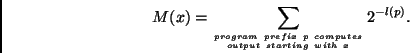Roughly fourty years ago Solomonoff started the theory of
universal optimal induction based on the apparently harmless
simplicity assumption that ![]() is computable [62].
While Equation (1) makes predictions of
the entire future, given the past,
Solomonoff [63] focuses just on the next
bit in a sequence. Although this provokes surprisingly nontrivial
problems associated with translating the bitwise approach to alphabets
other than the binary one -- this was achieved only recently
[20] -- it is sufficient for obtaining essential
insights. Given an observed bitstring
is computable [62].
While Equation (1) makes predictions of
the entire future, given the past,
Solomonoff [63] focuses just on the next
bit in a sequence. Although this provokes surprisingly nontrivial
problems associated with translating the bitwise approach to alphabets
other than the binary one -- this was achieved only recently
[20] -- it is sufficient for obtaining essential
insights. Given an observed bitstring ![]() , Solomonoff assumes the data are drawn
according to a recursive measure
, Solomonoff assumes the data are drawn
according to a recursive measure ![]() ; that is, there is a program for
a universal Turing machine that reads
; that is, there is a program for
a universal Turing machine that reads ![]() and
computes
and
computes ![]() and halts. He estimates the probability of the next bit
(assuming there will be one), using the remarkable, well-studied,
enumerable prior
and halts. He estimates the probability of the next bit
(assuming there will be one), using the remarkable, well-studied,
enumerable prior
![]() [62,77,63,15,31]
[62,77,63,15,31]
| (3) |
Recent Loss Bounds for Universal Prediction.
A more general recent result is this. Assume we do know that
![]() is in some set
is in some set ![]() of distributions. Choose a fixed weight
of distributions. Choose a fixed weight ![]() for each
for each ![]() in
in ![]() such that the
such that the ![]() add up to 1 (for simplicity,
let
add up to 1 (for simplicity,
let ![]() be countable). Then construct the Bayesmix
be countable). Then construct the Bayesmix
![]() , and predict using
, and predict using ![]() instead of the
optimal but unknown
instead of the
optimal but unknown ![]() .
How wrong is it to do that? The recent work of Hutter
provides general and sharp (!) loss bounds [21]:
.
How wrong is it to do that? The recent work of Hutter
provides general and sharp (!) loss bounds [21]:
Let ![]() and
and ![]() be the total expected unit losses of the
be the total expected unit losses of the ![]() -predictor
and the p-predictor, respectively, for the first
-predictor
and the p-predictor, respectively, for the first ![]() events. Then
events. Then
![]() is at most of the order of
is at most of the order of ![]() . That is,
. That is, ![]() is
not much worse than
is
not much worse than ![]() . And in general, no other predictor can do
better than that!
In particular, if
. And in general, no other predictor can do
better than that!
In particular, if ![]() is deterministic, then the
is deterministic, then the ![]() -predictor soon
won't make any errors any more.
-predictor soon
won't make any errors any more.
If ![]() contains all recursively computable distributions, then
contains all recursively computable distributions, then ![]() becomes the celebrated enumerable universal prior. That is, after
decades of somewhat stagnating research we now have sharp loss
bounds for Solomonoff's universal induction
scheme (compare recent work of Merhav and Feder [33]).
becomes the celebrated enumerable universal prior. That is, after
decades of somewhat stagnating research we now have sharp loss
bounds for Solomonoff's universal induction
scheme (compare recent work of Merhav and Feder [33]).
Solomonoff's approach, however, is uncomputable. To obtain a feasible approach, reduce M to what you get if you, say, just add up weighted estimated future finance data probabilities generated by 1000 commercial stock-market prediction software packages. If only one of the probability distributions happens to be close to the true one (but you do not know which) you still should get rich.
Note that the approach is much more general than what is normally done in traditional statistical learning theory, e.g., [69], where the often quite unrealistic assumption is that the observations are statistically independent.