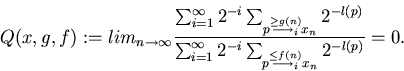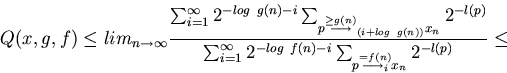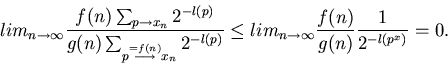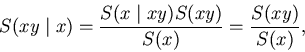Given S, as we observe an initial segment
of some string,
which is the most likely continuation?
Consider x's finite continuations
.
According to Bayes (compare Equation (15)),
(48)
where
is the measure of z2, given z1.
Having observed x we will predict those y that maximize
.
Which are those? In what follows,
we will confirm the intuition that
for
the
only probable continuations of xn are those with fast
programs. The sheer number of ``slowly''
computable strings cannot balance the speed advantage
of ``more quickly'' computable strings with equal beginnings.
Definition 6.4 (tex2html_wrap_inline$p < k_i x$ etc.)
Write
if
finite program p ()
computes x within
less than k steps, and
if it does so within PHASE i of FAST.
Similarly for
and
(at most k steps),
,
(exactly k steps),
,
(at least k steps),
(more than k steps).
Theorem 6.1
Suppose
is S-describable, and
outputs xn within at most f(n) steps for all n,
and
g(n) > O(f(n)).
Then
Proof. Since no program that requires at least g(n) steps for producing
xn can compute xn in a phase with number
< logg(n), we have
Here we have used the Kraft inequality [#!Kraft:49!#]
to obtain a rough upper bound for the enumerator:
when no p is prefix of another one, then
Hence, if we know a rather fast
finite program px for x, then Theorem 6.1 allows for predicting:
if we observe some xn (n sufficiently large) then
it is very unlikely that it was produced by an x-computing algorithm
much slower than px.
Among the fastest algorithms for x is FAST itself, which is
at least as fast as px, save for a constant factor. It outputs
xn after
O(2Kt(xn)) steps. Therefore Theorem 6.1 tells us:
Corollary 6.1
Let
be S-describable.
For
,
with probability 1 the
continuation of xn
is computable within
O(2Kt(xn)) steps.
Given observation x with
,
we
predict a continuation y with minimal Kt(xy).
Example 6.1
Consider
Example 1.2 and Equation (1).
According to the weak anthropic principle,
the conditional probability of a particular observer finding herself
in one of the universes compatible with her existence equals 1.
Given S, we predict a universe with minimal Kt.
Short futures are more likely than long ones: the probability
that the universe's history so far will extend beyond the one computable
in the current phase of FAST (that is, it will be prolongated into
the next phase) is at most 50 %. Infinite futures have measure zero.
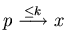 and
and
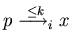 (at most k steps),
(at most k steps),
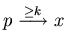 ,
(at least k steps),
,
(at least k steps),