


Next: WHY NOT USE A
Up: HOW TO USE THE
Previous: ARITHMETIC CODING
The information in the compressed file
is sufficient to reconstruct the original file without loss
of information.
This is done with the ``uncompress'' algorithm, which works
as follows:
Again, for each character 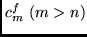 ,
the predictor (sequentially) emits its output
,
the predictor (sequentially) emits its output
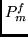 based on the
based on the 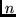 previous characters,
where the
previous characters,
where the 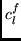 with
with 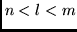 were gained sequentially
by feeding the approximations
were gained sequentially
by feeding the approximations
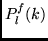 of the probabilities
of the probabilities
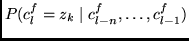 into the inverse Huffman Coding procedure
(see e.g. [1]), or, alternatively (depending on which
coding procedure was used),
into the inverse Arithmetic Coding procedure
( e.g. [7]).
Both variants allow for correct decoding of
from
into the inverse Huffman Coding procedure
(see e.g. [1]), or, alternatively (depending on which
coding procedure was used),
into the inverse Arithmetic Coding procedure
( e.g. [7]).
Both variants allow for correct decoding of
from 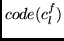 .
With both variants,
to correctly decode
some character, we first need to decode all
previous characters.
Both variants are guaranteed to restore
the original file from the compressed file.
.
With both variants,
to correctly decode
some character, we first need to decode all
previous characters.
Both variants are guaranteed to restore
the original file from the compressed file.
Subsections
Juergen Schmidhuber
2003-02-25