Consider Figure 2.
The entrance to the small room is blocked.
Whenever the point-like agent moves
into the
![]() northeast
corner (GOAL1) of the
northeast
corner (GOAL1) of the
![]() field it receives external
reward 100.0 and is immediately teleported back to start position
field it receives external
reward 100.0 and is immediately teleported back to start position
![]() ; its direction is reset to 0.0.
; its direction is reset to 0.0.
Solution. GOAL1 can be reached by a simple stochastic policy making the agent head in the northeast direction. Once the system somehow has fixed the agent's direction in an optimal way, the shortest path requires about 100 calls of MoveAgent (due to the agent's limited stepsize). We will see that the major difficulties in learning such a policy are due to the system's extremely low initial bias towards solving this task, and the extremely rare occurrences of rewarding training instances.
Random behavior results.
With its module-modifying capabilities being switched off
(LIs such as IncProbLEFT(![]() ) have no effect),
the system exhibits random behavior according to its
maximum entropy initialization. This behavior leads to about
five visits to GOAL1 per 10 million time steps, which shows
how little built-in knowledge there is about the nature of the goal.
Following Geman et al. [6],
the learning system's bias towards solving the task is extremely
low, while variance is high.
There is a confusing choice of
) have no effect),
the system exhibits random behavior according to its
maximum entropy initialization. This behavior leads to about
five visits to GOAL1 per 10 million time steps, which shows
how little built-in knowledge there is about the nature of the goal.
Following Geman et al. [6],
the learning system's bias towards solving the task is extremely
low, while variance is high.
There is a confusing choice of
![]() module columns (many more than needed
for solving the task), all being potential
candidates for modifications.
The two modules initially have no idea
that two of the 23 instruction types (namely, MoveAgent
and SetDirection) are particularly important.
Furthermore, module modifications
can be computed only by appropriate instruction subsequences
(including LIs)
generated according to the module columns themselves.
Initially all instructions are extremely stochastic, however,
partly due to the many arguments and addresses to jump to.
Reducing this ``free parameter overkill''
by using smaller modules
would be equivalent to inserting more
a priori knowledge about the task.
module columns (many more than needed
for solving the task), all being potential
candidates for modifications.
The two modules initially have no idea
that two of the 23 instruction types (namely, MoveAgent
and SetDirection) are particularly important.
Furthermore, module modifications
can be computed only by appropriate instruction subsequences
(including LIs)
generated according to the module columns themselves.
Initially all instructions are extremely stochastic, however,
partly due to the many arguments and addresses to jump to.
Reducing this ``free parameter overkill''
by using smaller modules
would be equivalent to inserting more
a priori knowledge about the task.
Comparison. I compare the performance of two learning systems.
One is curious/creative in the sense described in the previous sections, the other
is not. The latter is like the former except that its Bet!
action has no effect -- external reward is the only type of reward.
Ten simulations are conducted for each system.
Each simulation takes 200 million time steps.
During the 10th and the 20th ![]() time step interval
I count how often the agent visits GOAL1.
Since external reward initially occurs only every 2
million time steps on average, goal-relevant
training examples are very rare.
time step interval
I count how often the agent visits GOAL1.
Since external reward initially occurs only every 2
million time steps on average, goal-relevant
training examples are very rare.
Results.
Table 1 lists the plain and the curious systems'
goal visits per ![]() time steps
after half their life times, and near death.
All 10 results are given due to the high variance.
The curious system's results tend to be more than an order of
magnitude better than the plain's,
which tend to be more than an order of
magnitude better than the random's.
time steps
after half their life times, and near death.
All 10 results are given due to the high variance.
The curious system's results tend to be more than an order of
magnitude better than the plain's,
which tend to be more than an order of
magnitude better than the random's.
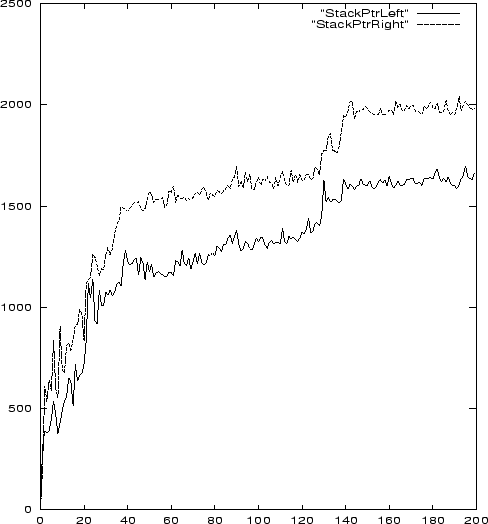
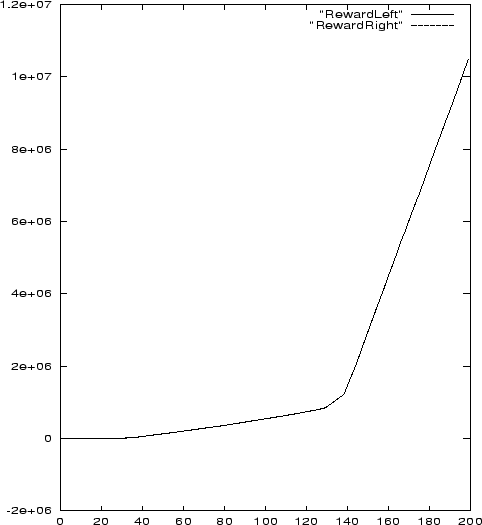
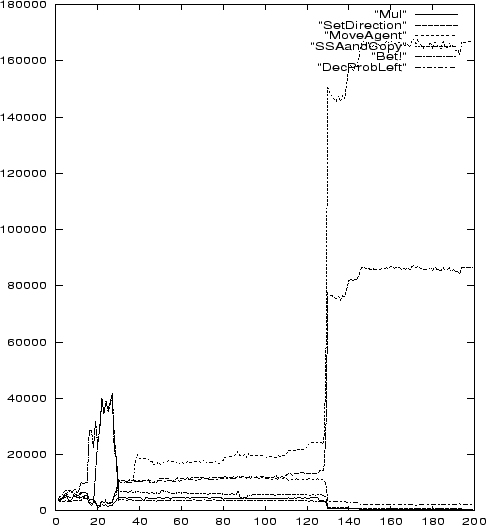
Figures 6, 7, 8 show details of the particularly successful simulation 1. We observe that total reward fluctuations due to surprise rewards appear negligible, although they seem important for overall performance improvement (compare Table 1). Between 20 and 30 million steps there are lots of Bet and SSAandCopy actions. Soon afterwards the instruction types Move and SetDirection start to dominate. Around 130 million steps their frequencies suddenly rise dramatically. The final breakthrough is achieved shortly thereafter. The modules' first 100 columns after simulation 1 are shown in Figure 9. Both modules are almost identical. The probability mass of many columns is concentrated in a single value. Additional inspection revealed, however, that some of the most frequently used instruction addresses point to maximum entropy distributions.
Possible explanation. How can curiosity/creativity help? In early system life external rewards occur very rarely. During this time, however, there are many surprise reward-oriented instruction subsequences. Possibly they provide the system with useful fragments of ``probabilistic knowledge'' about consequences of its innate instructions. For instance, to repeatedly surprise itself it may construct little ``probabilistic subprograms'' involving highly probable jumps to appropriate module column addresses. Once it has figured out how to increase the likelihood of certain jumps it may find it easier to solve external tasks that also require jumps.
Details of how the system actually came up with the final matrices remain quite unclear, however. More experimental analysis is necessary to better understand how solving external tasks can benefit from pure curiosity.
 |
 |
 |
 |
The outlier. Note the curious system's outlier in the second simulation. Inspection revealed that during the entire simulation the system never reached the goal at all -- there was not a single training example concerning external reward. This outlier reflects curiosity's potential drawback: it may focus attention on computations that do not have anything to do with external reinforcement. On average, however, surprise rewards do help.
Runtimes. To some readers the runtimes of several hundred million time steps may seem large. Note, however, that the number of training examples (trials) is much smaller because the goal is hit very rarely, especially in the beginning of the learning phase. Some initial trials take millions of time steps simply because the system does not know that there is a source of reward at all, and that some of its instructions (those for interaction with the environment) are much more important for achieving the goal than arithmetic instructions -- not one biases its search towards the goal. The following simulations will require even longer runtimes.