



Nächste Seite: Modellbildende Verfahren
Aufwärts: Neuronale Ansätze
Vorherige Seite: Keine Rückkopplung
Inhalt
Durch Minskys und Paperts in Kapitel 2
beschriebenes Prinzip des `unfolding in time'
lassen sich REINFORCE-Algorithmen auf zyklische Netzwerke ohne
externe Rückkopplung erweitern.
Reinforcement  kann dabei zu verschiedenen Zeitpunkten eines
Trainingsintervalls vergeben werden. Die Lernregel für den
erweiterten Fall definiert in leichter Abwandlung des
azyklischen Falles für jedes Gewicht
kann dabei zu verschiedenen Zeitpunkten eines
Trainingsintervalls vergeben werden. Die Lernregel für den
erweiterten Fall definiert in leichter Abwandlung des
azyklischen Falles für jedes Gewicht 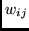 eine
Gewichtsänderung
eine
Gewichtsänderung
 :
:
mit
wobei 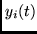 die Aktivation und
die Aktivation und
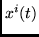 den Eingabevektor von
den Eingabevektor von  abhängig vom Zeitpunkt
abhängig vom Zeitpunkt  darstellt, und über alle Zeitpunkte
außer dem ersten des Trainingsintervalls rangiert.
darstellt, und über alle Zeitpunkte
außer dem ersten des Trainingsintervalls rangiert.
Das zentrale Theorem besagt nun, daß das innere
Produkt
positiv ist, solange der zweite Faktor nicht Null ist.
Damit haben wir den bisher allgemeinsten Lernalgorithmus für neuronale
Netze kennengelernt. Er ist (wenigstens im Prinzip) tauglich für
Reinforcement-Lernen mit interner Rückkopplung. Auch diese
erweiterten REINFORCE-Algorithmen können schwach lokal
in Raum und Zeit implementiert werden. Die starke Lokalität
ist jedoch nicht gegeben, da wieder eine externe Instanz über die Trennung
zwischen Aktivationsausbreitung und Gewichtsänderung wachen muß.
Wir betonen hier noch einmal, daß Williams' Resultate nicht
den allgemeineren Fall der externen Rückkopplung mit einbeziehen.
Nächste Seite: Modellbildende Verfahren
Aufwärts: Neuronale Ansätze
Vorherige Seite: Keine Rückkopplung
Inhalt
Juergen Schmidhuber
2003-02-20
Related links in English: Recurrent neural networks - Subgoal learning - Reinforcement learning and POMDPs - Reinforcement learning economies - Selective attention
Deutsche Heimseite