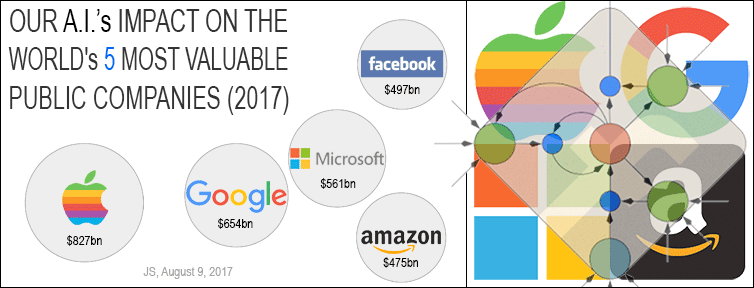
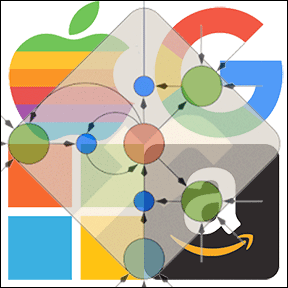
 Our deep learning methods
developed since 1991 have transformed machine learning and Artificial Intelligence (AI), and are now available to billions of users through the five most valuable public companies in the world: Apple (#1 as of 9 August 2017 with a market capitalization of US$ 827 billion), Google (Alphabet, #2, 654bn), Microsoft (#3, 561bn), Facebook (#4, 497bn), and Amazon (#5, 475bn) [1].
Our deep learning methods
developed since 1991 have transformed machine learning and Artificial Intelligence (AI), and are now available to billions of users through the five most valuable public companies in the world: Apple (#1 as of 9 August 2017 with a market capitalization of US$ 827 billion), Google (Alphabet, #2, 654bn), Microsoft (#3, 561bn), Facebook (#4, 497bn), and Amazon (#5, 475bn) [1].
 Many of the most
widely used AI applications
of these companies are now based on our Long Short-Term Memory (LSTM) recurrent neural networks (RNNs), which learn from experience to solve all kinds of previously unsolvable problems.
The LSTM principle has become a foundation of what's now called deep learning (see survey), especially for sequential data
(but also for very deep feedforward networks [11,12]).
LSTM-based systems can learn to translate languages, control robots, analyse images, summarise documents, recognise speech and videos and handwriting, run chat bots, predict diseases and click rates and stock markets, compose music, and much more, e.g., [22].
Most of our main peer-reviewed publications
on LSTM appeared between 1997 and 2009, the year when LSTM became the
first RNN to win international pattern recognition competitions, e.g., [8, 9, 9a-c, 10, 10a].
Many of the most
widely used AI applications
of these companies are now based on our Long Short-Term Memory (LSTM) recurrent neural networks (RNNs), which learn from experience to solve all kinds of previously unsolvable problems.
The LSTM principle has become a foundation of what's now called deep learning (see survey), especially for sequential data
(but also for very deep feedforward networks [11,12]).
LSTM-based systems can learn to translate languages, control robots, analyse images, summarise documents, recognise speech and videos and handwriting, run chat bots, predict diseases and click rates and stock markets, compose music, and much more, e.g., [22].
Most of our main peer-reviewed publications
on LSTM appeared between 1997 and 2009, the year when LSTM became the
first RNN to win international pattern recognition competitions, e.g., [8, 9, 9a-c, 10, 10a].
 Apple explained at its WWDC 2016 developer conference
how our LSTM is improving its iPhone [2b],
for example, the Quicktype function.
Apple's Siri also uses LSTM in various ways [2b+].
Apple explained at its WWDC 2016 developer conference
how our LSTM is improving its iPhone [2b],
for example, the Quicktype function.
Apple's Siri also uses LSTM in various ways [2b+].
 Google's speech recognition [2] for over two billion
Android phones and many other devices is also based on LSTM (1997) [8] with forget gates (2000) [9] trained by our "Connectionist Temporal Classification (CTC)" (2006) [10].
In 2015, this approach dramatically improved Google's recognition rate
not only by 5% or 10% (which already would have been great) but by almost 50% [2a].
Google's speech recognition [2] for over two billion
Android phones and many other devices is also based on LSTM (1997) [8] with forget gates (2000) [9] trained by our "Connectionist Temporal Classification (CTC)" (2006) [10].
In 2015, this approach dramatically improved Google's recognition rate
not only by 5% or 10% (which already would have been great) but by almost 50% [2a].
Google is using our rather universal LSTM also for
image caption generation [2g],
automatic email answering [2h],
its new smart assistant Allo [2i],
and its dramatically improved Google Translate [10b, 10b+, 2i].
In fact, almost 30% of the awesome computational power for inference in all those Google datacenters is now used for LSTM [10c] (and 5% are used for convolutional neural networks or CNNs - see below). You are probably using LSTM all the time in your daily life.
Will Google itself end up as one huge LSTM?
 Microsoft uses LSTM
Microsoft uses LSTM
 not only for its own greatly improved speech recognition [2c,2c+] but also for
photo-real talking heads [2k]
and for learning to write code [2m],
amongst other things.
not only for its own greatly improved speech recognition [2c,2c+] but also for
photo-real talking heads [2k]
and for learning to write code [2m],
amongst other things.
Amazon's famous Echo or Alexa
also speaks to you in your home [2e] through our bidirectional [9b] LSTM
which has learned to sound like a woman. (No, it's not a recording!)

 In August 2017,
Facebook announced that it
is now using our LSTM
to handle a whopping
4.5 billion translations each day, for more than 2,000 translation directions
from one language to another
[2n].
In August 2017,
Facebook announced that it
is now using our LSTM
to handle a whopping
4.5 billion translations each day, for more than 2,000 translation directions
from one language to another
[2n].
This completes the list of the five most valuable public companies as of August 2017.
All of them state that AI is central to their business, and all of them are
massively using LSTM, which is now permeating the modern world.
What can we learn from that? If you want your company to be among the
world's most valuable ones, better use LSTM!
Interestingly, Samsung
has been exploring LSTM as well (e.g., [2o]),
and has become
the world's most profitable company [2p] as of Q2 2017 :-)

 Other great Asian companies such as Chinese search giant Baidu are also building [2d]
on our deep learning methods such as CTC [10].
Other great Asian companies such as Chinese search giant Baidu are also building [2d]
on our deep learning methods such as CTC [10].
IBM used LSTM to
analyze emotions [2j], amongst other things.
Numerous other famous companies are using LSTM
for all kinds of applications such as predictive maintenance, stock market prediction, click rate prediction, automatic document analysis, etc.

 Another influential
contribution of our lab at IDSIA (since 2010)
was to greatly speed up [18, 18b-d, 19, 20a-e] deep supervised feedforward neural networks (NNs) on NVIDIA's fast graphics processors (GPUs), in particular,
convolutional NNs or CNNs [4].
This convinced the Machine Learning community that my
traditional
unsupervised pre-training of NNs (1991-2009) [e.g., 7a-c]
is not required.
In 2011, our fast GPU-based CNNs [18b]
achieved the
first superhuman pattern recognition result in the history of computer vision [18c-d,19], and then
kept winning contests
with larger and larger images [20a-d+].
Another influential
contribution of our lab at IDSIA (since 2010)
was to greatly speed up [18, 18b-d, 19, 20a-e] deep supervised feedforward neural networks (NNs) on NVIDIA's fast graphics processors (GPUs), in particular,
convolutional NNs or CNNs [4].
This convinced the Machine Learning community that my
traditional
unsupervised pre-training of NNs (1991-2009) [e.g., 7a-c]
is not required.
In 2011, our fast GPU-based CNNs [18b]
achieved the
first superhuman pattern recognition result in the history of computer vision [18c-d,19], and then
kept winning contests
with larger and larger images [20a-d+].
 In particular, in 2012, we had
the first deep NNs to win medical imaging contests [20a-d] (important for healthcare which represents 10% of the world's GDP).
Our fast CNN image scanners were over 1000 times faster than previous methods [20e].
Today, many startups as well as established companies such
as Facebook & IBM & Google are
using such deep GPU-CNNs for numerous applications [22].
Arcelor Mittal, the world's largest steel maker,
worked with us to greatly improve steel defect detection [3].
In May 2015, we also had the first working very deep NNs with hundreds of layers [11]; a special case thereof was used by Microsoft [12] to improve
image recognition.
NVIDIA
rebranded itself as a
deep learning company.
BTW, thanks to NVIDIA for our 2016 NN Pioneers of AI Award, and for generously
funding our research!
In particular, in 2012, we had
the first deep NNs to win medical imaging contests [20a-d] (important for healthcare which represents 10% of the world's GDP).
Our fast CNN image scanners were over 1000 times faster than previous methods [20e].
Today, many startups as well as established companies such
as Facebook & IBM & Google are
using such deep GPU-CNNs for numerous applications [22].
Arcelor Mittal, the world's largest steel maker,
worked with us to greatly improve steel defect detection [3].
In May 2015, we also had the first working very deep NNs with hundreds of layers [11]; a special case thereof was used by Microsoft [12] to improve
image recognition.
NVIDIA
rebranded itself as a
deep learning company.
BTW, thanks to NVIDIA for our 2016 NN Pioneers of AI Award, and for generously
funding our research!
 Even earlier, in 2009, our
CTC-trained LSTM [10,10a]
became the first recurrent neural network to
win competitions.
Our lead author Alex Graves [10a] later joined
DeepMind, a startup company
Even earlier, in 2009, our
CTC-trained LSTM [10,10a]
became the first recurrent neural network to
win competitions.
Our lead author Alex Graves [10a] later joined
DeepMind, a startup company
 heavily influenced by other former students of my lab:
DeepMind's first people with publications and PhDs in Artificial Intelligence & Machine Learning were PhD students at IDSIA, one of them DeepMind's co-founder (Shane Legg), one of them the first employee (Daan Wierstra, #4 of DeepMind). (The other two co-founders were not from my lab and had different backgrounds in biological neuroscience and business.) DeepMind was later bought by Google for about $600M; Alex became first author of DeepMind's recent Nature paper [10d]. BTW, thanks to
Google DeepMind for generously funding our research!
heavily influenced by other former students of my lab:
DeepMind's first people with publications and PhDs in Artificial Intelligence & Machine Learning were PhD students at IDSIA, one of them DeepMind's co-founder (Shane Legg), one of them the first employee (Daan Wierstra, #4 of DeepMind). (The other two co-founders were not from my lab and had different backgrounds in biological neuroscience and business.) DeepMind was later bought by Google for about $600M; Alex became first author of DeepMind's recent Nature paper [10d]. BTW, thanks to
Google DeepMind for generously funding our research!

 Although our work
has influenced
many companies large and small, most of our pioneers of basic learning algorithms and methods for Artificial General Intelligence (AGI) are still based in Switzerland or affiliated with our company NNAISENSE. Its name is pronounced like "nascence," because it's about the birth of a general purpose Neural Network-based Artificial Intelligence (NNAI). It has 5 co-founders (CEO Faustino Gomez, Jan Koutnik, Jonathan Masci, Bas Steunebrink, and myself),
brilliant advisors (Sepp Hochreiter, Marcus Hutter, Jaan Tallinn), outstanding employees, and revenues through ongoing state-of-the-art applications in industry and finance.
We believe that the successes above are just the beginning, and that we can go far beyond what's possible today, through novel variants of learning to learn and recursive self-improvement (since 1987) and artificial curiosity and creativity and optimal program search and large reinforcement learning RNNs, to pull off the big practical breakthrough that will change everything, in line with my old motto since the 1970s: "build an AI smarter than myself such that I can retire"
(e.g., H+ magazine, Jan 2010).
Although our work
has influenced
many companies large and small, most of our pioneers of basic learning algorithms and methods for Artificial General Intelligence (AGI) are still based in Switzerland or affiliated with our company NNAISENSE. Its name is pronounced like "nascence," because it's about the birth of a general purpose Neural Network-based Artificial Intelligence (NNAI). It has 5 co-founders (CEO Faustino Gomez, Jan Koutnik, Jonathan Masci, Bas Steunebrink, and myself),
brilliant advisors (Sepp Hochreiter, Marcus Hutter, Jaan Tallinn), outstanding employees, and revenues through ongoing state-of-the-art applications in industry and finance.
We believe that the successes above are just the beginning, and that we can go far beyond what's possible today, through novel variants of learning to learn and recursive self-improvement (since 1987) and artificial curiosity and creativity and optimal program search and large reinforcement learning RNNs, to pull off the big practical breakthrough that will change everything, in line with my old motto since the 1970s: "build an AI smarter than myself such that I can retire"
(e.g., H+ magazine, Jan 2010).
 Related articles:
Scientific American Blog (Nov 2017),
Wall Street Journal (May 2017, front page, has paywall),
Bloomberg (Jan 2017),
Guardian (April 2017, front page),
NY Times (Nov 2016, front page),
long interview at NPA &
ACM (Oct 2016, short version in
IT World),
WIRED (Nov 2016),
Financial Times (Nov 2016, also here),
Inverse (Dec 2016),
Intl. Business Times (Feb 2016),
BeMyApp (Mar 2016),
Informilo (Jan 2016),
InfoQ (Mar 2016).
Also in leading German language newspapers:
ZEIT (May 2016,
ZEIT online in June),
Spiegel (Europe's top news magazine, Feb 2016),
NZZ 1 & 2 (August 2016),
Tagesanzeiger (Sep 2016),
Beobachter (Sep 2016),
CHIP (April 2016),
Computerwoche (July 2016),
WiWo (Jan 2016),
Spiegel (Jan 2016),
Focus (Mar 2016),
Welt (Mar 2016),
SZ (Mar 2016),
FAZ (Dec 2015, title page),
NZZ (Nov 2015).
More in
Netzoekonom (Mar 2016),
Performer (Oct 2016),
WiWo (Feb 2016),
Focus (Jan 2016),
Bunte (Jan 2016). Earlier:
Handelsblatt (Jun 2015),
INNS Big Data (Feb 2015),
KurzweilAI (Nov 2012),
Fifth Conference (June 2010) ... Disclaimer: I am not responsible for everything that's written in these articles!
Related articles:
Scientific American Blog (Nov 2017),
Wall Street Journal (May 2017, front page, has paywall),
Bloomberg (Jan 2017),
Guardian (April 2017, front page),
NY Times (Nov 2016, front page),
long interview at NPA &
ACM (Oct 2016, short version in
IT World),
WIRED (Nov 2016),
Financial Times (Nov 2016, also here),
Inverse (Dec 2016),
Intl. Business Times (Feb 2016),
BeMyApp (Mar 2016),
Informilo (Jan 2016),
InfoQ (Mar 2016).
Also in leading German language newspapers:
ZEIT (May 2016,
ZEIT online in June),
Spiegel (Europe's top news magazine, Feb 2016),
NZZ 1 & 2 (August 2016),
Tagesanzeiger (Sep 2016),
Beobachter (Sep 2016),
CHIP (April 2016),
Computerwoche (July 2016),
WiWo (Jan 2016),
Spiegel (Jan 2016),
Focus (Mar 2016),
Welt (Mar 2016),
SZ (Mar 2016),
FAZ (Dec 2015, title page),
NZZ (Nov 2015).
More in
Netzoekonom (Mar 2016),
Performer (Oct 2016),
WiWo (Feb 2016),
Focus (Jan 2016),
Bunte (Jan 2016). Earlier:
Handelsblatt (Jun 2015),
INNS Big Data (Feb 2015),
KurzweilAI (Nov 2012),
Fifth Conference (June 2010) ... Disclaimer: I am not responsible for everything that's written in these articles!
.
References
[1]
Largest Companies by Market Cap Today (August 9, 2017);
List of public corporations by market capitalization (Wikipedia, 2017).
We ignore
non-public companies such as Saudi Aramco whose value
was estimated (2016) at several trillions of US$.
[2] Google's speech recognition for Android phones etc. based on our LSTM & CTC:
Google Research Blog, Sep 2015 and
Aug 2015
 [2a] Dramatic
improvement of Google's speech recognition through LSTM:
Alphr Technology, Jul 2015, or 9to5google, Jul 2015
[2a] Dramatic
improvement of Google's speech recognition through LSTM:
Alphr Technology, Jul 2015, or 9to5google, Jul 2015
[2b] Apple's iPhone uses our LSTM, e.g., TechCrunch, Jul 2016, or
noJitter, Jun 2016
[2b+] Apple's Siri uses LSTM for various tasks, e.g., BGR.com, Jun 2016
[2c] Microsoft's speech recognition also uses LSTM, e.g., TheRegister, Oct 2016 or Business Insider, Oct 2016
[2c+] The
Microsoft 2017 Conversational Speech Recognition System with LSTM (Xiong, Wu, Alleva, Droppo, Huang, Stolcke, Aug 20, 2017)
[2d] Baidu's speech recognition also uses our CTC [10], e.g., VentureBeat, Jan 2016
[2e] Amazon
uses our LSTM for Alexa & Echo,
e.g., Vogels' Blog, Nov 2016
[2g] Google's image caption generation with LSTM:
arXiv PDF, Nov 2014
[2h] Google's
automatic email answering with LSTM:
WIRED, Mar 2015
[2h] Google's smart assistant Allo with LSTM:
Google Research Blog, May 2016
[2i] Google's
dramatically improved Google Translate [10b] based on LSTM, e.g., arXiv report, Sep 2016, or
HotHardWare, Sep 2016, or
WIRED, Sep 2016,
or
siliconAngle, Sep 2016
[2j] IBM uses LSTM to
analyze emotions (2014)
[2k] Microsoft uses LSTM for
photo-real talking heads (2014)
[2m] Microsoft uses LSTM for
learning to write programs (2017)
[2n]
Facebook
is now using our LSTM
to handle
over 4 billion automatic translations per day (The Verge, August 4, 2017);
see also
Facebook blog by J.M. Pino, A. Sidorov, N.F. Ayan (August 3, 2017)
[2o]
Samsung has been exploring LSTM, too, e.g.,
here (2016)
[2p]
Samsung is
the world's most profitable public
company, e.g.,
TechSpot (27 July 2017)
[3] Arcelor Mittal: our GPU-based CNNs for much better steel defect detection; see Masci et al., IJCNN 2012
[4] Fukushima's CNN
architecture [13] (1979) (with Max-Pooling [14], 1993) is trained [6] in the shift-invariant 1D case [15a-b] or 2D case [15-17] by Linnainmaa's automatic differentiation or backpropagation algorithm of 1970 [5] (extending earlier work in control theory [5a-c]).
 [5] Linnainmaa, S. (1970).
The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's thesis, Univ. Helsinki. (See also BIT Numerical Mathematics, 16(2):146-160, 1976.)
[5] Linnainmaa, S. (1970).
The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's thesis, Univ. Helsinki. (See also BIT Numerical Mathematics, 16(2):146-160, 1976.)
[5a] Kelley, H. J. (1960). Gradient theory of optimal flight paths. ARS Journal, 30(10):947-954.
[5b] Bryson, A. E. (1961). A gradient method for optimizing multi-stage allocation processes. In Proc. Harvard Univ. Symposium on digital computers and their applications.
[5c] Dreyfus, S. E. (1962). The numerical solution of variational problems. Journal of Mathematical Analysis and Applications, 5(1):30-45.
[6] Werbos, P. J. (1982). Applications of advances in nonlinear sensitivity analysis. In Proceedings of the 10th IFIP Conference, 31.8 - 4.9, NYC, pp. 762-770. (Extending thoughts in his 1974 thesis.)
[7a]
Schmidhuber, J. (1992). Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242. Based on TR FKI-148-91, TUM, 1991.
More.
[7b] G. E. Hinton, R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, Vol. 313. no. 5786, pp. 504 - 507, 2006.
[7c] Raina, R., Madhavan, A., and Ng, A. (2009). Large-scale deep unsupervised learning using graphics processors. In Proceedings of the 26th Annual International Conference on Machine Learning (ICML), pages 873-880. ACM.
 [8] Hochreiter, S.
and Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8):1735-1780. Based on TR FKI-207-95, TUM (1995).
More.
[8] Hochreiter, S.
and Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8):1735-1780. Based on TR FKI-207-95, TUM (1995).
More.
[9] Gers, F. A., Schmidhuber, J., and Cummins, F. (2000). Learning to forget: Continual prediction with LSTM. Neural Computation, 12(10):2451-2471.
[9a] S. Fernandez,
A. Graves, J. Schmidhuber. Sequence labelling in structured domains with hierarchical recurrent neural networks. In Proc. IJCAI 07, p. 774-779, Hyderabad, India, 2007
[9b]
A. Graves and J. Schmidhuber. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Networks, 18:5-6, pp. 602-610, 2005.
[9c]
J. Bayer, D. Wierstra, J. Togelius, J. Schmidhuber. Evolving memory cell structures for sequence learning. Proc. ICANN-09, Cyprus, 2009.
 [10] Graves, A.,
Fernandez, S., Gomez, F. J., and Schmidhuber, J. (2006). Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural nets. Proc. ICML'06, pp. 369-376. PDF.
[10] Graves, A.,
Fernandez, S., Gomez, F. J., and Schmidhuber, J. (2006). Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural nets. Proc. ICML'06, pp. 369-376. PDF.
[10a] A. Graves, M. Liwicki, S. Fernandez, R. Bertolami, H. Bunke, J. Schmidhuber. A Novel Connectionist System for Improved Unconstrained Handwriting Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 5, 2009.
[10b] Y. Wu et al (2016). Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.
Preprint arXiv:1609.08144
[10b+]
D. Britz et al (2017). Massive Exploration of Neural Machine Translation
Architectures. Preprint arXiv:1703.03906
[10c] Jouppi et al (2017). In-Datacenter Performance Analysis of a Tensor Processing Unit.
Preprint arXiv:1704.04760
[10d]
A. Graves et al. Hybrid computing using a neural network with dynamic external memory. Nature 538.7626 (2016): 471-476.
[11] Srivastava, R. K., Greff, K., Schmidhuber, J. Highway networks.
arXiv:1505.00387
(May 2015) and
arXiv:1507.06228
(Jul 2015). Also at NIPS'2015. The first working very deep feedforward nets with over 100 layers. Let g, t, h, denote non-linear differentiable functions. Each non-input layer of a highway net computes g(x)x + t(x)h(x), where x is the data from the previous layer. (Like LSTM [8] with forget gates [9] for RNNs.) Resnets [12] are a special case of this where g(x)=t(x)=const=1.
 [12] He, K., Zhang,
X., Ren, S., Sun, J. Deep residual learning for image recognition. Preprint
arXiv:1512.03385
(Dec 2015). Residual nets [12] are a special case of highway nets [11], with
g(x)=1 (a typical highway net initialisation) and t(x)=1.
[12] He, K., Zhang,
X., Ren, S., Sun, J. Deep residual learning for image recognition. Preprint
arXiv:1512.03385
(Dec 2015). Residual nets [12] are a special case of highway nets [11], with
g(x)=1 (a typical highway net initialisation) and t(x)=1.
[13] K. Fukushima.
Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4): 193-202, 1980.
Scholarpedia.
[14] Weng, J., Ahuja, N., and Huang, T. S. (1993). Learning recognition and segmentation of 3-D objects from 2-D images. Proc. 4th Intl. Conf. Computer Vision, Berlin, Germany, pp. 121-128.
[15a] A. Waibel. Phoneme Recognition using Time-Delay Neural Networks. Meeting of IEICE, Tokyo, Japan, 1987.
[15b] A. Waibel, T. Hanazawa, G. Hinton, K. Shikano and K. J. Lang. Phoneme recognition using time-delay neural networks. IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 37, no. 3, pp. 328-339, March 1989.
[15] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, L. D. Jackel: Backpropagation Applied to Handwritten Zip Code Recognition, Neural Computation, 1(4):541-551, 1989.
[16] M. A. Ranzato, Y. LeCun: A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images. Proc. ICDAR, 2007
[17] D. Scherer, A. Mueller, S. Behnke. Evaluation of pooling operations in convolutional architectures for object recognition. In Proc. ICANN 2010.
 [18] Ciresan, D. C.,
Meier, U., Gambardella, L. M., and Schmidhuber, J. (2010). Deep big simple neural nets for handwritten digit recognition. Neural Computation, 22(12):3207-3220.
[18] Ciresan, D. C.,
Meier, U., Gambardella, L. M., and Schmidhuber, J. (2010). Deep big simple neural nets for handwritten digit recognition. Neural Computation, 22(12):3207-3220.
[18b] D. C. Ciresan, U. Meier, J. Masci, L. M. Gambardella, J. Schmidhuber. Flexible, High Performance Convolutional Neural Networks for Image Classification. International Joint Conference on Artificial Intelligence (IJCAI-2011, Barcelona), 2011.
[Speeding up deep CNNs on GPU by a factor of 60.
Basis of computer vision contest winners since 2011.]
 [18c] D. C. Ciresan,
U. Meier, J. Masci, J. Schmidhuber. A Committee of Neural Networks for Traffic Sign Classification. International Joint Conference on Neural Networks (IJCNN-2011, San Francisco), 2011.
[18c] D. C. Ciresan,
U. Meier, J. Masci, J. Schmidhuber. A Committee of Neural Networks for Traffic Sign Classification. International Joint Conference on Neural Networks (IJCNN-2011, San Francisco), 2011.
[18d]
Results of 2011 IJCNN traffic sign recognition contest
[18e] Results of 2011 ICDAR Chinese handwriting recognition competition:
WWW site,
PDF.
[19] Ciresan, D. C.,
Meier, U., and Schmidhuber, J. (2012c). Multi-column deep neural networks for image classification. Proc. CVPR, June 2012. Long preprint
arXiv:1202.2745 [cs.CV], Feb 2012.
 [20a]
Results of 2012 ICPR cancer detection contest
[20a]
Results of 2012 ICPR cancer detection contest
[20b]
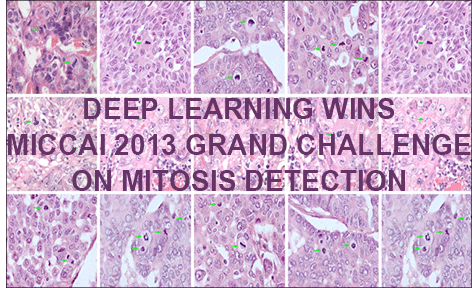
Results of 2013 MICCAI Grand Challenge (cancer detection)
[20c] D. C. Ciresan, A. Giusti, L. M. Gambardella, J. Schmidhuber. Mitosis Detection in Breast Cancer Histology Images using Deep Neural Networks. MICCAI 2013.
 [20d] D. Ciresan,
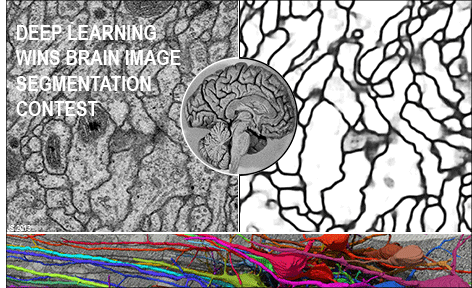
A. Giusti, L. Gambardella, J. Schmidhuber. Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images. NIPS 2012, Lake Tahoe, 2012.
[20d] D. Ciresan,
A. Giusti, L. Gambardella, J. Schmidhuber. Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images. NIPS 2012, Lake Tahoe, 2012.
[20d+]
I. Arganda-Carreras, S. C. Turaga, D. R. Berger, D. Ciresan, A. Giusti, L. M. Gambardella, J. Schmidhuber, D. Laptev, S. Dwivedi, J. M. Buhmann, T. Liu, M. Seyedhosseini, T. Tasdizen, L. Kamentsky, R. Burget, V. Uher, X. Tan, C. Sun, T. Pham, E. Bas, M. G. Uzunbas, A. Cardona, J. Schindelin, H. S. Seung.
Crowdsourcing the creation of image segmentation algorithms for connectomics.
Front. Neuroanatomy, November 2015.
 [20e] J. Masci,
A. Giusti, D. Ciresan, G. Fricout, J. Schmidhuber. A Fast Learning Algorithm for Image Segmentation with Max-Pooling Convolutional Networks. ICIP 2013.
Preprint arXiv:1302.1690
[20e] J. Masci,
A. Giusti, D. Ciresan, G. Fricout, J. Schmidhuber. A Fast Learning Algorithm for Image Segmentation with Max-Pooling Convolutional Networks. ICIP 2013.
Preprint arXiv:1302.1690
[22] Schmidhuber, J. (2015).
Deep learning in neural networks: An overview. Neural Networks, 61, 85-117.
More.
Short version at
Scholarpedia.
Fibonacci web design