Abstract. In 2020, we celebrated the
30-year anniversary of our
end-to-end differentiable sequential neural attention and goal-conditional reinforcement learning
(RL).[ATT0-1]
This work
was conducted in 1990 at TUM with my student Rudolf Huber.
A few years later, I also described the learning
of internal spotlights of attention in end-to-end differentiable fashion for
outer
product-based Fast Weight Programmers.[FWP2][FWP]
That is, back then we already had both of the now common types of neural sequential attention:
end-to-end differentiable
"soft" attention
(in latent space)
through what's now called the 1991
unnormalised linear Transformer[ULTRA]
with linearized self-attention,
[TR1-6][FWP0-1][FWP6][FWP]
and
"hard" attention (in observation space) in
the context of RL.[ATT0-1]
Today, such techniques are widely used in ChatGPT and other systems.
 Unlike traditional artificial neural networks (NNs), humans use sequential gaze shifts and selective attention to detect and recognize patterns.
This can be much more efficient than the highly parallel approach of traditional feedforward NNs.
That's why we introduced
sequential attention-learning NNs three decades ago (1990 and onwards).[ATT0-1][AC90][PLAN2-6][LEC][DLP][PHD]
Unlike traditional artificial neural networks (NNs), humans use sequential gaze shifts and selective attention to detect and recognize patterns.
This can be much more efficient than the highly parallel approach of traditional feedforward NNs.
That's why we introduced
sequential attention-learning NNs three decades ago (1990 and onwards).[ATT0-1][AC90][PLAN2-6][LEC][DLP][PHD]
Our work[ATT0] also introduced another concept that is widely used in today's Reinforcement Learning (RL):
extra goal-defining input patterns that encode various tasks,
such that the RL machine knows which task to execute next.
Such goal-conditional RL[ATT0-1] is used to train
a neural controller with the help of an adaptive, neural, predictive world model.[AC90] The world model learns to predict parts of future inputs from
past inputs and actions of the controller. Using the world model,
the controller learns to find objects in visual scenes, by steering a fovea through sequences of saccades, thus learning sequential attention. User-defined goals (target objects) are provided to the system by special "goal input vectors" that remain constantSec. 3.2 of [ATT1] while the controller shapes its stream of visual inputs through fovea-shifting actions.
In the same year of 1990, we also used goal-conditional RL
for
hierarchical RL with
end-to-end differentiable subgoal generators.[HRL0-2][DLH][DLP][LEC] An NN with task-defining inputs
of the form (start, goal) learns to predict the costs of going from start states to goal states.
(Compare my former student Tom Schaul's "universal value function approximator" at DeepMind a quarter century later.[UVF15])
In turn, the gradient descent-based subgoal generator NN learns to use such predictions to come up with better subgoals.Sec. 10 & Sec. 12 of [MIR]
Section 5 of my
overview paper for CMSS 1990[ATT2] summarised our early work on attention,
apparently the first implemented neural system for combining glimpses that jointly trains a recognition & prediction component
with an attentional component (the fixation controller).[DLP][T22], Sec. 9 of [MIR]
Learning Internal Spotlights of Attention
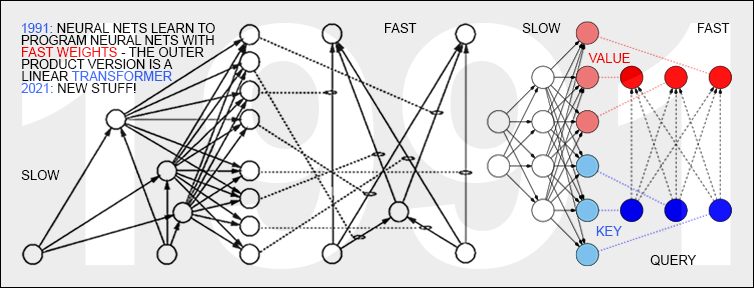
A typical NN has many more connections than neurons.
In traditional NNs, neuron activations change quickly,
while connection weights change slowly.
That is, the numerous weights cannot implement short-term memories
or temporal variables, only the few neuron activations can.
Non-traditional NNs with quickly changing "fast weights" overcome this limitation.
Dynamic links or fast weights for NNs were introduced by Christoph v. d. Malsburg in 1981[FAST] and further studied by others.[FASTa,b]
However, before 1991, no network learned by gradient descent to quickly compute the changes of the fast weight storage of another network or of itself.
Such end-to-end-differentiable
Fast Weight Programmers (FWPs)[FWP] were published in 1991-93.[FWP0-2]
There a slow NN learns to program the weights of a separate fast NN.
That is, I separated storage and control like in traditional computers,
but in a fully neural way (rather than in a hybrid fashion[PDA1-2]).
FWPs embody the principles found in certain types of what is now called
attention[ATT]
and Transformers.[TR1-6][FWP] In particular, in 1991, I had
what's now called the
unnormalised linear Transformer[ULTRA]
with linearized self-attention.[TR1-6][FWP0-1][FWP6][FWP]
See also: who invented transformer neural networks?[TR25]
Some of my Fast Weight Programmers used gradient descent-based, active control of fast weights through 2D tensors or outer product updates[FWP1-2] (compare our more recent work on this[FWP3-3a][FWP6]).
One of the motivations[FWP2]
was to get many more temporal variables under end-to-end differentiable control than what's possible in standard RNNs of the same size: O(H^2) instead of O(H), where H is the number of hidden units. A quarter century later, others followed this approach.[FWP4a][DLP]
The 1993 paper[FWP2] also explicitly addressed the learning of "internal spotlights of attention" in end-to-end-differentiable networks.
Like the LSTM,
the 1991 Fast Weight Programmers[FWP1-2] can learn to memorize past data, e.g.,
by computing fast weight changes through additive outer products of self-invented activation patterns[FWP0-1]
(now often called keys and values for self-attention[TR1-6]).
The similar Transformers[TR1-2] combine this with projections
and softmax and
are now (2021) widely used in natural language processing (a traditional LSTM domain).
For long input sequences, their efficiency was improved through linear
Transformers with linearized self-attention.[TR5-6]
The unnormalised linear Transformer is actually mathematically equivalent[FWP6] to my 1991 fast weight controller[FWP0][ULTRA] published when compute was a million times more expensive than in 2021.[FWP]
All these "modern" attention-based techniques
have roots in my lab of 1991 at TUM.[MOST]
Acknowledgments
 Thanks to several expert reviewers for useful comments. Since science is about self-correction, let me know under juergen@idsia.ch if you can spot any remaining error. The contents of this article may be used for educational and non-commercial purposes, including articles for Wikipedia and similar sites. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Thanks to several expert reviewers for useful comments. Since science is about self-correction, let me know under juergen@idsia.ch if you can spot any remaining error. The contents of this article may be used for educational and non-commercial purposes, including articles for Wikipedia and similar sites. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
 References
References
[AC90]
J. Schmidhuber.
Making the world differentiable: On using fully recurrent
self-supervised neural networks for dynamic reinforcement learning and
planning in non-stationary environments.
Technical Report FKI-126-90, TUM, Feb 1990, revised Nov 1990.
PDF
[ATT] J. Schmidhuber (AI Blog, 2020). 30-year anniversary of end-to-end differentiable sequential neural attention. Plus goal-conditional reinforcement learning. Schmidhuber had both hard attention for foveas (1990) and soft attention in form of Transformers with linearized self-attention (1991-93).[FWP] Today, both types are very popular.
[ATT0] J. Schmidhuber and R. Huber.
Learning to generate focus trajectories for attentive vision.
Technical Report FKI-128-90, Institut für Informatik, Technische
Universität München, 1990.
PDF.
[ATT1] J. Schmidhuber and R. Huber. Learning to generate artificial fovea trajectories for target detection. International Journal of Neural Systems, 2(1 & 2):135-141, 1991. Based on TR FKI-128-90, TUM, 1990.
PDF.
More.
[ATT2]
J. Schmidhuber.
Learning algorithms for networks with internal and external feedback.
In D. S. Touretzky, J. L. Elman, T. J. Sejnowski, and G. E. Hinton,
editors, Proc. of the 1990 Connectionist Models Summer School, pages
52-61. San Mateo, CA: Morgan Kaufmann, 1990.
PS. (PDF.)
[DL1] J. Schmidhuber, 2015.
Deep Learning in neural networks: An overview. Neural Networks, 61, 85-117.
More.
[DL2] J. Schmidhuber, 2015.
Deep Learning.
Scholarpedia, 10(11):32832.
[DL4] J. Schmidhuber, 2017. Our impact on the world's most valuable public companies: 1. Apple, 2. Alphabet (Google), 3. Microsoft, 4. Facebook, 5. Amazon ...
HTML.
[DLH]
J. Schmidhuber (AI Blog, 2022).
Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, IDSIA, Lugano, Switzerland, 2022.
Preprint arXiv:2212.11279.
Tweet of 2022.
[DLP]
J. Schmidhuber (AI Blog, 2023).
How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23, Swiss AI Lab IDSIA, 14 Dec 2023.
Tweet of 2023.
[DEC] J. Schmidhuber (02/20/2020). The 2010s: Our Decade of Deep Learning / Outlook on the 2020s.
[HRL0]
J. Schmidhuber.
Towards compositional learning with dynamic neural networks.
Technical Report FKI-129-90, Institut für Informatik, Technische
Universität München, 1990.
PDF.
[HRL1]
J. Schmidhuber. Learning to generate sub-goals for action sequences. In T. Kohonen, K. Mäkisara, O. Simula, and J. Kangas, editors, Artificial Neural Networks, pages 967-972. Elsevier Science Publishers B.V., North-Holland, 1991. PDF. Extending TR FKI-129-90, TUM, 1990.
HTML & images in German.
[HRL2]
J. Schmidhuber and R. Wahnsiedler.
Planning simple trajectories using neural subgoal generators.
In J. A. Meyer, H. L. Roitblat, and S. W. Wilson, editors, Proc.
of the 2nd International Conference on Simulation of Adaptive Behavior,
pages 196-202. MIT Press, 1992.
PDF.
HTML & images in German.
[HRL4]
M. Wiering and J. Schmidhuber. HQ-Learning. Adaptive Behavior 6(2):219-246, 1997.
PDF.
[FAST] C. v.d. Malsburg. Tech Report 81-2, Abteilung f. Neurobiologie,
Max-Planck Institut f. Biophysik und Chemie, Goettingen, 1981.
First paper on fast weights or dynamic links.
[FASTa]
J. A. Feldman. Dynamic connections in neural networks.
Biological Cybernetics, 46(1):27-39, 1982.
2nd paper on fast weights.
[FASTb]
G. E. Hinton, D. C. Plaut. Using fast weights to deblur old memories. Proc. 9th annual conference of the Cognitive Science Society (pp. 177-186), 1987.
Two types of weights with different learning rates.
[FWP]
J. Schmidhuber (AI Blog, 26 March 2021, updated 2025).
26 March 1991: Neural nets learn to program neural nets with fast weights—like Transformer variants. 2021: New stuff!
30-year anniversary of a now popular
alternative[FWP0-1] to recurrent NNs.
A slow feedforward NN learns by gradient descent to program the changes of
the fast weights[FAST,FASTa] of
another NN, separating memory and control like in traditional computers.
Such Fast Weight Programmers[FWP0-6,FWPMETA1-8] can learn to memorize past data, e.g.,
by computing fast weight changes through additive outer products of self-invented activation patterns[FWP0-1]
(now often called keys and values for self-attention[TR1-6]).
The similar Transformers[TR1-2] combine this with projections
and softmax and
are now widely used in natural language processing.
For long input sequences, their efficiency was improved through
Transformers with linearized self-attention[TR5-6]
which are formally equivalent to Schmidhuber's 1991 outer product-based Fast Weight Programmers (apart from normalization), now called unnormalized linear Transformers.[ULTRA]
In 1993, he introduced
the attention terminology[FWP2] now used
in this context,[ATT] and
extended the approach to
RNNs that program themselves.
See tweet of 2022.
[FWP0]
J. Schmidhuber.
Learning to control fast-weight memories: An alternative to recurrent nets.
Technical Report FKI-147-91, Institut für Informatik, Technische
Universität München, 26 March 1991.
PDF.
First paper on fast weight programmers that separate storage and control: a slow net learns by gradient descent to compute weight changes of a fast net. The outer product-based version (Eq. 5) is now known as a "Transformer with linearized self-attention."[FWP]
[FWP1] J. Schmidhuber. Learning to control fast-weight memories: An alternative to recurrent nets. Neural Computation, 4(1):131-139, 1992. Based on [FWP0].
PDF.
HTML.
Pictures (German).
See tweet of 2022 for 30-year anniversary.
[FWP2] J. Schmidhuber. Reducing the ratio between learning complexity and number of time-varying variables in fully recurrent nets. In Proceedings of the International Conference on Artificial Neural Networks, Amsterdam, pages 460-463. Springer, 1993.
PDF.
First recurrent NN-based fast weight programmer using outer products, introducing the terminology of learning "internal spotlights of attention."
[FWP3] I. Schlag, J. Schmidhuber. Gated Fast Weights for On-The-Fly Neural Program Generation. Workshop on Meta-Learning, @N(eur)IPS 2017, Long Beach, CA, USA.
[FWP3a] I. Schlag, J. Schmidhuber. Learning to Reason with Third Order Tensor Products. Advances in Neural Information Processing Systems (N(eur)IPS), Montreal, 2018.
Preprint: arXiv:1811.12143. PDF.
[FWP4a] J. Ba, G. Hinton, V. Mnih, J. Z. Leibo, C. Ionescu. Using Fast Weights to Attend to the Recent Past. NIPS 2016.
PDF.
[FWP4b]
D. Bahdanau, K. Cho, Y. Bengio (2014).
Neural Machine Translation by Jointly Learning to Align and Translate. Preprint arXiv:1409.0473 [cs.CL].
[FWP4d]
Y. Tang, D. Nguyen, D. Ha (2020).
Neuroevolution of Self-Interpretable Agents.
Preprint: arXiv:2003.08165.
[FWP5]
F. J. Gomez and J. Schmidhuber.
Evolving modular fast-weight networks for control.
In W. Duch et al. (Eds.):
Proc. ICANN'05,
LNCS 3697, pp. 383-389, Springer-Verlag Berlin Heidelberg, 2005.
PDF.
HTML overview.
Reinforcement-learning fast weight programmer.
[FWP6] I. Schlag, K. Irie, J. Schmidhuber.
Linear Transformers Are Secretly Fast Weight Memory Systems. 2021. Preprint: arXiv:2102.11174.
[FWP7] K. Irie, I. Schlag, R. Csordas, J. Schmidhuber.
Going Beyond Linear Transformers with Recurrent Fast Weight Programmers.
Preprint: arXiv:2106.06295 (June 2021).
[FWPMETA1] J. Schmidhuber. Steps towards `self-referential' learning. Technical Report CU-CS-627-92, Dept. of Comp. Sci., University of Colorado at Boulder, November 1992.
First recurrent fast weight programmer that can learn
to run a learning algorithm or weight change algorithm on itself.
[FWPMETA2] J. Schmidhuber. A self-referential weight matrix.
In Proceedings of the International Conference on Artificial
Neural Networks, Amsterdam, pages 446-451. Springer, 1993.
PDF.
[FWPMETA3] J. Schmidhuber.
An introspective network that can learn to run its own weight change algorithm. In Proc. of the Intl. Conf. on Artificial Neural Networks,
Brighton, pages 191-195. IEE, 1993.
[FWPMETA4]
J. Schmidhuber.
A neural network that embeds its own meta-levels.
In Proc. of the International Conference on Neural Networks '93,
San Francisco. IEEE, 1993.
[FWPMETA5]
J. Schmidhuber. Habilitation thesis, TUM, 1993. PDF.
A recurrent neural net with a self-referential, self-reading, self-modifying weight matrix
can be found here.
[FWPMETA6]
L. Kirsch and J. Schmidhuber. Meta Learning Backpropagation & Improving It. Metalearning Workshop at NeurIPS, 2020.
Preprint arXiv:2012.14905 [cs.LG], 2020.
[FWPMETA7]
I. Schlag, T. Munkhdalai, J. Schmidhuber.
Learning Associative Inference Using Fast Weight Memory.
To appear at ICLR 2021.
Report arXiv:2011.07831 [cs.AI], 2020.
[LSTM2] F. A. Gers, J. Schmidhuber, F. Cummins. Learning to Forget: Continual Prediction with LSTM. Neural Computation, 12(10):2451-2471, 2000.
PDF.
The "vanilla LSTM architecture" with forget gates
that everybody is using today, e.g., in Google's Tensorflow.
[LEC] J. Schmidhuber (AI Blog, 2022). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015. Years ago, Schmidhuber's team published most of what Y. LeCun calls his "main original contributions:" neural nets that learn multiple time scales and levels of abstraction, generate subgoals, use intrinsic motivation to improve world models, and plan (1990); controllers that learn informative predictable representations (1997), etc. This was also discussed on Hacker News, reddit, and in the media.
[MIR] J. Schmidhuber (AI Blog, Oct 2019, updated 2025). Deep Learning: Our Miraculous Year 1990-1991. Preprint
arXiv:2005.05744. The deep learning neural networks (NNs) of our team have revolutionised pattern recognition & machine learning & AI. Many of the basic ideas behind this revolution were published within fewer than 12 months in our "Annus Mirabilis" 1990-1991 at TU Munich, including principles of (1)
LSTM, the most cited AI of the 20th century (based on constant error flow through residual connections); (2) ResNet, the most cited AI of the 21st century (based on our LSTM-inspired Highway Network, 10 times deeper than previous NNs); (3)
GAN (for artificial curiosity and creativity); (4) Transformer (the T in ChatGPT—see the 1991 Unnormalized Linear Transformer); (5) Pre-training for deep NNs (the P in ChatGPT); (6) NN distillation (see DeepSeek); (7) recurrent World Models, and more.
[MOST]
J. Schmidhuber (AI Blog, 2021, updated 2025). The most cited neural networks all build on work done in my labs: 1. Long Short-Term Memory (LSTM), the most cited AI of the 20th century. 2. ResNet (open-gated Highway Net), the most cited AI of the 21st century. 3. AlexNet & VGG Net (the similar but earlier DanNet of 2011 won 4 image recognition challenges before them). 4. GAN (an instance of Adversarial Artificial Curiosity of 1990). 5. Transformer variants—see the 1991 unnormalised linear Transformer (ULTRA). Foundations of Generative AI were published in 1991: the principles of GANs (now used for deepfakes), Transformers (the T in ChatGPT), Pre-training for deep NNs (the P in ChatGPT), NN distillation, and the famous DeepSeek—see the tweet.
[PHD]
J. Schmidhuber.
Dynamische neuronale Netze und das fundamentale raumzeitliche
Lernproblem
(Dynamic neural nets and the fundamental spatio-temporal
credit assignment problem).
Dissertation,
Institut für Informatik, Technische
Universität München, 1990.
PDF.
HTML.
[PDA1]
G.Z. Sun, H.H. Chen, C.L. Giles, Y.C. Lee, D. Chen. Neural Networks with External Memory Stack that Learn Context—Free Grammars from Examples. Proceedings of the 1990 Conference on Information Science and Systems, Vol.II, pp. 649-653, Princeton University, Princeton, NJ, 1990.
[PDA2]
M. Mozer, S. Das. A connectionist symbol manipulator that discovers the structure of context-free languages. Proc. NIPS 1993.
[PLAN]
J. Schmidhuber (AI Blog, 2020). 30-year anniversary of planning & reinforcement learning with recurrent world models and artificial curiosity (1990). This work also introduced high-dimensional reward signals, deterministic policy gradients for RNNs,
the GAN principle (widely used today). Agents with adaptive recurrent world models even suggest a simple explanation of consciousness & self-awareness.
[PLAN2]
J. Schmidhuber.
An on-line algorithm for dynamic reinforcement learning and planning
in reactive environments.
In Proc. IEEE/INNS International Joint Conference on Neural
Networks, San Diego, volume 2, pages 253-258, 1990.
Based on.[AC90]
[PLAN3]
J. Schmidhuber.
Reinforcement learning in Markovian and non-Markovian environments.
In D. S. Lippman, J. E. Moody, and D. S. Touretzky, editors,
Advances in Neural Information Processing Systems 3, NIPS'3, pages 500-506. San
Mateo, CA: Morgan Kaufmann, 1991.
PDF.
Partially based on.[AC90]
[PLAN4]
J. Schmidhuber.
On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models.
Report arXiv:1210.0118 [cs.AI], 2015.
[PLAN5]
One Big Net For Everything. Preprint arXiv:1802.08864 [cs.AI], Feb 2018.
[PLAN6]
D. Ha, J. Schmidhuber. Recurrent World Models Facilitate Policy Evolution. Advances in Neural Information Processing Systems (NIPS), Montreal, 2018. (Talk.)
Preprint: arXiv:1809.01999.
Github: World Models.
[T22] J. Schmidhuber (AI Blog, 2022).
Scientific Integrity and the History of Deep Learning: The 2021 Turing Lecture, and the 2018 Turing Award. Technical Report IDSIA-77-21, IDSIA, Lugano, Switzerland, 2022.
[TR1]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin (2017). Attention is all you need. NIPS 2017, pp. 5998-6008.
This paper introduced the name "Transformers" for a now widely used NN type. It did not cite
the 1991 publication on what's now called unnormalized "linear Transformers" with "linearized self-attention."[ULTRA]
Schmidhuber also introduced the now popular
attention terminology in 1993.[ATT][FWP2][R4]
See tweet of 2022 for 30-year anniversary.
[TR2]
J. Devlin, M. W. Chang, K. Lee, K. Toutanova (2018). Bert: Pre-training of deep bidirectional Transformers for language understanding. Preprint arXiv:1810.04805.
[TR3] K. Tran, A. Bisazza, C. Monz. The Importance of Being Recurrent for Modeling Hierarchical Structure. EMNLP 2018, p 4731-4736. ArXiv preprint 1803.03585.
[TR4]
M. Hahn. Theoretical Limitations of Self-Attention in Neural Sequence Models. Transactions of the Association for Computational Linguistics, Volume 8, p.156-171, 2020.
[TR5]
A. Katharopoulos, A. Vyas, N. Pappas, F. Fleuret.
Transformers are RNNs: Fast autoregressive Transformers
with linear attention. In Proc. Int. Conf. on Machine
Learning (ICML), July 2020.
[TR5a] Z. Shen, M. Zhang, H. Zhao, S. Yi, H. Li.
Efficient Attention: Attention with Linear Complexities.
WACV 2021.
[TR6]
K. Choromanski, V. Likhosherstov, D. Dohan, X. Song,
A. Gane, T. Sarlos, P. Hawkins, J. Davis, A. Mohiuddin,
L. Kaiser, et al. Rethinking attention with Performers.
In Int. Conf. on Learning Representations (ICLR), 2021.
[TR6a] H. Peng, N. Pappas, D. Yogatama, R. Schwartz, N. A. Smith, L. Kong.
Random Feature Attention.
ICLR 2021.
[TR7]
S. Bhattamishra, K. Ahuja, N. Goyal.
On the Ability and Limitations of Transformers to Recognize Formal Languages.
EMNLP 2020.
[TR8]
W. Merrill, A. Sabharwal.
The Parallelism Tradeoff: Limitations of Log-Precision Transformers.
TACL 2023.
[TR25]
J. Schmidhuber (AI Blog, 2025). Who Invented Transformer Neural Networks? Technical Note IDSIA-11-25, Nov 2025.
[ULTRA]
References on the 1991 unnormalized linear Transformer (ULTRA): original tech report (March 1991) [FWP0]. Journal publication (1992) [FWP1]. Recurrent ULTRA extension (1993) introducing the terminology of learning "internal spotlights of attention” [FWP2]. Modern "quadratic" Transformer (2017: "attention is all you need") scaling quadratically in input size [TR1]. 2020 paper [TR5] using the terminology
"linear Transformer" for a more efficient Transformer variant that scales linearly, leveraging linearized attention [TR5a].
2021 paper [FWP6] pointing out that ULTRA dates back to 1991 [FWP0] when compute was a million times more expensive.
Overview of ULTRA and other Fast Weight Programmers (2021) [FWP].
See the T in ChatGPT! See also surveys [DLH][DLP], 2022 tweet for ULTRA's 30-year anniversary, and 2024 tweet.
[UVF15]
T. Schaul, D. Horgan, K. Gregor, D. Silver. Universal value function approximators. Proc. ICML 2015, pp. 1312-1320, 2015.
.

