


Next: Limitations and Extensions
Up: The Architecture and the
Previous: On-Line Versus Off-Line Learning
An alternative of the method above would be to employ a method similar
to the `unfolding in time'-algorithm for recurrent nets
(e.g. [Rumelhart et al., 1986]).
It is convenient to keep an activation stack for each unit in 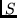 .
At each time step of an episode,
some unit's new activation should be pushed onto its stack. 's output units
should have an additional stack for storing sums of error signals received
over time.
With both (4) and (5),
at each time step we essentially propagate
the error signals obtained at 's output units down
to the input units.
The final weight change
of
.
At each time step of an episode,
some unit's new activation should be pushed onto its stack. 's output units
should have an additional stack for storing sums of error signals received
over time.
With both (4) and (5),
at each time step we essentially propagate
the error signals obtained at 's output units down
to the input units.
The final weight change
of 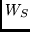 is proportional to
the sum of all contributions of all errors observed during one
episode.
The complete gradient for is computed at the end of each episode by
successively popping off the stacks of error signals and activations
analogously to the `unfolding in time'-algorithm for
recurrent networks. A disadvantage of the method is that it is
not local
in space.
is proportional to
the sum of all contributions of all errors observed during one
episode.
The complete gradient for is computed at the end of each episode by
successively popping off the stacks of error signals and activations
analogously to the `unfolding in time'-algorithm for
recurrent networks. A disadvantage of the method is that it is
not local
in space.
Juergen Schmidhuber
2003-02-13
Back to Recurrent Neural Networks page