Details der Wagen/Stab Simulation
Das in den Kapiteln 4, 5, und 6 verwendete physikalische Wagen/Stab-System wurde durch folgende Differentialgleichungen modelliert:
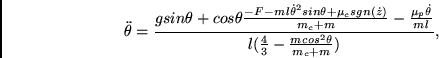
Dabei ist
![]() der Winkel des Stabes mit der Vertikalen,
der Winkel des Stabes mit der Vertikalen,
![]() die Position des Wagens auf der Spur,
die Position des Wagens auf der Spur,
![]() die Gravitationsbeschleunigung,
die Gravitationsbeschleunigung,
![]() die Masse des Wagens,
die Masse des Wagens,
![]() die Masse des Stabes,
die Masse des Stabes,
![]() die halbe Stablänge,
die halbe Stablänge,
![]() der Reibungskoeffizient des Wagens auf der Bahn,
der Reibungskoeffizient des Wagens auf der Bahn,
![]() der Reibungskoeffizient des Stabes auf dem Wagen,
der Reibungskoeffizient des Stabes auf dem Wagen,
![]() bzw.
bzw.
![]() für A1
bzw. für A2
die auf den Schwerpunkt
des Wagens parallel
zur Spur ausgeübte Kraft. (Man beachte, daß die in
[5],
[66] und
[2] angegebenen Gleichungen einen Tippfehler enthalten:
Dort wurde die Gravitationsbeschleunigung jeweils als
für A1
bzw. für A2
die auf den Schwerpunkt
des Wagens parallel
zur Spur ausgeübte Kraft. (Man beachte, daß die in
[5],
[66] und
[2] angegebenen Gleichungen einen Tippfehler enthalten:
Dort wurde die Gravitationsbeschleunigung jeweils als
![]() definiert.)
definiert.)
Für A1 und A3 wurden u. a. folgende
skalierte Eingabevariablen verwendet:
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Für den modifizierten A2 gab es nur die
beiden skalierten Eingabevariablen ![]() und
und ![]() .
.
Weite Sprünge durch den Gewichtsraum
im Falle spärlicher Codierung
Was uns beim Gradientenabstieg (siehe das Kapitel zum überwachten Lernen)
wirklich interessiert, sind nicht so sehr die Minima,
sondern die Nullstellen der Fehlerfunktion
wobei
![]() der komplette Gewichtsvektor des Netzes
ist. Gradientenabstieg erfordert eine Gewichtsänderung
der komplette Gewichtsvektor des Netzes
ist. Gradientenabstieg erfordert eine Gewichtsänderung
wobei ![]() eine positive Lernrate ist. Was wir brauchen, ist
eine gute Wahl für
eine positive Lernrate ist. Was wir brauchen, ist
eine gute Wahl für
![]() . Wir berechnen
. Wir berechnen ![]() für jede Musterpräsentation neu, so
daß der geänderte Gewichtsvektor
für jede Musterpräsentation neu, so
daß der geänderte Gewichtsvektor
auf den Schnitt der ![]() -dimensionalen Gewichtshyperebene (im
-dimensionalen Gewichtshyperebene (im
![]() -dimensionalen Gewichts-Fehler-Raum)
mit der durch den gegenwärtigen Fehler und den gegenwärtigen
Gradienten definierten Geraden zeigt. Die Grundannahme dabei ist,
daß die
-dimensionalen Gewichts-Fehler-Raum)
mit der durch den gegenwärtigen Fehler und den gegenwärtigen
Gradienten definierten Geraden zeigt. Die Grundannahme dabei ist,
daß die ![]() lokal durch die tangentialen Hyperebenen
approximiert werden können.
(Man betrachte Abbildung A.1 für eine Illustration des eindimensionalen
Falles.)
lokal durch die tangentialen Hyperebenen
approximiert werden können.
(Man betrachte Abbildung A.1 für eine Illustration des eindimensionalen
Falles.)
Etwas elementare Geometrie ergibt, daß für ein gegebenes ![]()

gelten muß, wobei
![]() das
das ![]() -te Gewicht ist, und
-te Gewicht ist, und
![]() alle Gewichtsindizes durchläuft. Falls der Gradient verschwindet,
so wird
alle Gewichtsindizes durchläuft. Falls der Gradient verschwindet,
so wird ![]() gleich Null gesetzt. In [49] wird
experimentell an einigen Beispielen gezeigt, daß die Methode
bei spärlicher Codierung zu einer bedeutenden Verringerung der Anzahl
der Lernzyklen führen kann.
gleich Null gesetzt. In [49] wird
experimentell an einigen Beispielen gezeigt, daß die Methode
bei spärlicher Codierung zu einer bedeutenden Verringerung der Anzahl
der Lernzyklen führen kann.