Previous neural network learning algorithms for sequence processing
are computationally
expensive and perform poorly
when it comes to
long time lags.
This paper first introduces a simple principle for
reducing the descriptions of event sequences
without loss of information.
A consequence of this
principle is that only
unexpected inputs can be relevant.
This insight
leads to the construction of neural architectures that learn to
`divide and conquer' by recursively decomposing sequences.
I describe two architectures.
The first functions as
a self-organizing
multi-level hierarchy of recurrent networks. The second,
involving only two recurrent networks,
tries to collapse a multi-level
predictor hierarchy into a single recurrent net.
Experiments show that the system can require less computation
per time step
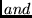
many fewer training sequences than
conventional training algorithms for recurrent nets.