


Next: 3. SIMULATIONS OF RDIA
Up: REINFORCEMENT DRIVEN INFORMATION ACQUISITION
Previous: 1. INTRODUCTION
Our agent's task is to build a model of the transition
probabilities 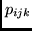 .
The problem is studied in isolation from goal-directed
reinforcement learning tasks:
RDIA embodies a kind of ``unsupervised
reinforcement learning''.
It extends recent previous work on ``active exploration''
(e.g. [9,8,11]).
Previous approaches (1) were limited
to deterministic environments (they did not address
the general problem of learning a
model of the statistical properties of a non-deterministic NME),
and (2) were based
on ad-hoc elements instead of building
on concepts from information theory.
.
The problem is studied in isolation from goal-directed
reinforcement learning tasks:
RDIA embodies a kind of ``unsupervised
reinforcement learning''.
It extends recent previous work on ``active exploration''
(e.g. [9,8,11]).
Previous approaches (1) were limited
to deterministic environments (they did not address
the general problem of learning a
model of the statistical properties of a non-deterministic NME),
and (2) were based
on ad-hoc elements instead of building
on concepts from information theory.
Collecting ML estimates.
For each state/action pair (or experiment)
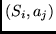 , the
agent has a counter
, the
agent has a counter 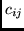 whose value at time
whose value at time 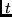 ,
,
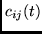 , equals the number of the agent's previous experiences
with .
In addition, for each state/action pair , there
are
, equals the number of the agent's previous experiences
with .
In addition, for each state/action pair , there
are 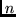 counters
counters 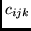 ,
, 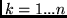 . The value
of at time ,
. The value
of at time ,
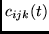 , equals the number of the agent's previous experiences
with , where the next state was
, equals the number of the agent's previous experiences
with , where the next state was 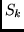 .
Note that
.
Note that
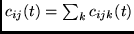 .
At time , if
.
At time , if 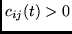 , then
, then
denotes the agent's current unbiased estimate of .
If 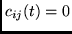 , then we define (somewhat arbitrarily)
, then we define (somewhat arbitrarily)
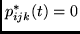 . Note that, as a consequence, before the agent
has conducted any experiments of the type ,
the
. Note that, as a consequence, before the agent
has conducted any experiments of the type ,
the 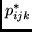 do not satisfy the requirements of
a probability distribution. For ,
the
do not satisfy the requirements of
a probability distribution. For ,
the 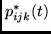 build a maximum likelihood model (consistent with the previous
experiences of the agent)
of the probabilities of the possible next states.
build a maximum likelihood model (consistent with the previous
experiences of the agent)
of the probabilities of the possible next states.
Measuring information gain.
If the agent performs an experiment by executing
action 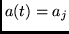 in state
in state 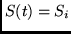 , and the new state
is
, and the new state
is 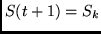 ,
then in general will be different from
,
then in general will be different from
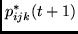 .
By observing the outcome of the experiment, the agent has
acquired a piece of information.
To measure its progress,
we compute the
information theoretic
difference between what the agent knew before
the experiment, at time , and what the agent knew after
the experiment, at time
.
By observing the outcome of the experiment, the agent has
acquired a piece of information.
To measure its progress,
we compute the
information theoretic
difference between what the agent knew before
the experiment, at time , and what the agent knew after
the experiment, at time 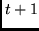 .
One natural way of doing this is to use the
Kullback-Leibler distance (or asymmetric divergence)
between the probability distributions represented
by the and
.
We define
.
One natural way of doing this is to use the
Kullback-Leibler distance (or asymmetric divergence)
between the probability distributions represented
by the and
.
We define
 |
(1) |
where
A related (but less informative)
measure of progress is the entropy difference of
the probability distributions represented
by the and
,
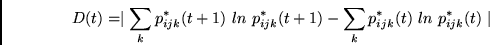 |
(2) |
for .
Again, if (before the agent
has conducted any experiments of type ),
the entropy of the corresponding MLM
is taken to be zero.
In this case, 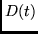 will be zero, too.
Another simple, related performance measure is
will be zero, too.
Another simple, related performance measure is
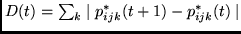 for , and
for , and 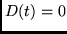 for .
Initial experiments seem to indicate that the particular definition
of does not make an essential difference.
for .
Initial experiments seem to indicate that the particular definition
of does not make an essential difference.
In all cases, best policies are found by
using as the reinforcement 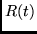 for the Q-Learning algorithm from section 2.
Since an experiment at time affects only
estimates (the
associated with
for the Q-Learning algorithm from section 2.
Since an experiment at time affects only
estimates (the
associated with
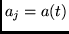 and
and 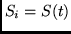 ),
and since can always be computed within
),
and since can always be computed within
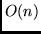 operations,
the algorithm's overall complexity per time step is bounded by
.
operations,
the algorithm's overall complexity per time step is bounded by
.
Next: 3. SIMULATIONS OF RDIA
Up: REINFORCEMENT DRIVEN INFORMATION ACQUISITION
Previous: 1. INTRODUCTION
Juergen Schmidhuber
2003-02-28
Back to Active Learning - Exploration - Curiosity page
Back to Reinforcement Learning page