
![]() Zeitschritte erstreckenden
Sequenz
Zeitschritte erstreckenden
Sequenz ![]() .
.
![]() 's Eingabe zur Zeit
's Eingabe zur Zeit ![]() ist
ist
![]() .
Für alle
.
Für alle ![]() nimmt der interne Initialzustand
nimmt der interne Initialzustand
![]() zum Zeitpunkt 0 einen `Defaultwert' an, z.B. den Nullvektor.
Zur Zeit
zum Zeitpunkt 0 einen `Defaultwert' an, z.B. den Nullvektor.
Zur Zeit ![]() , berechnet
, berechnet ![]()
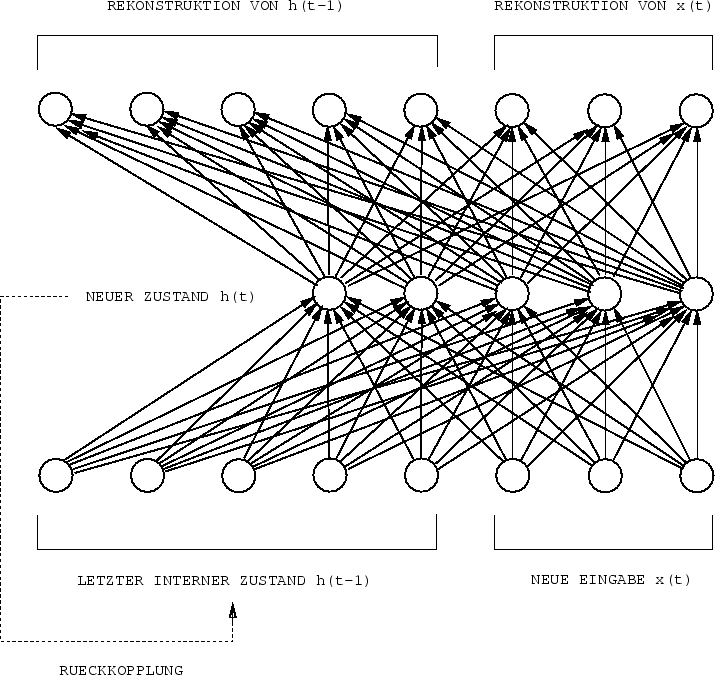 |
Durch konventionelles BP wird ![]() so modifiziert,
daß die
so modifiziert,
daß die
![]() Werte annehmen, die es erlauben,
Werte annehmen, die es erlauben,
![]() und
und ![]() zu rekonstruieren.
zu rekonstruieren.
![]() 's Zielfunktion zur Zeit
's Zielfunktion zur Zeit ![]() der Sequenz
der Sequenz ![]() ist dabei
ist dabei
Zur Minimierung von ![]() wird nicht
etwa wie bei BPTT bis zum Beginn der gegenwärtig behandelten
Sequenz zurückpropagiert, sondern lediglich bis zu
wird nicht
etwa wie bei BPTT bis zum Beginn der gegenwärtig behandelten
Sequenz zurückpropagiert, sondern lediglich bis zu
![]() . Damit bekommen wir zwar keinen
exakten Gradientenabstieg in
. Damit bekommen wir zwar keinen
exakten Gradientenabstieg in
![]() , wohl aber
einen Algorithmus,
(im wesentlichen den von Pollack
vorgeschlagenen7.7),
dessen Berechnungskomplexität pro Verbindung
und Zeitschritt unabhängig von der
Netzgröße konstant ist.
Warum sollte dieser Algorithmus
, wohl aber
einen Algorithmus,
(im wesentlichen den von Pollack
vorgeschlagenen7.7),
dessen Berechnungskomplexität pro Verbindung
und Zeitschritt unabhängig von der
Netzgröße konstant ist.
Warum sollte dieser Algorithmus ![]() dazu zwingen, eindeutige interne Zustände für theoretisch
beliebig lange
Sequenzen und all ihre Subsequenzen zu generieren?
dazu zwingen, eindeutige interne Zustände für theoretisch
beliebig lange
Sequenzen und all ihre Subsequenzen zu generieren?
Die Antwort läßt sich leider nur informell durch Induktion über die Länge der längsten Trainingssequenz sehen (hier haben wir ein Beispiel für einen Lernalgorithmus, der nicht allein aus der Kettenregel gerechtfertigt werden kann):
1. Nehmen wir an, es gibt
![]() verschiedene Trainingssequenzen
verschiedene Trainingssequenzen ![]() . Die
Länge der Sequenz
. Die
Länge der Sequenz
![]() beträgt
beträgt ![]() .
Für alle
.
Für alle
![]() wird
wird ![]() daraufhin trainiert, die Rekonstruktion
von
daraufhin trainiert, die Rekonstruktion
von ![]() und
und ![]() zu ermöglichen.
Demzufolge werden die Anfänge aller
Sequenzen eindeutig in
zu ermöglichen.
Demzufolge werden die Anfänge aller
Sequenzen eindeutig in ![]() repräsentiert sein.
repräsentiert sein.
2. Setzen wir nun voraus, daß alle Sequenzen und Subsequenzen
der Länge
![]() bereits eindeutige Repräsentationen
in
bereits eindeutige Repräsentationen
in ![]() verursachen. Für alle
Sequenzen und Subsequenzen
verursachen. Für alle
Sequenzen und Subsequenzen ![]() mit Länge
mit Länge ![]() zwingen wir
zwingen wir ![]() , die Rekonstruktion von
, die Rekonstruktion von
![]() and
and ![]() zu ermöglichen.
Damit werden alle
Sequenzen und Subsequenzen
mit Länge
zu ermöglichen.
Damit werden alle
Sequenzen und Subsequenzen
mit Länge ![]() eindeutige Repräsentationen in
eindeutige Repräsentationen in ![]() nach sich ziehen.
nach sich ziehen. ![]()
Obiges Argument vernachlässigt allerdings ein Potential
für sogenannten `crosstalk', z.B. die durch den
zweiten Schritt eröffnete Möglichkeit, daß Sequenzen
der Länge ![]() durch Eintrainieren der Sequenzen der
Länge
durch Eintrainieren der Sequenzen der
Länge ![]() wieder `vergessen' werden.
In Experimenten zeigt sich jedoch, daß RAAMs zur Sequenzcodierung
durchaus geeignet sind.
wieder `vergessen' werden.
In Experimenten zeigt sich jedoch, daß RAAMs zur Sequenzcodierung
durchaus geeignet sind.