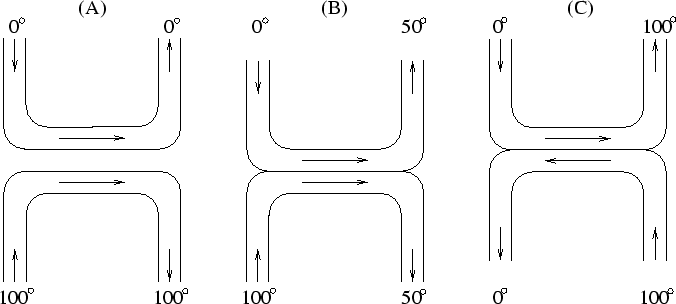
First consider a conventional, physical heat exchanger. See Figure 1 (C). There are two touching water pipes with opposite flow direction. Cold water enters the first pipe. Hot water enters the second pipe. But hot water exits the first pipe, and cold water exits the second pipe! At any given point where both pipes touch, their temperatures are the same (provided the water speed is low enough to allow for sufficient temperature exchange). Entirely local interaction can lead to a complete reversal of global, macroscopic properties such as temperature. Physical heat exchangers are common in technical applications (e.g., nuclear power plants) and animals, e.g., rodents (Geoff Hinton, personal communication, 1994).
 |
Basic idea. In analogy to the physical heat exchanger, I build a ``Neural Heat Exchanger''. There are two multi-layer feedforward networks with opposite flow direction. They correspond to the pipes. Both nets have the same number of layers. They are aligned such that each net's input layer is ``next'' to the other net's output layer, and each hidden layer in the first net is ``next'' to exactly one hidden layer in the other net. Input patterns enter the first net and are propagated ``up''. Desired outputs (targets) enter the ``opposite'' net and are propagated ``down''. Using the local, simple delta rule, each layer in each net tries to be similar (in information content) to the preceding layer and to the corresponding layer in the other net. The input entering the first net slowly ``heats up'' to become the target. The target entering the opposite net slowly ``cools down'' to become the input. No global control mechanism is required. See Figure 2 and details below.
 |
Architecture.
See Figure 2.
The first pipe corresponds to a feedforward network ![]() with n layers
with n layers ![]() ,
, ![]() , ...,
, ..., ![]() .
Each unit in
.
Each unit in ![]() has directed connections to each
unit in
has directed connections to each
unit in ![]() ,
,
![]() .
The second pipe corresponds to a feedforward network
.
The second pipe corresponds to a feedforward network ![]() with n layers
with n layers ![]() ,
, ![]() , ...,
, ..., ![]() .
Each unit in
.
Each unit in ![]() has directed connections to each
unit in
has directed connections to each
unit in ![]() ,
,
![]() .
For simplicity, let all layers have m units.
The
.
For simplicity, let all layers have m units.
The ![]() -th unit in
-th unit in ![]() is denoted
is denoted ![]() .
The
.
The ![]() -th unit in
-th unit in ![]() is denoted
is denoted ![]() .
The randomly initialized weight on the connection
from some unit
.
The randomly initialized weight on the connection
from some unit ![]() to some unit
to some unit ![]() is denoted
is denoted ![]() .
.
Dynamics (example).
See Figure 2.
Input patterns enter ![]() at
at ![]() .
Output patterns exit
.
Output patterns exit ![]() at
at ![]() .
The goal is to make the output patterns like the targets.
.
The goal is to make the output patterns like the targets.
![]() 's flow direction is opposite to
's flow direction is opposite to ![]() 's.
Targets (desired outputs) enter
's.
Targets (desired outputs) enter ![]() at
at ![]() .
Output patterns exit
.
Output patterns exit ![]() at
at ![]() .
The goal is to make the output patterns like
.
The goal is to make the output patterns like ![]() 's inputs.
Input units are those in
's inputs.
Input units are those in ![]() and
and ![]() .
At any given discrete time step,
their activations are set by the environment, according
to the current task.
Furthermore, at any given time,
each noninput unit
.
At any given discrete time step,
their activations are set by the environment, according
to the current task.
Furthermore, at any given time,
each noninput unit ![]() updates its variable activation
updates its variable activation ![]() (initialized
with 0.0) as follows:
with probability
(initialized
with 0.0) as follows:
with probability
![]() , set
, set
![]() ;
with probability
;
with probability
![]() , set
, set
![]() ;
where
;
where
![]() ,
for instance.
,
for instance.
Learning.
At any given discrete time step,
using the simple delta rule (no backprop), weights are
adjusted such that
each noninput unit ![]() reduces its current (expected)
distance to the
corresponding unit
reduces its current (expected)
distance to the
corresponding unit ![]() .
Symmetrically:
each noninput unit
.
Symmetrically:
each noninput unit ![]() reduces its current
distance to the
corresponding unit
reduces its current
distance to the
corresponding unit ![]() .
Why?
Because each layer should
be similar to
(``have the same temperature as'') the
corresponding layer in the net with opposite flow direction.
.
Why?
Because each layer should
be similar to
(``have the same temperature as'') the
corresponding layer in the net with opposite flow direction.
Furthermore,
at any given time step, using the simple delta rule (no backprop), weights are
adjusted such that
each noninput unit
![]() reduces its distance to unit
reduces its distance to unit ![]() . Symmetrically:
each noninput unit
. Symmetrically:
each noninput unit
![]() reduces its distance to
reduces its distance to ![]() .
Why?
Because this tends to make successive units similar --
just like neighboring parts of a physical heat exchanger
have similar temperature.
The target entering
.
Why?
Because this tends to make successive units similar --
just like neighboring parts of a physical heat exchanger
have similar temperature.
The target entering ![]() slowly ``cools down''
to become the input. Likewise,
the input entering
slowly ``cools down''
to become the input. Likewise,
the input entering ![]() slowly ``heats up'' to become the target.
slowly ``heats up'' to become the target.
Clearly, each weight gets error signals from two different local minimization processes. Simply add them up to change the weights.
Variants. The discussion above focused on the case where each layer has the same number of units. This makes it particularly convenient to define what it means for one layer to be similar to the preceding one: each unit's activation simply has to be similar to the one of the unit at the same position in the previous layer. Varying numbers of units per layer require us to refine our notion of layer similarity. For instance, layer similarity can be defined by measuring mutual information between successive layers. Non-probabilistic variants of the Neural Heat Exchanger may sometimes be appropriate as well.
Experiments. Three ETHZ undergrad students, Alberto Salerno, Thomas Fasciania, and Giorgio Pazmandi, recently reimplemented the Neural Heat Exchanger. They report that it was able to solve XOR more quickly than backprop. For larger scale parity problems, however, their system did not work as well as backprop. Sepp Hochreiter (personal communication) also implemented variants of the Neural Heat Exchanger. He learned simple functions such as AND with 5 and more hidden layers. He reports that the system prefers local coding in deep hidden layers. He also successfully tried variants where each layer has different numbers of units, and where either local auto-association or mutual information is used to define layer similarity. Unfortunately, however, at the moment of this writing, there has not yet been a detailed experimental study of the Neural Heat Exchanger. My own, very limited 1990 toy experiments also do not qualify as a systematic analysis. Much remains to be done.
Relation to recent work. According to Peter Dayan (personal communication, 1994), the Neural Heat Exchanger is essentially a supervised variant of the recent Helmholtz Machine [3,2]. Or, depending on the point of view, the Helmholtz Machine is an unsupervised variant of the Neural Heat Exchanger.
According to Peter Dayan and Geoff Hinton [1], a trouble with
the Neural Heat Exchanger is that in non-deterministic domains, there
is no reason why ![]() 's output
should match
's output
should match ![]() 's input. Dayan and Hinton's algorithm
overcomes this problem by using completely separate learning phases
for top-down and bottom-up weights. This, however, makes their algorithm
non-local in time: a global mechanism is required to separate the
learning phases.
's input. Dayan and Hinton's algorithm
overcomes this problem by using completely separate learning phases
for top-down and bottom-up weights. This, however, makes their algorithm
non-local in time: a global mechanism is required to separate the
learning phases.
An alternative way to overcome the problem above
may be to force part of ![]() 's output
to reconstruct a unique representation of
's output
to reconstruct a unique representation of ![]() 's input, and to feed
this representation also into
's input, and to feed
this representation also into ![]() , together with the target.
, together with the target.