Methods for direct search in policy space,
such as stochastic hill-climbing (SHC) and
genetic algorithms (GAs),
test policy candidates during time-limited trials, then
build new policy candidates from
some of the policies with highest evaluations observed
so far. As mentioned above,
the advantage of this general approach over traditional
RL algorithms is that
few restrictions need to be imposed on the nature of the
agent's interaction with the environment. In particular,
if the policy allows for actions that manipulate the
content of some sort of short-term memory then
the environment does not need to be fully observable --
in principle, direct methods such as Genetic Programming
[CramerCramer1985,Banzhaf, Nordin, Keller, FranconeBanzhaf
et al.1998],
adaptive Levin Search [Schmidhuber, Zhao, WieringSchmidhuber
et al.1997b],
or Probabilistic Incremental Program Evolution [Sa![]() ustowicz SchmidhuberSa
ustowicz SchmidhuberSa![]() ustowicz Schmidhuber1997],
can be used for
searching spaces of complex, event-memorizing
programs or algorithms as
opposed to simple, memory-free, reactive mappings
from inputs to actions.
ustowicz Schmidhuber1997],
can be used for
searching spaces of complex, event-memorizing
programs or algorithms as
opposed to simple, memory-free, reactive mappings
from inputs to actions.
As pointed out above, a disadvantage of traditional direct methods is that they lack a principled way of dealing with unknown delays and stochastic policy evaluations. In contrast to typical trials executed by direct methods, however, an SSA trial of any previous policy modification never ends unless its reward/time ratio drops below that of the most recent previously started (still unfinished) effective trial. Here we will go beyond previous work [Schmidhuber, Zhao, SchraudolphSchmidhuber et al.1997a,Schmidhuber, Zhao, WieringSchmidhuber et al.1997b] by clearly demonstrating how a direct method can benefit from augmentation by SSA in presence of unknown temporal delays and stochastic performance evaluations.
Task [Schmidhuber ZhaoSchmidhuber Zhao1999]. We tried to come up with the simplest task sufficient to illustrate the drawbacks of standard DS algorithms and the way SSA overcomes them. Hence, instead of studying tasks that require to learn complex programs setting and resetting memory contents (as mentioned above, such complex tasks provide a main motivation for using DS), we use a comparatively simple two-armed bandit problem.
There are two arms A and B.
Pulling arm A will yield reward 1000 with probability 0.01
and reward -1 with probability 0.99.
Pulling arm B will yield reward 1 with probability 0.99
and reward -1000 with probability 0.01.
All rewards are delayed by 5 pulls.
There is an agent that
knows neither the reward distributions nor the delays.
Since this section's goal is to study policy search
under uncertainty we equip the agent with the
simplest possible stochastic policy consisting of a single
variable ![]() (
(
![]() ):
at a given time arm A is chosen with
probability
):
at a given time arm A is chosen with
probability ![]() , otherwise B is chosen.
Modifying the policy in a very limited, SHC-like way (see below)
and observing the long-term
effects is the only way the agent may collect information
that might be useful for improving the policy.
Its goal is to maximize the entire reward
obtained during its life-time which is limited to 30,000 pulls.
The maximal cumulative
reward is 270300 (always choose arm A),
the minimum is -270300 (always choose arm B).
Random arm selection yields expected reward 0.
, otherwise B is chosen.
Modifying the policy in a very limited, SHC-like way (see below)
and observing the long-term
effects is the only way the agent may collect information
that might be useful for improving the policy.
Its goal is to maximize the entire reward
obtained during its life-time which is limited to 30,000 pulls.
The maximal cumulative
reward is 270300 (always choose arm A),
the minimum is -270300 (always choose arm B).
Random arm selection yields expected reward 0.
![]()
Obviously the task is non-trivial, because
the long-term effects of a small
change in ![]() will be hard to detect,
and will require significant statistical sampling.
will be hard to detect,
and will require significant statistical sampling.
It is besides the point of this paper that
our prior knowledge of the problem suggests
a more informed alternative approach such as
``pull arm A for ![]() trials, then
arm B for
trials, then
arm B for ![]() trials, then commit to the best.''
Even cleverer optimizers would
try various assumptions about the
delay lengths
and pull arms in turn
until one was statistically significantly better than the other,
given a particular delay assumption.
We do not allow this, however: we make the task hard by
requiring the agent to learn solely from
observations of outcomes of limited,
SHC-like policy mutations (details below).
After all, in partially observable
environments that are much more complex
and realistic (but less analyzable) than ours this often
is the only reasonable thing to do.
trials, then commit to the best.''
Even cleverer optimizers would
try various assumptions about the
delay lengths
and pull arms in turn
until one was statistically significantly better than the other,
given a particular delay assumption.
We do not allow this, however: we make the task hard by
requiring the agent to learn solely from
observations of outcomes of limited,
SHC-like policy mutations (details below).
After all, in partially observable
environments that are much more complex
and realistic (but less analyzable) than ours this often
is the only reasonable thing to do.
Stochastic Hill-Climbing (SHC).
SHC may be the simplest incremental algorithm using direct
search in policy space.
It should be mentioned, however, that despite its simplicity
SHC often outperforms more complex direct methods such as GAs
[Juels WattenbergJuels Wattenberg1996]. Anyway, SHC and more complex
population-based direct
algorithms such as GAs, GP, and evolution
strategies are equally affected by the central
questions of this paper: how many trials should be spent on
the evaluation of a given policy? How long should a trial
take?![]()
We implement SHC as follows:
1. Initialize policy ![]() to 0.5,
and real-valued variables
to 0.5,
and real-valued variables ![]() and
and ![]() to
to ![]() and 0, respectively.
2.
If there have been more than
and 0, respectively.
2.
If there have been more than
![]() pulls then exit (
pulls then exit (![]() is an integer constant).
Otherwise evaluate
is an integer constant).
Otherwise evaluate ![]() by measuring
the average reward
by measuring
the average reward ![]() obtained during the
next
obtained during the
next ![]() consecutive pulls.
3.
If
consecutive pulls.
3.
If
![]() then
then
![]() , else
, else
![]() and
and
![]() .
4. Randomly perturb
.
4. Randomly perturb ![]() by adding either -0.1 or +0.1
except when this would lead outside the interval [0,1].
Go to 2.
by adding either -0.1 or +0.1
except when this would lead outside the interval [0,1].
Go to 2.
Problem.
Like any direct search algorithm SHC faces the fundamental question
raised in section 2:
how long to evaluate the current policy to obtain statistically
significant results without wasting too much time?
To examine this issue we vary ![]() .
Our prior knowledge of the problem tells us that
.
Our prior knowledge of the problem tells us that
![]() should exceed 5 to handle the 5-step reward delays.
But due to the stochasticity of the rewards,
much larger
should exceed 5 to handle the 5-step reward delays.
But due to the stochasticity of the rewards,
much larger ![]() s are required for reliable evaluations of
some policy's ``true'' performance. Of course, the disadvantage
of long trials is the resulting
small number of possible training exemplars and policy
changes (learning steps) to be executed during the limited life
which lasts just 30,000 steps.
s are required for reliable evaluations of
some policy's ``true'' performance. Of course, the disadvantage
of long trials is the resulting
small number of possible training exemplars and policy
changes (learning steps) to be executed during the limited life
which lasts just 30,000 steps.
Comparison 1. We compare SHC to a combination of SSA and SHC, which we implement just like SHC except that we replace step 3 by a checkpoint (SSA-invocation -- see section 6).
Comparison 2.
To illustrate potential benefits of policies that influence the
way they learn we also compare to SSA applied to
a primitive ``self-modifying policy'' (SMP) with two
modifiable parameters:
![]() (with same meaning as above) and ``learning rate''
(with same meaning as above) and ``learning rate'' ![]() (initially 0).
After each checkpoint,
(initially 0).
After each checkpoint, ![]() is replaced by
is replaced by ![]() , then
, then
![]() is replaced by
is replaced by ![]() . In this sense SMP itself
influences the way it changes, albeit in a way that is much more
limited than the one in previous papers [Schmidhuber, Zhao, SchraudolphSchmidhuber
et al.1997a,SchmidhuberSchmidhuber1999].
If
. In this sense SMP itself
influences the way it changes, albeit in a way that is much more
limited than the one in previous papers [Schmidhuber, Zhao, SchraudolphSchmidhuber
et al.1997a,SchmidhuberSchmidhuber1999].
If ![]() then it will be randomly set to either
then it will be randomly set to either ![]() or
or ![]() .
If
.
If ![]() (
(
![]() ) then it will be replaced by 0.5 (-0.5).
If
) then it will be replaced by 0.5 (-0.5).
If ![]() (
(![]() ) then it will be set to 1 (0).
) then it will be set to 1 (0).
One apparent danger with this approach is that accelerating the learning rate may result in unstable behavior. We will see, however, that SSA precisely prevents this from happening by eventually undoing those learning rate modifications that are not followed by reliable long-term performance improvement.
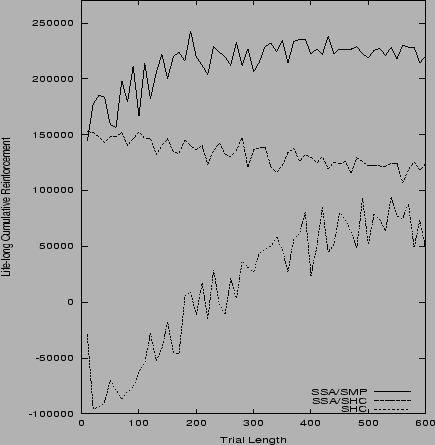 |
Results.
For all three methods Figure 1 plots
lifelong cumulative reward (mean of 100 independent runs)
against ![]() varying from 10 to 600 pulls with
a step size of 10 pulls.
For most values of
varying from 10 to 600 pulls with
a step size of 10 pulls.
For most values of ![]() , SHC fails to realize the long-term
benefits of choosing arm A. SSA/SHC, however, always yields satisfactory
results because it does not
care whether
, SHC fails to realize the long-term
benefits of choosing arm A. SSA/SHC, however, always yields satisfactory
results because it does not
care whether ![]() is much too
short to obtain statistically significant policy evaluations.
Instead it retrospectively readjusts the ``effective'' trial starts:
at any given checkpoint, each previous checkpoint in
is much too
short to obtain statistically significant policy evaluations.
Instead it retrospectively readjusts the ``effective'' trial starts:
at any given checkpoint, each previous checkpoint in ![]() marks the
begin of a new trial lasting up to the current checkpoint.
Each such trial start corresponds to a lifelong reward-acceleration.
The corresponding policy modifications
gain more and more empirical justification
as they keep surviving successive SSA calls, thus becoming more and
more stable.
marks the
begin of a new trial lasting up to the current checkpoint.
Each such trial start corresponds to a lifelong reward-acceleration.
The corresponding policy modifications
gain more and more empirical justification
as they keep surviving successive SSA calls, thus becoming more and
more stable.
Still, SSA/SHC's performance slowly declines with
increasing ![]() since this implies less possible
policy changes and less effective trials due to limited life-time. SSA/SMP (comparison 2),
however, does not much suffer from this problem
since it boldly increases the learning rate
as long as this is empirically observed to accelerate long-term
reward intake. As soon as this is not the case any longer, however,
SSA prevents further learning rate accelerations, thus
avoiding unstable behavior.
This primitive type of learning algorithm self-modification
outperforms SSA/SHC.
In fact, some of the surviving effective trials
may be viewed as "metalearning trials": SSA essentially
observes the long term effects of certain learning rates
whose values are influenced by the policy itself,
and undoes those that tend to cause ``bad" additional policy
modifications setting the stage for
worse performance in subsequent trials.
since this implies less possible
policy changes and less effective trials due to limited life-time. SSA/SMP (comparison 2),
however, does not much suffer from this problem
since it boldly increases the learning rate
as long as this is empirically observed to accelerate long-term
reward intake. As soon as this is not the case any longer, however,
SSA prevents further learning rate accelerations, thus
avoiding unstable behavior.
This primitive type of learning algorithm self-modification
outperforms SSA/SHC.
In fact, some of the surviving effective trials
may be viewed as "metalearning trials": SSA essentially
observes the long term effects of certain learning rates
whose values are influenced by the policy itself,
and undoes those that tend to cause ``bad" additional policy
modifications setting the stage for
worse performance in subsequent trials.
Trials Shorter Than Delays.
We also tested the particularly interesting
case
![]() .
Here SHC and other direct methods
fail completely because the policy tested during
the current trial has nothing to do with the test outcome (due
to the delays).
The SSA/SHC combination, however, still manages to collect
cumulative performance of around 150,000.
Unlike with SHC (and other direct methods)
there is no need for a priori
knowledge about ``good'' trial lengths, exactly because SSA
retrospectively adjusts the effective trial sizes.
.
Here SHC and other direct methods
fail completely because the policy tested during
the current trial has nothing to do with the test outcome (due
to the delays).
The SSA/SHC combination, however, still manages to collect
cumulative performance of around 150,000.
Unlike with SHC (and other direct methods)
there is no need for a priori
knowledge about ``good'' trial lengths, exactly because SSA
retrospectively adjusts the effective trial sizes.
Comparable results were obtained with much longer delays.
In particular, see a recent article [SchmidhuberSchmidhuber1999]
for experiments with much longer
life-times and unknown delays of the order of ![]() time
steps.
time
steps.
A Complex Partially Observable Environment.
This section's focus is on clarifying SSA's advantages
over traditional DS in the simplest possible
setting. It should be mentioned, however, that
there have been much more challenging SSA applications
in partially observable environments, which represent
a major motivation of direct methods because most
traditional RL methods are not applicable here.
For instance,
a previous paper
[Schmidhuber, Zhao, SchraudolphSchmidhuber
et al.1997a]
describes
two agents A and B living in a partially
observable
![]() pixel
environment with obstacles.
They learn to solve a complex task
that could not be solved by various TD(
pixel
environment with obstacles.
They learn to solve a complex task
that could not be solved by various TD(![]() )
Q-learning variants [LinLin1993].
The task requires (1) agent A to find and take a key ``key A'';
(2) agent A go to a door ``door A'' and open it for agent B;
(3) agent B to enter through ``door A'', find and take another key ``key B'';
(4) agent B to go to another door ``door B'' to open it (to free the way to the
goal);
(5) one of the agents to reach the goal.
Both agents share the same design. Each is equipped
with limited ``active'' sight: by executing certain instructions,
it can sense obstacles, its own key,
the corresponding door, or the goal,
within up to 50 pixels in front of it.
The agent can also move forward, turn around, turn relative
to its key or its door or the goal.
It can use short-term memory
to disambiguate inputs -- unlike Jaakkola et al.'s
method (1995), ours is not limited to finding
suboptimal stochastic policies for POEs with an optimal
solution. Each agent can explicitly modify its
own policy via special actions that can address and modify the
probability distributions according to which action sequences
(or ``subprograms") are selected (this
also contributes to making the set-up highly non-Markovian).
Reward is provided only if one of
the agents touches the goal. This agent's reward is 5.0;
the other's is 3.0 (for its cooperation --
note that asymmetric reward also introduces competition).
Due to the complexity of the task,
in the beginning the goal is found only every 300,000 actions
on average
(including actions that are primitive LAs and modify the policy).
No prior information about
good initial trial lengths is given to the system.
Through self-modifications and SSA, however,
within 130,000 goal hits (
)
Q-learning variants [LinLin1993].
The task requires (1) agent A to find and take a key ``key A'';
(2) agent A go to a door ``door A'' and open it for agent B;
(3) agent B to enter through ``door A'', find and take another key ``key B'';
(4) agent B to go to another door ``door B'' to open it (to free the way to the
goal);
(5) one of the agents to reach the goal.
Both agents share the same design. Each is equipped
with limited ``active'' sight: by executing certain instructions,
it can sense obstacles, its own key,
the corresponding door, or the goal,
within up to 50 pixels in front of it.
The agent can also move forward, turn around, turn relative
to its key or its door or the goal.
It can use short-term memory
to disambiguate inputs -- unlike Jaakkola et al.'s
method (1995), ours is not limited to finding
suboptimal stochastic policies for POEs with an optimal
solution. Each agent can explicitly modify its
own policy via special actions that can address and modify the
probability distributions according to which action sequences
(or ``subprograms") are selected (this
also contributes to making the set-up highly non-Markovian).
Reward is provided only if one of
the agents touches the goal. This agent's reward is 5.0;
the other's is 3.0 (for its cooperation --
note that asymmetric reward also introduces competition).
Due to the complexity of the task,
in the beginning the goal is found only every 300,000 actions
on average
(including actions that are primitive LAs and modify the policy).
No prior information about
good initial trial lengths is given to the system.
Through self-modifications and SSA, however,
within 130,000 goal hits (![]() actions) the average trial length
decreases by a factor of 60 (mean of 4 simulations).
Both agents learn to cooperate to accelerate reward intake, by
retrospectively adjusting their effective trial lengths using SSA.
actions) the average trial length
decreases by a factor of 60 (mean of 4 simulations).
Both agents learn to cooperate to accelerate reward intake, by
retrospectively adjusting their effective trial lengths using SSA.
While this previous experimental research has already demonstrated SSA's applicability to large-scale partially observable environments, a study of why it performs well has been lacking. In particular, unlike the present work, previous work [Schmidhuber, Zhao, SchraudolphSchmidhuber et al.1997a] did not clearly identify SSA's fundamental advantages over alternative DS methods.