 |
 |
|
|
|
|
|
|
| . |
Jürgen Schmidhuber's
|
. |
 |
Course (1 semester)
MACHINE LEARNING
& OPTIMIZATION I
|

|
|
What you should know for the oral
exams at the end of the semester:
Bayes, ML, MAP,
HMMs, Viterbi, EM,
nonlinear nets, backprop,
max margin, SVMs,
recurrence: BPTT / RTRL / LSTM,
differentiable world models,
Q-learning, TD, POMDPs,
hill-climbing, evolution,
artificial ants,
info theory basics,
unsup. learning,
factorial codes,
SOMs
JS@TUM
|
|
|
General Overview.
We focus on learning agents
interacting with an initially unknown world.
Since the world is dynamic,
unlike many other machine learning courses ours will put
strong emphasis on learning to deal with sequential data:
we do not just want to learn reactive input / output mappings
but programs (running, e.g., on recurrent neural nets)
that perceive, classify, plan, make decisions, etc.
We minimize overlaps with other
TUM courses related to machine learning and bio-inspired optimization.
The lectures cover one semester and represent a ``Wahlpflichtfach.''
The follow-up course
ML & O II
ia a ``Vertiefungsfach''.
Related
"Praktikum".
|
|
|
Course material.
We often use the blackboard and ppt presentations.
In the column below you will find links to supporting material.
Don't worry; you won't have to learn all of this!
During the lectures we will explain
what's really relevant for the oral exams at the end of the semester.
But of course students are encouraged to read more than that!
Thanks to
Andy Moore,
Luca Gambardella,
Marcus Hutter,
Hans Georg Zimmermann (Siemens),
Andy Ng,
for some of the material below.
|
|
|
 |
|
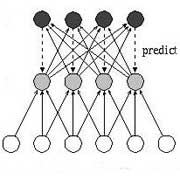
Feedforward Neural Networks.
Early NN research has focused on learning through
gradient descent in feedforward NNs. We will only briefly discuss
the essential concepts and limitations, also to avoid overlap
with other TUM courses such as the
Machine Learning and AI Praktikum, and then focus on world model builders,
info theory and unsupervised learning.
|
|
|
|
 |
|
Support Vector Machines.
SVMs have largely replaced feedforward NNs
in non-sequential classification tasks.
We will briefly discuss
the essential algorithms, minimizing overlap
with other TUM courses such as
Machine Learning
in Bioinformatics.
|
|
|
|
 |
|
Recurrent Neural Networks.
RNNs can implement complex algorithms,
as opposed to the reactive
input / output mappings of feedforward nets and SVMs.
We discuss gradient-based and evolutionary learning algorithms
for RNNs.
|
|
|
 |
 |
|
Evolutionary Computation.
We discuss bio-inspired methods for evolving and optimizing solutions
to problems defined by fitness functions, such as evolutionary strategies and genetic algorithms and adaptive grids, with applications to
recurrent networks and program search.
|
|
|
 |
 |
|
Probabilities, HMMs, EM.
Introduction / repetition: essential concepts of
probability theory and statistics.
Max Likelihood and MAP estimators.
Hidden Markov Models, Viterbi Algorithm,
Expectation Maximization.
|
|
|
|
 |
|
Traditional Reinforcement Learning.
RL is about learning to maximize future reward.
Most traditional RL research focuses on problems that
are solvable by agents with reactive policies that do not
need memories of previous observations.
We discuss the most popular RL methods, their relation to
dynamic programming, and their limitations.
|
|
|
|
 |
|
Artificial Ants.
AAs are are multiagent optimizers that use local search
techniques and communicate via artificial pheromones that
evaporate over time. They achieve state-of-the-art
performance in numerous optimization tasks.
|
|
|
|