The RTRL
algorithm for fully recurrent continually running
networks [
Robinson and Fallside, 1987][
Williams and Zipser, 1989]
requires
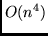
computations per time step,
where
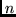
is the number of non-input units. I
describe a method suited for on-line learning which computes exactly
the same gradient and requires
fixed-size storage of the same order
but has an average
time complexity
2per time step of
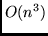
.