|
|
|
Since age 15 or so my main scientific ambition has been to
build an
optimal scientist,
then retire. In 2028 they will
force me to retire anyway. By then I shall be able to buy hardware
providing more raw computing power
than my brain. Will the proper self-improving software lag far
behind? If so I'd be surprised. This optimism is driving my
research on mathematically sound, general purpose universal
learning machines
and the
New AI
which is also relevant for
physics.
|
|
RECENT WORK
|
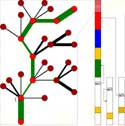 Optimal Ordered Problem Solver.
OOPS solves one
task after another, through
search for solution-computing
programs. The incremental method always optimally exploits solutions
to earlier tasks when possible - compare
principles of
Levin's
optimal universal search
.
OOPS can temporarily rewrite its own search procedure,
efficiently searching for faster search methods
(metasearching or
metalearning
).
It is applicable to problems of optimization or prediction.
Talk slides.
Optimal Ordered Problem Solver.
OOPS solves one
task after another, through
search for solution-computing
programs. The incremental method always optimally exploits solutions
to earlier tasks when possible - compare
principles of
Levin's
optimal universal search
.
OOPS can temporarily rewrite its own search procedure,
efficiently searching for faster search methods
(metasearching or
metalearning
).
It is applicable to problems of optimization or prediction.
Talk slides.
|
 Super Omegas and
Generalizations of
Kolmogorov Complexity and
Algorithmic Probability.
Kolmogorov's (left) complexity K(x) of a
bitstring x is the length of the
shortest program that
computes x and halts.
Solomonoff's
algorithmic probability of
x is the probability of guessing
a program for x.
Chaitin's Omega is
the halting probability
of a Turing machine with random input
(Omega is known as the "number of wisdom" because it
compactly encodes all
mathematical truth).
All of this I generalized to
non-halting but converging
programs. This led to
the shortest possible formal descriptions
and to
non-enumerable
but limit-computable
measures and Super Omegas,
and even has consequences for
computable universes and
optimal
inductive inference.
Slides.
Super Omegas and
Generalizations of
Kolmogorov Complexity and
Algorithmic Probability.
Kolmogorov's (left) complexity K(x) of a
bitstring x is the length of the
shortest program that
computes x and halts.
Solomonoff's
algorithmic probability of
x is the probability of guessing
a program for x.
Chaitin's Omega is
the halting probability
of a Turing machine with random input
(Omega is known as the "number of wisdom" because it
compactly encodes all
mathematical truth).
All of this I generalized to
non-halting but converging
programs. This led to
the shortest possible formal descriptions
and to
non-enumerable
but limit-computable
measures and Super Omegas,
and even has consequences for
computable universes and
optimal
inductive inference.
Slides.
|
Universal Learning Algorithms.
There is a theoretically optimal way of
predicting the future, given the past.
It can be used to define an optimal (though
noncomputable)
rational agent that maximizes
its expected reward in almost arbitrary environments sampled
from computable probability distributions.
This work represents the first mathematically
sound theory of universal artificial intelligence - most
previous work on AI was either heuristic or very limited.
|
 Speed Prior.
Occam's Razor says: prefer simple solutions to complex ones.
But what exactly does "simple" mean?
According to tradition something is simple if
it has a short description or program, that is,
it has low
Kolmogorov complexity.
This leads to
Solomonoff's & Levin's
miraculous
probability measure which yields optimal
though noncomputable predictions,
given past observations.
The
Speed Prior
is different though: it is a new simplicity measure
based on the fastest way of describing
objects, not the shortest.
Unlike the traditional one,
it leads to near-optimal computable predictions,
and provokes unusual prophecies
concerning the future of our universe.
Talk slides.
Speed Prior.
Occam's Razor says: prefer simple solutions to complex ones.
But what exactly does "simple" mean?
According to tradition something is simple if
it has a short description or program, that is,
it has low
Kolmogorov complexity.
This leads to
Solomonoff's & Levin's
miraculous
probability measure which yields optimal
though noncomputable predictions,
given past observations.
The
Speed Prior
is different though: it is a new simplicity measure
based on the fastest way of describing
objects, not the shortest.
Unlike the traditional one,
it leads to near-optimal computable predictions,
and provokes unusual prophecies
concerning the future of our universe.
Talk slides.
|
 In the Beginning was the Code!
In 1997 I founded the
Religion of the Great Programmer
In the Beginning was the Code!
In 1997 I founded the
Religion of the Great Programmer
 consistent with
Zuse's
thesis
(1967)
of the computable universe,
against which
there is no physical evidence,
contrary to common belief.
If everything is computable, then
which exactly is our
universe's program? It turns out
that the simplest program
computes
all computable universes,
not just ours.
Later work (2000) on
Algorithmic Theories of Everything
analyzed all the
universes with limit-computable probabilities
as well as the very limits of formal describability.
This paper led to above-mentioned
generalizations of
algorithmic information and
probability and
Super Omegas
as well as the
Speed Prior.
The searchable
"everything" mailing list archive
contains numerous discussions of this and related work
(see also comments on Wolfram's
2002 book).
Talk slides.
consistent with
Zuse's
thesis
(1967)
of the computable universe,
against which
there is no physical evidence,
contrary to common belief.
If everything is computable, then
which exactly is our
universe's program? It turns out
that the simplest program
computes
all computable universes,
not just ours.
Later work (2000) on
Algorithmic Theories of Everything
analyzed all the
universes with limit-computable probabilities
as well as the very limits of formal describability.
This paper led to above-mentioned
generalizations of
algorithmic information and
probability and
Super Omegas
as well as the
Speed Prior.
The searchable
"everything" mailing list archive
contains numerous discussions of this and related work
(see also comments on Wolfram's
2002 book).
Talk slides.
|
 State-of-the-art Artificial Recurrent Neural Networks.
Most work in machine learning focuses on machines
with reactive
behavior. RNNs, however, are more general sequence processors
inspired by human brains. They have adaptive
feedback connections and are
in principle as powerful as any computer.
Until recently, however, RNNs could not learn to look far
back into the past. But our novel RNN called "Long Short-Term
Memory" (LSTM) overcomes the fundamental problems of traditional
RNNs, and efficiently learns to solve many previously unlearnable tasks,
including: Recognition of certain context sensitive languages;
Reinforcement learning in partially observable environments;
Metalearning of fast online learning algorithms;
Music composition.
Tutorial slides.
State-of-the-art Artificial Recurrent Neural Networks.
Most work in machine learning focuses on machines
with reactive
behavior. RNNs, however, are more general sequence processors
inspired by human brains. They have adaptive
feedback connections and are
in principle as powerful as any computer.
Until recently, however, RNNs could not learn to look far
back into the past. But our novel RNN called "Long Short-Term
Memory" (LSTM) overcomes the fundamental problems of traditional
RNNs, and efficiently learns to solve many previously unlearnable tasks,
including: Recognition of certain context sensitive languages;
Reinforcement learning in partially observable environments;
Metalearning of fast online learning algorithms;
Music composition.
Tutorial slides.
|
 Reinforcement Learning
in partially observable environments.
Reinforcement Learning
in partially observable environments.
Just like humans, reinforcement learners are supposed to
maximize expected pleasure and
minimize expected pain. Most traditional work is limited to
reactive mappings from sensory inputs to actions.
Our approaches for
partially observable environments
are more general: they learn how to
use memory and internal states.
The
first universal reinforcement learner
is optimal if we ignore computation time,
and we are trying to make one that is optimal
if we don't.
|
 Learning Robots.
Some hardwired robots achieve impressive feats.
But they do not learn like babies do.
Unfortunately, traditional
reinforcement learning algorithms
are limited to simple reactive behavior and do not
work well for realistic robots.
Hence robots must use novel methods for
learning to identify important past events
and memorize them until needed.
We are focusing on
our above-mentioned
recurrent neural networks
and the
Optimal Ordered Problem Solver.
We are collaborating with
CSEM
on attentive sensing and
hierarchical control.
Learning Robots.
Some hardwired robots achieve impressive feats.
But they do not learn like babies do.
Unfortunately, traditional
reinforcement learning algorithms
are limited to simple reactive behavior and do not
work well for realistic robots.
Hence robots must use novel methods for
learning to identify important past events
and memorize them until needed.
We are focusing on
our above-mentioned
recurrent neural networks
and the
Optimal Ordered Problem Solver.
We are collaborating with
CSEM
on attentive sensing and
hierarchical control.
|
|
 |
|
OLDIES BUT GOODIES
|
|
Nonlinear Independent Component Analysis (ICA).
Pattern recognition works better on nonredundant
data with independent components. My
Predictability Minimization
(1992) was the first non-linear
neural algorithm for learning to encode redundant inputs in this way.
It is based on co-evolution of predictors and
feature detectors
that fight each other: the
detectors
try to extract features
that make them unpredictable.
My neural
history compressors
(1991) compactly encode
sequential data. And
Lococode
unifies regularization
and unsupervised learning.
|
Financial Forecasting.
Our most lucrative neural network application
employs a
second-order method
for finding the
simplest model of stock market training data.
|
Metalearning Machines - Learning to Learn - Self-Improvement.
Can we construct metalearning algorithms that learn better
learning algorithms? This question has been a main drive of
my research since my 1987
diploma thesis.
In 1993 I introduced
self-referential weight matrices, and in
1994
self-modifying policies trained by the
"success-story algorithm"
(talk slides). My first
time-optimal self-improving metalearner, however,
is the above-mentioned
Optimal Ordered Problem Solver (2002).
|
Reinforcement Learning Economies with Credit Conservation.
In the late 1980s I developed the first credit-conserving
machine learning system based on market
principles, and also the
first neural one.
|
Automatic Subgoal Generators - Hierarchical Learning.
There is no teacher providing useful intermediate subgoals
for our reinforcement learning systems. In the early 1990s
we introduced both
gradient-based
( pictures )
and
discrete
adaptive subgoal generators.
|
Program Evolution & Genetic Programming.
As an undergrad I used Genetic Algorithms to evolve computer
programs on a Symbolics LISP machine at
SIEMENS AG.
Two years
later this was still novel:
In 1987 we published
world's 2nd paper
on "Genetic Programming"
(the first was Cramer's in 1985)
and the
first on
Meta-GP.
|
Interestingness & Active Exploration.
My
learning agents
like to go where they
expect to learn
something.
They lose interest in both predictable and unpredictable things.
|
Learning attentive vision.
Humans and other biological systems use sequential gaze shifts for
pattern recognition. This can be much more efficient than
fully parallel approaches to vision. In 1990 we built an
artificial fovea controlled by an adaptive neural controller. Without
a teacher, it learns to find targets
in a visual scene, and to track moving targets.
|
Complexity-Based Theory of Beauty.
In 1997 I claimed: among several patterns classified as "comparable"
by some subjective observer, the subjectively most beautiful
is the one with the simplest description, given the
observer's particular method for encoding and memorizing it.
Exemplary applications include
low-complexity faces
and
Low-Complexity Art.
|
Neural Heat Exchanger.
Like a physical heat exchanger,
but with neurons instead of liquid.
|
Fast weights
instead of recurrent nets.
More
fast weights.
|
Artificial Ants.
IDSIA's Artificial Ant Algorithms are multiagent
optimizers that use local search techniques
and communicate via artificial
pheromones that evaporate over time. They broke several important
benchmark world records. This work got numerous
reviews in journals such as
Nature, Science, Scientific American, TIME,
NY Times, Spiegel, etc. It led to an IDSIA
spin-off company called
ANTOPTIMA.
|
|
|
 Low-Complexity Art.
In 1997 I introduced this
computer-age equivalent of minimal art in the journal "Leonardo."
A low-complexity artwork can be specified by a short
computer algorithm. It should "look right," its
algorithmic complexity
should be small,
and a typical observer should be able to see
and understand its
simplicity.
This inspired a
complexity-based theory of beauty.
Low-Complexity Art.
In 1997 I introduced this
computer-age equivalent of minimal art in the journal "Leonardo."
A low-complexity artwork can be specified by a short
computer algorithm. It should "look right," its
algorithmic complexity
should be small,
and a typical observer should be able to see
and understand its
simplicity.
This inspired a
complexity-based theory of beauty.
|
|
 Lego Art.
Did you know that one can make stable rings and other
curved objects from rectangular
LEGO elements only?
Lego Art.
Did you know that one can make stable rings and other
curved objects from rectangular
LEGO elements only?
|
|







 Sculptures.
Sculptures.
 Pictures of self- improving robots:
Pictures of self- improving robots:


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}