


Next: AUTO-ENCODERS
Up: ALTERNATIVE DEFINITIONS OF
Previous: ALTERNATIVE DEFINITIONS OF
We write
![\begin{displaymath}
D_l = - \frac{1}{2} \sum_p \sum_i (y^{p,l}_i- \bar{y_i}^l)^2
+ \frac{\lambda}{2} \sum_i [ \frac{1}{q} - \bar{y_i}^l]^2
\end{displaymath}](img22.png) |
(5) |
and minimize  subject to the
constraint
subject to the
constraint
 |
(6) |
Here, as well as throughout the remainder of this paper,
subscripts of symbols denoting vectors denote vector components:
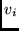 denotes the
denotes the  -th element of some vector
-th element of some vector 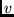 .
.
 is a positive constant, and
is a positive constant, and
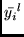 denotes the mean of the -th output unit of
denotes the mean of the -th output unit of 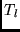 .
It is possible to show that
the first term on the right hand side of
(5) is maximized subject to (6) if each input pattern is locally
represented (just like with winner-take-all networks) by exactly
one corner of the
.
It is possible to show that
the first term on the right hand side of
(5) is maximized subject to (6) if each input pattern is locally
represented (just like with winner-take-all networks) by exactly
one corner of the 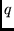 -dimensional hypercube spanned
by the possible output vectors, if there are sufficient
output units [Prelinger, 1992]
2.
Maximizing the second negative term
encourages each local class representation to
become active in response to only
-dimensional hypercube spanned
by the possible output vectors, if there are sufficient
output units [Prelinger, 1992]
2.
Maximizing the second negative term
encourages each local class representation to
become active in response to only
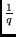 -th of all possible input patterns.
-th of all possible input patterns.
Constraint (6) is enforced by setting
where 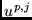 is the activation vector
(in response to
is the activation vector
(in response to 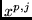 ) of a -dimensional layer
of hidden units of
) of a -dimensional layer
of hidden units of 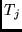 which can be considered as
its unnormalized output layer.
which can be considered as
its unnormalized output layer.
This novel method is easy to implement -
it achieves an effect similar to the one of the recent
entropy-based method by
Bridle and MacKay (1992).
Next: AUTO-ENCODERS
Up: ALTERNATIVE DEFINITIONS OF
Previous: ALTERNATIVE DEFINITIONS OF
Juergen Schmidhuber
2003-02-13
