Many neural net systems (e.g. for control, time series prediction, etc.) rely on adaptive submodules for learning to predict patterns from other patterns. Perfect prediction, however, is often inherently impossible. In this paper we study the problem of finding pattern classifications such that the classes are predictable, while still being as specific as possible.
To grasp the basic idea, let us discuss several examples.
Example 1: Hearing the first two words of a sentence ``Henrietta eats ..." allows you to infer that the third word probably indicates something to eat but you cannot tell what. The class of the third word is predictable from the previous words - the particular instance of the class is not. The class ``food" is not only predictable but also non-trivial and specific in the sense that it does not include everything - ``John", for instance, is not an instance of ``food".
The problem is to classify patterns from a set of training examples such that the classes are both predictable and not too general. A general solution to this problem would be useful for discovering higher level structure in sentences generated by unknown grammars, for instance. Another application would be the unsupervised classification of different pattern instances belonging to the same class, as will be seen in the next example.
Example 2 (stereo task; due to Becker and Hinton, 1989): There are two binary images called the `left' image and the `right' image. Each image consists of two `strips' - each strip being a binary vector. The right image is purely random. The left image is generated from the right image by choosing, at random, a single global shift to be applied to each strip of the right image. An input pattern is generated by concatenating a strip from the right image with the corresponding strip from the left image. ``So the input can be interpreted as a fronto-parallel surface at an integer depth. The only local property that is invariant across space is the depth (i.e. shift)." [Becker and Hinton, 1989]. With a given pair of different input patterns, the task is to extract a non-trivial classification of whatever is common to both patterns - which happens to be the stereoscopic shift.
Example 1 is an instance of the so-called asymmetric case: There we are interested in a predictable non-trivial classification of one pattern (the third word), given some other patterns (the previous words). Example 2 is an instance of the so-called symmetric case: There we are interested in the non-trivial common properties of two patterns from the same class.
In its simplest form,
our basic approach to unsupervised discovery of predictable
classifications is based on two neural networks called
![]() and
and ![]() .
Both can be implemented as standard back-prop networks
[Werbos, 1974][LeCun, 1985][Parker, 1985][Rumelhart et al., 1986].
With a given pair of input patterns,
.
Both can be implemented as standard back-prop networks
[Werbos, 1974][LeCun, 1985][Parker, 1985][Rumelhart et al., 1986].
With a given pair of input patterns, ![]() sees
the first pattern,
sees
the first pattern, ![]() sees the second pattern.
Let us first focus on the asymmetric case.
For instance, with the example 1 above
sees the second pattern.
Let us first focus on the asymmetric case.
For instance, with the example 1 above
![]() may see a representation of the words "Henrietta eats", while
may see a representation of the words "Henrietta eats", while
![]() may see a representation of the word "vegetables".
may see a representation of the word "vegetables".
![]() 's task is
to classify its input.
's task is
to classify its input. ![]() 's task is not to predict
's task is not to predict
![]() 's raw environmental input but to predict
's raw environmental input but to predict ![]() 's output instead.
's output instead.
Both networks have ![]() output units.
Let
output units.
Let
![]() index the input patterns.
index the input patterns.
![]() produces as an output the
classification
produces as an output the
classification
![]() in response to an input vector
in response to an input vector
![]() .
. ![]() 's output in response to its
input vector
's output in response to its
input vector ![]() is the
prediction
is the
prediction
![]() of the current classification
of the current classification
![]() emitted by
emitted by ![]() .
.
We have two conflicting goals which in general are not simultaneously
satisfiable: (A) All predictions ![]() should
match the corresponding classifications
should
match the corresponding classifications ![]() .
(B) The
.
(B) The ![]() should be discriminative -
different inputs
should be discriminative -
different inputs ![]() should lead to different classifications
should lead to different classifications
![]() .
.
We express the trade-off between (A) and (B) by means of two opposing costs.
(A) is expressed by an error term ![]() (for `Match'):
(for `Match'):
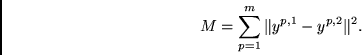 |
(1) |
(B) is enforced by an additional error term
![]() (for `Discrimination')
to be minimized by
(for `Discrimination')
to be minimized by ![]() only.
only.
![]() will be designed to encourage significant
Euclidean distance between classifications of different
input patterns.
will be designed to encourage significant
Euclidean distance between classifications of different
input patterns. ![]() can be defined
in more than one reasonable
way. The next section will list four
alternative possibilities with mutual advantages and disadvantages.
These alternatives include
(a) a novel method for constrained variance maximization,
(b) auto-encoders,
and (c) a recent technique called "predictability minimization"
[Schmidhuber, 1992].
can be defined
in more than one reasonable
way. The next section will list four
alternative possibilities with mutual advantages and disadvantages.
These alternatives include
(a) a novel method for constrained variance maximization,
(b) auto-encoders,
and (c) a recent technique called "predictability minimization"
[Schmidhuber, 1992].
The total error to be minimized by ![]() is
is
| (2) |
| (3) |
With the symmetric case (see example 2 above),
both ![]() and
and ![]() are naturally treated in
a symmetric manner.
They share the goal of uniquely representing
as many of their input patterns as possible - under the constraint
of emitting equal (and therefore mutually predictable)
classifications in response to
a pair of input patterns. Such classifications represent
whatever abstract properties are common to both patterns of a
typical pair.
For handling such symmetric tasks in a natural manner, we only slightly
modify
are naturally treated in
a symmetric manner.
They share the goal of uniquely representing
as many of their input patterns as possible - under the constraint
of emitting equal (and therefore mutually predictable)
classifications in response to
a pair of input patterns. Such classifications represent
whatever abstract properties are common to both patterns of a
typical pair.
For handling such symmetric tasks in a natural manner, we only slightly
modify ![]() 's error function for the asymmetric case, by
introducing an extra `discriminating' error term
's error function for the asymmetric case, by
introducing an extra `discriminating' error term ![]() for
for ![]() .
Now both
.
Now both ![]() minimize
minimize
| (4) |
The assumption behind our basic approach is that a prediction
that closely (in the Euclidean sense) matches
the corresponding classification
is a nearly accurate prediction.
Likewise, two very similar (in the Euclidean sense) classifications
emitted by a particular network
are assumed to have very similar
`meaning'. It should be mentioned that,
in theory, even the slightest differences between classifications
of different patterns are sufficient to convey all (maximal)
Shannon information about the patterns (assuming noise-free data).
But then close matches between predictions and classifications
could not necessarily be interpreted as accurate predictions.
The alternative designs of ![]() (to be described below), however,
will have the tendency to
emphasize differences between different classifications
by increasing the Euclidean distance between them (sometimes
under certain constraints, see section 2).
There is another reason why this is a reasonable thing to do:
In a typical application, a classifier will function as
a pre-processor for some higher-level network.
We usually do not want higher-level
input representations with different `meaning'
to be separated by tiny Euclidean distance.
(to be described below), however,
will have the tendency to
emphasize differences between different classifications
by increasing the Euclidean distance between them (sometimes
under certain constraints, see section 2).
There is another reason why this is a reasonable thing to do:
In a typical application, a classifier will function as
a pre-processor for some higher-level network.
We usually do not want higher-level
input representations with different `meaning'
to be separated by tiny Euclidean distance.
Weight sharing.
If both ![]() and
and ![]() are supposed to provide the same outputs
in response to the same inputs (this holds for
the stereo task but does not hold in
the general case) then we need only one set of weights
for both classifiers. This reduces the number of free parameters
(and may improve generalization performance).
are supposed to provide the same outputs
in response to the same inputs (this holds for
the stereo task but does not hold in
the general case) then we need only one set of weights
for both classifiers. This reduces the number of free parameters
(and may improve generalization performance).
Outline. The current section motivated and explained
our basic approach.
Section 2 presents various instances of the basic approach (based
on various possibilities for defining ![]() ).
Section 3 mentions previous related work.
Section 4 presents illustrative experiments and experimentally
demonstrates advantages of our approach.
).
Section 3 mentions previous related work.
Section 4 presents illustrative experiments and experimentally
demonstrates advantages of our approach.