


Next: EXPERIMENTS
Up: CURIOUS MODEL-BUILDING CONTROL SYSTEMS
Previous: A CURIOUS SYSTEM BASED
The reinforcement generating mechanism
for the reinforcement learning systems described above can be modified in
various ways. For instance,
define 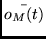 as
as 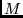 's response to
's response to 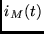 after having
adjusted at time
after having
adjusted at time 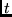 .
We can replace the confidence network by
a network
.
We can replace the confidence network by
a network 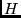 which at every time step receives the current input
and whose target output
is the current change of 's output
which at every time step receives the current input
and whose target output
is the current change of 's output
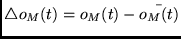 caused by 's learning algorithm ( should have a small
learning rate).
will learn
approximations of the expectations
caused by 's learning algorithm ( should have a small
learning rate).
will learn
approximations of the expectations
of the changes of 's responses to
given inputs. The absolute value
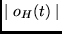 of 's output
of 's output 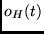 (an approximation
of
(an approximation
of
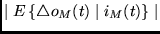 )
should be taken as the reinforcement for the adaptive critic or
the Q-learning algorithm (the reinforcement
learning algorithm does not have to be specified here):
The control system's
curiosity goal
at time
)
should be taken as the reinforcement for the adaptive critic or
the Q-learning algorithm (the reinforcement
learning algorithm does not have to be specified here):
The control system's
curiosity goal
at time 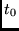 is to maximize
is to maximize
where
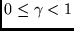 is a discount rate.
An alternative would be to make predictions about the
(discounted) sum of future
changes of 's weight vector and use these predictions in an
analoguous manner.
is a discount rate.
An alternative would be to make predictions about the
(discounted) sum of future
changes of 's weight vector and use these predictions in an
analoguous manner.
Next: EXPERIMENTS
Up: CURIOUS MODEL-BUILDING CONTROL SYSTEMS
Previous: A CURIOUS SYSTEM BASED
Juergen Schmidhuber
2003-02-28
Back to Active Learning - Exploration - Curiosity page
Back to Reinforcement Learning page