


Next: INFOMAX
Up: ALTERNATIVE DEFINITIONS OF
Previous: MAXIMIZING CONSTRAINED OUTPUT VARIANCE
With pattern 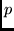 and classifier
and classifier 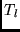 a reconstructor module
a reconstructor module 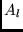 (another back-prop network) receives
(another back-prop network) receives
 as an input.
The combination of and
functions as an auto-encoder. The auto-encoder
is trained to emit the reconstruction
as an input.
The combination of and
functions as an auto-encoder. The auto-encoder
is trained to emit the reconstruction 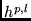 of 's
external input
of 's
external input  , thus forcing
to tell something about
.
, thus forcing
to tell something about
.
 is defined as
is defined as
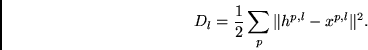 |
(7) |
Juergen Schmidhuber
2003-02-13