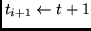POMDP specification.
System life is separable into ``trials''.
A trial consists of at most ![]() discrete time steps
discrete time steps
![]() , where
, where
![]() if the agent solves the problem
in fewer than
if the agent solves the problem
in fewer than ![]() time steps.
A POMDP is specified by
time steps.
A POMDP is specified by ![]()
![]() ,
where
,
where
![]() is a finite
set of environmental states,
is a finite
set of environmental states,
![]() is the initial state,
is the initial state,
![]() is a finite set of observations,
the function
is a finite set of observations,
the function
![]() is a many-to-one mapping of
states to (ambiguous) observations,
is a many-to-one mapping of
states to (ambiguous) observations,
![]() is a finite set of actions,
is a finite set of actions,
![]() maps state-action pairs to scalar
reinforcement signals,
maps state-action pairs to scalar
reinforcement signals,
![]() is a discount factor which trades off
immediate rewards against future rewards, and
is a discount factor which trades off
immediate rewards against future rewards, and
![]() is a state transition function,
where
is a state transition function,
where
![]() denotes the probability of transition to state
denotes the probability of transition to state ![]() given
given ![]() , where
, where ![]() is the environmental state at time
is the environmental state at time ![]() ,
and
,
and ![]() is the action executed at time
is the action executed at time ![]() .
The system's goal is to obtain maximal
(discounted) cumulative reinforcement during the trial.
.
The system's goal is to obtain maximal
(discounted) cumulative reinforcement during the trial.
POMDPs as RPP sequences.
The optimal policy of any deterministic POMDP with
final goal state is decomposable into
a finite sequence of optimal policies for appropriate RPPs,
along with subgoals determining transitions from one RPP to the next.
The trivial decomposition consists of single-state RPPs
and the corresponding subgoals.
In general, POMDPs whose only decomposition is trivial are
hard -- there is no efficient algorithm for solving them.
HQ, however, is aimed at situations that require few transitions
between RPPs. HQ's architecture implements such transitions by passing
control from one RPP-solving subagent to the next.
Architecture.
There is an ordered sequence of ![]() agents
agents
![]() ,
,
![]() ,
...
,
...
![]() ,
each equipped with
a Q-table, an HQ-table, and a
control transfer unit, except for
,
each equipped with
a Q-table, an HQ-table, and a
control transfer unit, except for
![]() ,
which only has a Q-table (see figure 1).
Each agent is responsible for learning part of the system's policy.
Its Q-table represents its local policy for executing an action given
an input. It is given by
a matrix of size
,
which only has a Q-table (see figure 1).
Each agent is responsible for learning part of the system's policy.
Its Q-table represents its local policy for executing an action given
an input. It is given by
a matrix of size
![]() , where
, where ![]() is the
number of different possible observations
and
is the
number of different possible observations
and ![]() the number of possible actions.
the number of possible actions.
![]() denotes
denotes
![]() 's Q-value (utility) of
action
's Q-value (utility) of
action ![]() given observation
given observation ![]() .
The agent's current subgoal is generated with the help of
its HQ-table, a vector with
.
The agent's current subgoal is generated with the help of
its HQ-table, a vector with ![]() elements.
For each possible observation there
is an HQ-table entry representing its estimated value as a subgoal.
elements.
For each possible observation there
is an HQ-table entry representing its estimated value as a subgoal.
![]() denotes
denotes
![]() 's HQ-value (utility) of
selecting
's HQ-value (utility) of
selecting ![]() as its subgoal.
as its subgoal.
The system's current policy is the policy of the
currently active agent.
If
![]() is active at time step
is active at time step ![]() ,
then we will denote this by
,
then we will denote this by
![]() .
The variable
.
The variable ![]() represents the only
kind of short-term memory in the system.
represents the only
kind of short-term memory in the system.
Architecture limitations. The sequential architecture restricts the POMDP types HQ can solve. To see this consider the difference between RL goals of (1) achievement and (2) maintenance. The former refer to single state goals (e.g., find the exit of a maze), the latter to maintaining a desirable state over time (such as keeping a pole balanced). Our current HQ-variant handles achievement goals only. In case of maintenance goals it will eventually run out of agents -- there must be an explicit final desired state (this restriction may be overcome with different agent topologies beyond the scope of this paper).
![]()
Selecting a subgoal.
In the beginning
![]() is
made active.
Once
is
made active.
Once
![]() is active, its HQ-table is used to
select a subgoal for
is active, its HQ-table is used to
select a subgoal for
![]() .
To explore different subgoal sequences
we use the Max-Random rule:
the subgoal with maximal
.
To explore different subgoal sequences
we use the Max-Random rule:
the subgoal with maximal ![]() value is selected with probability
value is selected with probability
![]() , a random subgoal is selected with probability
, a random subgoal is selected with probability ![]() .
Conflicts between
multiple subgoals with maximal
.
Conflicts between
multiple subgoals with maximal ![]() -values
are solved by randomly selecting one.
-values
are solved by randomly selecting one.
![]() denotes the subgoal selected by agent
denotes the subgoal selected by agent
![]() .
This subgoal is only used in transfer of control as defined below and
should not be confused with an observation.
.
This subgoal is only used in transfer of control as defined below and
should not be confused with an observation.
Selecting an action.
![]() 's action choice depends only
on the current observation
's action choice depends only
on the current observation ![]() .
During learning, at time
.
During learning, at time ![]() ,
the active agent
,
the active agent
![]() will select actions
according to the Max-Boltzmann distribution:
with probability
will select actions
according to the Max-Boltzmann distribution:
with probability ![]() take the action
take the action ![]() with maximal
with maximal ![]() value;
with probability
value;
with probability ![]() select an action according to the traditional Boltzmann or Gibbs distribution, where
the probability of selecting action
select an action according to the traditional Boltzmann or Gibbs distribution, where
the probability of selecting action ![]() given observation
given observation ![]() is:
is:
Transfer of control.
Control is transferred from one active agent to the next
as follows.
Each time
![]() has executed an action,
its control transfer unit
checks whether
has executed an action,
its control transfer unit
checks whether
![]() has reached the goal.
If not, it checks whether
has reached the goal.
If not, it checks whether
![]() has solved its subgoal to decide whether control should be passed on to
has solved its subgoal to decide whether control should be passed on to
![]() .
We let
.
We let ![]() denote the time at which
agent
denote the time at which
agent
![]() is made active
(at system start-up, we set
is made active
(at system start-up, we set
![]() ).
).
IF no goal state reached AND current subgoal =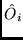
ANDAND
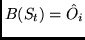
THENAND