



Nächste Seite: Interne Rückkopplung: Dynamische Netzwerke
Aufwärts: Statische Netzwerke
Vorherige Seite: Statische Netzwerke mit interner
Inhalt
In den letzten beiden Abschnitten wurden Algorithmen zur
statischen Musterassoziation beschrieben. Mit solchen
Algorithmen läßt sich eine triviale
Art von dynamischem Verhalten erlernen: Man trainiert
ein Netzwerk mittels einer geordneten Sequenz von Musterpaaren
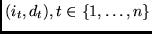 , bei der
die Ausgabe
, bei der
die Ausgabe  gleich der Eingabe
gleich der Eingabe 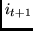 ist, für
ist, für
 .
Im Arbeitsmodus kopiert man zwischen aufeinanderfolgenden
Zeitschritten die Ausgaben eines solchermaßen trainierten
Netzwerkes zurück auf seine Eingabeknoten.
Selbstverständlich lassen sich auf diese Weise niemals über mehr als
einen Zeitschritt reichenden temporalen Abhängigkeiten
erreichen: Die Ausgabe zur Zeit
.
Im Arbeitsmodus kopiert man zwischen aufeinanderfolgenden
Zeitschritten die Ausgaben eines solchermaßen trainierten
Netzwerkes zurück auf seine Eingabeknoten.
Selbstverständlich lassen sich auf diese Weise niemals über mehr als
einen Zeitschritt reichenden temporalen Abhängigkeiten
erreichen: Die Ausgabe zur Zeit 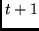 ist durch die Ausgabe zur
Zeit
ist durch die Ausgabe zur
Zeit  vollständig determiniert.
vollständig determiniert.
Keinen qualitativen Fortschritt erzielt man,
wenn man `Zeitfenster' in der Eingabe
zuläßt.
(Eine ganze Reihe von Ansätzen zur temporalen Mustererkennung
beruht auf dem
Zeitfensterprinzip (manchmal läuft es auch unter einem
anderen Namen wie z.B. `distribution
of delays' [13]).)
Zeitfenster erfordern, die Menge der Eingabeknoten
aufzublähen und Eingaben aus den jeweils
letzten 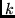 Zeitschritten für die Generierung von Ausgaben zu
verwenden. Solch ein Vorgehen kann sich als nützlich erweisen,
wenn bekannt ist, daß man wirklich nie mehr als vergangene Zeitschritte
berücksichtigen muß, um korrekte Ausgaben zu erzielen.
Selbst in diesem Fall wird die Methode jedoch in der Regel ineffizient sein.
Für den allgemeinen Fall bietet sie keine Perspektive.
Zeitschritten für die Generierung von Ausgaben zu
verwenden. Solch ein Vorgehen kann sich als nützlich erweisen,
wenn bekannt ist, daß man wirklich nie mehr als vergangene Zeitschritte
berücksichtigen muß, um korrekte Ausgaben zu erzielen.
Selbst in diesem Fall wird die Methode jedoch in der Regel ineffizient sein.
Für den allgemeinen Fall bietet sie keine Perspektive.
Nächste Seite: Interne Rückkopplung: Dynamische Netzwerke
Aufwärts: Statische Netzwerke
Vorherige Seite: Statische Netzwerke mit interner
Inhalt
Juergen Schmidhuber
2003-02-20
Related links in English: Recurrent neural networks - Subgoal learning - Reinforcement learning and POMDPs - Reinforcement learning economies - Selective attention
Deutsche Heimseite