



Nächste Seite: DYNAMISCHE VERBINDUNGEN
Aufwärts: VOLLSTÄNDIGE RÜCKKOPPLUNG
Vorherige Seite: ZWEI PROBLEME DER OBIGEN
Inhalt
Wir haben drei Methoden zur Berechnung des exakten Fehlergradienten
für vollständig rekurrente dynamische Netze kennengelernt.
Bei Trainingssequenzen, deren Länge von vornherein als
klein im Verhältnis zur Anzahl der Knoten im Netz bekannt
ist, empfiehlt sich die erste Methode (BPTT). In Fällen,
wo man bisher die zweite Methode (RTRL) bevorzugte, sollte
man tatsächlich das neue dritte komplexere
Verfahren einsetzen,
da es bei gleichem Speicheraufwand
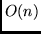 mal schneller ist.
mal schneller ist.
Eine auffallende Eigenschaft der
neuartigen dritten Methode ist, daß sie zwei Größen miteinander
in sinnvolle Beziehung setzt, die auf den ersten Blick nichts
miteinander zu tun haben: Die Anzahl der Knoten im Netzwerk
und die Anzahl der Zeitschritte, die die
Aktivationsausbreitungsphase eines Blocks umfaßt.
Experimente zeigten, daß rekurrente gradientenbasierte
Netze sich zwar zur Lösung interessanter Probleme eignen,
daß sie aber trotz ihrer theoretischen Mächtigkeit
im praktischen Einsatz in Schwierigkeiten geraten
können, wenn lange Zeitverzögerungen zwischen korrelierten
Ereignissen zu überbrücken sind.
Kapitel 7 wird zeigen, wie durch die Einführung zusätzlicher
Performanzmaße für unüberwachtes Lernen die
praktische Lösung des durch die allgemeine Zielfunktion (2.5)
definierten Problems in bestimmten Fällen gewaltig erleichtert werden kann.
Nächste Seite: DYNAMISCHE VERBINDUNGEN
Aufwärts: VOLLSTÄNDIGE RÜCKKOPPLUNG
Vorherige Seite: ZWEI PROBLEME DER OBIGEN
Inhalt
Juergen Schmidhuber
2003-02-20
Related links in English: Recurrent networks - Fast weights - Subgoal learning - Reinforcement learning and POMDPs - Unsupervised learning and ICA - Metalearning and learning to learn
Deutsche Heimseite